
Remarque : ne ratez pas l'article plus récent Knowledge Graph, entités et SEO
Qu'est-ce que le Google Knowledge Graph (KG) ?
En quelques mots, comprenez que Google a fait fortement évoluer son algorithme depuis environ 1 an pour passer d'une analyse par syntagmes (des groupes de mots) à une analyse par entités. Il exploite une masse de connaissances issues de bases de données collaboratives (Wikipédia ou Freebase notamment) mais aussi des Big Data représentées par les recherches des internautes sur Google. Par rapport au lancement, Google est passé de 500 millions à 570 millions entités nommées référencées. Le nombre de faits et relations entre entités a explosé, passant de 3,5 milliards à 18 milliards actuellement. Reste(ra)-t-il quelque chose que Google ignore ?
C'est Amit Singhal qui l'a annoncé officiellement par un article publié sur le blog officiel de Google France : le big boss de Google Search explique les principaux atouts de cette évolution majeure pour la recherche d'information sur Google :
Le “Knowledge Graph” vous permet de chercher et d’obtenir instantanément des informations pertinentes sur des lieux, des bâtiments, des objets, ou des personnes que Google connaît : des monuments célèbres, des personnalités, des villes, des équipes de sports, des films, des objets célestes, des oeuvres d’art, et plus encore. C’est un pas essentiel dans l’avancée vers la recherche en ligne de demain, qui utilise l’intelligence collective du web et dont la compréhension du monde se rapproche un peu plus de celle des individus.
Le Knowledge Graph de Google ne repose pas seulement sur des sources publiques telles que Freebase, Wikipedia, et le CIA World Factbook. Il porte sur une échelle beaucoup plus large, pour apporter toujours plus d’ampleur et de profondeur à la recherche. A ce jour, il contient plus de 500 millions d’entités, ainsi que plus de 3.5 milliards de faits et de relations entre ces différents objets. Et il est ajusté en fonction des recherches des internautes, et de ce que nous découvrons sur Internet.
Selon lui, les 3 principaux atouts du Knowledge Graph pour l'internaute sont :
- faciliter la levée de l'ambiguïté pour des termes qui ont plusieurs sens
- fournir un maximum d'informations sur un sujet sans nécessiter des requêtes supplémentaires
- découvrir de nouvelles choses
Cet affichage est en place progressivement sur les comptes des utilisateurs français, aussi bien sur ordinateurs fixes que sur mobiles et tablettes. Ce système est également déployé en même temps dans les autres langues suivantes : allemand, espagnol, japonais, italien, portugais et russe.
Exemples en images (captures d'écran)
Le Knowledge Graph permet de désambigüiser certains termes :
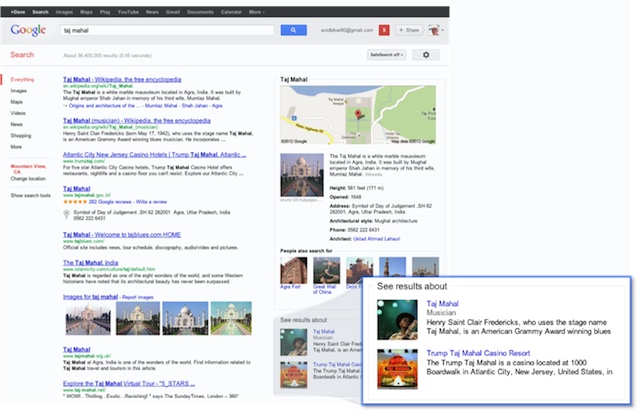
Le Knowledge Graph concentre un grand nombre d'informations sous forme de texte ou d'images :
Sur google.com (interface en anglais), tapez par exemple (sans les crochets qui délimitent la requête) [eiffel tower vs tokyo tower] . Vous obtiendrez au-dessus des résultats traditionnel un tableau issu du Knowledge Graph, listant quelques caractéristiques communes des 2 tours : la hauteur, la date de démarrage de la construction, le nom de l'architecte, le nombre d'étages, la date d'ouverture et la fonction du monument.
Vous verrez avec cette exemple que la fiabilité des données n'est pas encore au rendez-vous : Google ne considère pas que la Tour Eiffel soit une attraction touristique !
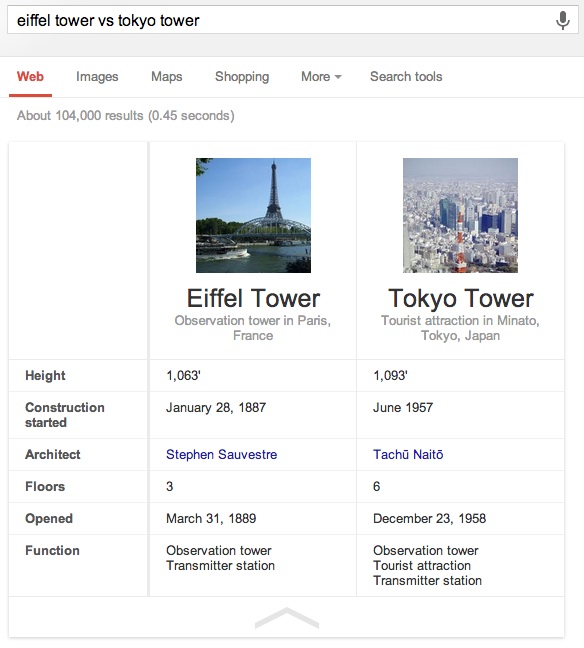
Le challenge est de savoir identifier les caractéristiques de centaines de millions d'entités puis de savoir s'il s'agit réellement de données comparables pour pouvoir afficher un tel tableau. Pour en savoir plus, consultez mon article sur les entités nommées.
Je ne sais pas encore pour quels types de requêtes cela fonctionne. Aidez-moi à trouver d'autres exemples que les bâtiments célèbres, les fleuves ou des denrées alimentaires, les planètes ou des races de chiens !
Le format de votre requête doit inclure "vs" ou "and" et cela semble mieux fonctionner avec le mot "compare" au début.
Pour l'instant cela ne semble fonctionner que pour comparer 2 éléments, pas plus.
Cette nouvelle fonctionnalité du Knowledge Graph fait partie semble-t-il de Hummingbird.
Quel impact pour Google ? Quels sont ses objectifs ?
L'objectif principal de Google est de convaincre les internautes qu'ils doivent continuer à utiliser Google pour faire leurs recherches. L'idée est qu'il faut donner le maximum d'informations à l'internaute, quitte à ce qu'il reste longtemps sur Google et consulte plusieurs pages de résultats. En effet, après une première requête tapée directement par l'internaute (ou dictée !), l'utilisateur aura tendance à cliquer sur les liens proposés dans les encadrés Knowledge Graph. C'est ce qu'observe Google depuis son lancement sur google.com : une forte hausse du nombre de pages vues par internaute. Même s'il s'agit de requêtes indirectes (l'internaute ne les tape plus), l'utilisateur fait davantage de requêtes qu'avant : une sorte d'hyper-recherche comme j'ai lu sur Twitter.
Evidemment, vous aurez compris qu'en voulant garder les internautes plus longtemps sur son site, Google a Facebook en ligne de mire.
Attention : + de requêtes n'est pas forcément synonyme de + de revenus publicitaires pour Google, car - c'est un élément paradoxal majeur - les blocs d'information du knowledge graph s'affichent à l'emplacement habituellement réservé aux publicités AdWords. Google prend donc un pari : il est prêt à se couper éventuellement d'une partie de ses revenus AdWords pour renforcer encore l'usage de son moteur par les internautes. "Eventuellement", car sans doute dans la majorité des cas, il n'y avait de toutes façons pas de publicité AdWords sur ces requêtes. Mais au global, Google y gagne de toutes façons, c'est le match de la fidélisation et donc des parts de marché.
Remarquez que Google fait exactement la même chose avec Google+ : jusqu'à quand Google pourra-t-il se permettre de ne pas y mettre de publicité ? Des jolis liens textes contextuels hyper-personnalisés pourraient pourtant apporter des millions de dollars...
On peut également imaginer que les travaux réalisés par Google pour son "graphe de la connaissance" seront utilisés sur mobiles dans Google Now, une façon de mieux concurrencer Apple et son système Siri.
Quel impact pour le référencement ?
Lisez mon point de vue sur l'impact du Knowledge Graph sur le référencement, publié au moment de sa sortie aux USA.
Pour l'instant c'est encore un peu tôt pour conclure, mais il est certain que les habitudes des internautes risquent de changer. En termes d'impact SEO, on pense en premier lieu aux sites de type encyclopédique, qui pourraient perdre du trafic. En effet, l'internaute qui cherchait une information "basique" comme un lieu, un nom, une date, etc. n'aura plus besoin d'aller visiter certains sites qui pourraient donc voir leur trafic chuter. Y compris Wikipédia !
Mais attention, ce n'est pas si évident, car le Knowledge Graph incite les internautes à creuser et à aller chercher une information un peu plus aboutie que celle affichée en premier dans les SERP. Toutes les requêtes successives sont autant d'opportunités pour les sites de contenu à se positionner et à obtenir du trafic. Cela pourrait donc favoriser les sites à fort contenu. Y compris Wikipédia ?
Il y a certainement d'autres impacts, notamment sur le référencement local et sur le référencement des images. J'y reviendrai dans d'autres articles...
Pour en savoir plus
Pour en savoir plus, consultez ce mini-site de Google. Vous pouvez aussi en savoir plus en regardant cette vidéo :
De la publicité dans le Knowledge Graph
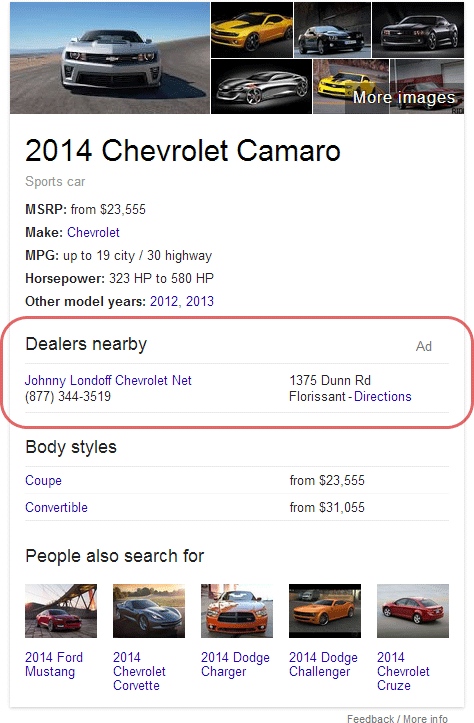
Sans aucune annonce officielle, comme d'habitude uniquement une capture d'écran d'un internaute qui l'a remarqué : Google a commencé en décembre 2014 l'inclusion de publicités dans l'encart Knowledge Graph affiché à droite des SERP.
Sans le libellé "Ad", il aurait été impossible de deviner qu'il s'agit d'un emplacement publicitaire, tant le look ressemble aux autres données issues du Knowledge Graph de Google.
Est-ce un test qui sera vite oublié ? Ou au contraire généralisé et annoncé officiellement ?
Nous n'en savons rien pour l'instant, mais pour ma part cela ne m'étonne pas du tout...

Bonjour à tous, je vous lis avec grand intérêt et ne comprends évidement pas tout..;) J ai une question simple auquel le vous pourrez peut être répondre. Je m 'occupe de la com´ de richard orlinski, un artiste contemporain , et aimerait savoir pourquoi il n'a pas droit a son knowledge..;) Jeff koons l'a...Richard est très en place dans ce milieu, et très connu. Est ce parce que richard est français? Peut on faire une demande a Google? Gratuite, payante? Merci mille fois @ByLalee
Absolument génial pour l'utilisateur, et pour ce qui est de Wikipedia cela réduira leur facture de bande passante sans doute. Tous les tests que j'ai fait jusqu'ici ramènent un lien Wikipedia, la question qui se posera pour nous référenceurs sera :
- peut-on avoir ses infos (et son lien) dans le KG, et comment ??
Et aussi :
- Jusqu'où s'étendra le KG? décrira-t-il aussi les apparts à Paris, donnera-t-il les définitions d'un mot, les détails techniques d'un produit ?
j'ai la même sensation qu'Enr...
J'ai aussi l'impression que la tendance est à réduire les résultats naturels en les noyant dans des ensembles thématiques issus d'autres produits ou partenaires de Google...
Intéressant les discussions de ce sujet, c'est vrai que des gens pourraient prendre comme vérité absolue ce que propose KG. Il y aura forcement des erreurs d'informations avec ce nouveau système. Je me pose aussi la question, comment se fait la sélection des images qui illustrent Knowledge. Là encore ça va être un sujet de polémiques, compte tenu du faible nombre de places. Ça peut être très intéressant d'y voir une image de son site dans ce petit cadre magique. Donc, à suivre... PS: Je n'ai pas vu de recettes de cuisine ?
Un exemple de résultat avec google graph à droite et une pub adsense centrale : http://jeromeweb.net/google_graph_carre_senart_adsense.png
Requête 'carre senart', c'est le nom d'un centre commercial dans le 77. La pub s'affiche uniquement quand je suis loggé sur mon compte gmail par contre
La photo en HDR proposée est un peu décalée de la réalité par contre
@ Olivier Duffez
Un tout dernier mot sur le sujet. La position du site officiel dans les SERPs dépend de tellement de choses.
Ex le portail officiel et multilingue de Moscou est en première place sur google.fr (requête: Moscou), mais il est complètement absent en anglais sur google.com (requête: Moscow), actuellement du moins.
Il ne faut pas non plus perdre de vue que KG pourrait s'étendre à d'autres entités. Pour l'un ou l'autre hôtel par ex., on voit une présentation très similaire à celle de KG (avec des liens publicitaires de réservation, mais pas vers l'hôtel concerné).
> Et comme Franck, j'ai peur de la pertinence des infos, le web est truffé de fausses informations, nous sommes les premiers a créé des contenus sans intérêt ou totalement bateau, voir complètement faux mais avec un seul but positionner un site...
Désolé mais :
- Tous les créateurs de site/contenu ne sont pas des black SEO.
- On peut *déjà* créer du contenu bidon pour bien se positionner. Ça peut marcher, un temps. Rapidement, les moteurs font le ménage, quand ce ne sont pas les internautes eux-mêmes (WOT par exemple).
Tout d'abord , pour éviter tout malentendu, ce dont je parle, c'est uniquement la partie à droite des SERPs.
Qu'y voit-on ? soit des liens vers Wikipedia, soit vers d'autres recherches chez google soit encore des liens vers des sites d'images.
Si google voulait donner réellement "toutes les informations sur un sujet sans nécessiter des requêtes supplémentaires", il me semble qu'il devrait AUSSI inclure dans ce volet à droite le lien vers le site officiel concerné. Non ?
Cas du Taj Mahal: les liens sont vers Wikipedia et vers le fournisseur de la seule image (chez moi, c'est un lien vers site religieux de Californie). Donc dans ce volet à droite, on parle du Taj Mahal avec des liens, mais dont aucun ne pointe vers l'essentiel: le site officiel du Taj Mahal !
NB
Ceci n'est pas une critique de KG et encore moins de ta présentation de KG. Mais, cela me fait penser que le but réel de KG est plus de garder l'internaute chez google plus longtemps que de lui fournir l'info de la manière la plus directe.
En effet, mais le site officiel est en général le 1er de la requête, ça ferait donc un peu doublon, et il n'y a pas toujours de notion de site officiel pour les termes qui disposent d'un encart KG (je me demande même si ce n'est pas une minorité)
Au vu de quelques tests, je vois que jamais (?) le site officiel concerné par la requête n'est pas indiqué parmi les divers informations fournies par KG.
Or, à mon sens, cela devrait être le cas si le but était bien de "fournir un maximum d'informations sur un sujet sans nécessiter des requêtes supplémentaires".
Que google graph oriente l'internaute vers des sujets connexes, c'est OK. Mais pourquoi ignorer l'essentiel: le site web concerné en premier lieu ?
Des exemples Willgoto ?
Pourquoi google devrait il arrêter de modifier son algo ?
Sincèrement, c'est assez intéressant pour les internautes, je trouve que ça valorise vraiment l'utilisation du moteur de recherche.
Mais comme Nicolas, je pense que le nerf de la guerre n'est pas là, si on prend Paris ou France, là ça fonctionne sur île Maurice ça se lance sans donner d'infos et sur ile maurice là adwords direct.... Je ne sais pas si c'est une question de réglage, mais bon......
Et comme Franck, j'ai peur de la pertinence des infos, le web est truffé de fausses informations, nous sommes les premiers a créé des contenus sans intérêt ou totalement bateau, voir complètement faux mais avec un seul but positionner un site.....
Quand Google arrêtera t-il se modifier constamment son algorithme ? ..
C'est en place dans la version mobile...
Mais rien sur mon PC
@Olivier : sur "poisson rouge", les images étaient en 5e résultat, à la place de la vidéo Youtube de ce jour, mais pour "mer rouge", les images qui étaient en 2e résultat (donc trafic valable pour les 4-5 images dans ce résultat) ont disparu en 2e page des résultats (preuve, s'il en fallait une, que l'algo GG fait ce qu'il veut avec les images dans la position des résultats et qu'il n'existe pas de logique visible, et idem pour les vidéos qui apparaissent maintenant en 1ère page sur certaines requêtes alors qu'elles n'étaient pas là auparavant -cas encore de poisson rouge-).
Et je confirme : seule la première image est purement "anglaise", elle n'apparaît d'ailleurs jamais dans les résultats image avec une recherche image. D'autre part, même si l'image existe sur wiki FR, le lien mène vers le Wiki EN/US.
D'ailleurs, selon le KG, le poisson rouge vient du lac Utah... bonjour la pertinence. Et comme le dit Frank, les gamins vont demain indiquer que le poisson rouge est d'origine américaine depuis l'Utah! ^^ Dans les images sur "requin", on y trouve aussi du dauphin -pourtant facile à distinguer de loin avec son aileron recourbé vers l'arrière-, etc...
Concernant Wiki FR (le Wiki EN est à peu près à jour), j'ai relevé plus de 2000 erreurs de taxonomie -nom binomial des espèces- : rien n'est mis à jour concernant les poissons, plantes, ... certaines espèces ont changé de nom scientifique depuis plus de 3 ans! Pour dire la charge que ça représente, sur mon site, c'est 4 à 5 heures par mois juste pour suivre et mettre à jour les évolutions taxonomiques. Conclusion, Wiki propose plusieurs milliers d'erreurs (qui ne seront vraisemblablement jamais corrigées) intégrées dans le KG.
@olivier
Je vais essayé d'être plus clair. Il y a 2 idées dans mon commentaire.
Concernant le risque d'appauvrissement des données, en effet, Google n'a demandé à personne de changer quoi que ce soit. Seulement, actuellement dans l'outil Webmaster Tools de Google, il existe un item sur les données structurées. On sent que Google a envie d'emener sur ce terrain. N'y a t il pas là un risque que les sites qui fournissent juste ces données structurées soient mis en avant ? Dans ce cas, n'y a t il pas de risque que les articles de blog et autres soient relégués ? Or n'est ce pas dans les données non structurées d'articles qu'on trouve des idées ?
Concernant l'information prédigérée : KG va chercher dans Wikipedia. Or lorsqu'on va sur Wikipedia, on peut grace à la banière ou au pied de page ou à la discussion, évaluer la pertinence des informations. Avec KG, aurons nous une bannière nous disant : "voilà ce qu'on sait sur le sujet mais bon, on n'est pas trop sûr de nos sources ?" Ceux qui ont l'habitude faire des recherches savent qu'il faut croiser les sources. Mais il y a des tas de gamins qui à l'école font des exposés en se basant sur Wikipédia uniquement. Et demain ? Se baseront-ils uniquement sur le KG ?
Google devient agrégateur de contenus et présente ce qui ressemble à des pages d'information. Ce n'est plus pareil.
Merci Franck, ce sont des interrogations intéressantes !
Il faudra en effet encore plus qu'avant éduquer les gens pour qu'ils ne prennent pas tout ce qu'ils trouvent (sur Google, Wikipédia ou ailleurs) pour des vérités absolues.
Je ne suis pas convaincu que cela aura un impact sur le SEO, pour les encyclopédie peu être mais pas le reste.
Je viens à nouveau de vérifier sur certains mots-clés, et je confirme ce que je disais précédemment dans le forum : les sites français vont perdre pas loin des 100% du trafic image sur les requêtes où le knowledge graph s'affiche : la première place image (quand il y a plusieurs images) est systématiquement issue d'un site en anglais et dirige vers ce site en anglais (ça, pour l'avenir lointain, ça pourrait être un bon point et faire réfléchir les internautes).
Dans mon cas, avec un site d'aquariophilie, la totalité des espèces de poisson, plantes aquatiques, etc... (je viens d'en regarder une bonne centaine ce matin) mènent désormais sur des sites en anglais quand le KG est présent. Vive la France...^^
@Aquaportail : En effet, l'impact pour les images semble très fort. Seule la 1ère image est ainsi réservée aux sites anglais ? Les autres semblent plus équilibrées non ? Pour une requête comme "poisson rouge", les images s'affichaient à quel niveau avant le KG ?
Dans les années 80-90, les banques d'affaire ont embauché à tour de bras des mathématiciens pour transformer le monde entier, tout ce qui s'achète et se vend, en équation mathématique. On voit aujourd'hui le résultat avec la folie boursière.
On peut craindre que ce nouvel outil très séduisant oblige chaque producteur d'information à faire entrer ses informations dans des schémas que Google reconnaitra, mais en appauvrissant du même coup le contenu. De l'information pré-digéré sans même le contrôle de la communauté des utilisateurs, comme aujourd'hui celle de wikipedia qui veille même si c'est imparfait.
@Franck : je ne comprends pas ce raisonnement... Ce que Google a déjà réussi à faire avec le Knowledge Graph (KG) actuel :
1- n'a pas nécessité aux producteurs d'information de changer quoi que ce soit chez eux
2- est justement basé entre autres sur des données fournies par des communautés d'utilisateurs (Freebase et Wikipédia notamment)
Je pense en effet qu'il est encore un peu tôt pour se prononcer sur les retombées que cela aura en SEO. Je sais pas vraiment si Google a besoin de "fidéliser" ses internautes ou d'augmenter son nombre de pages vues pour développer ses revenus, mais en tout cas ce nouveau service va être un réel plus !
Ca fait peur quand meme car les resultats naturels sont de moins en moins mis en avant avec les annees qui passent...
Sur ces mêmes requêtes, "albums jonny halliday" ou "brad pitt" je n'ai rien de nouveau de mon coté, que ce soit logué ou anonyme.
J'ai cependant les liens web/images/map/shopping/actu en double en haut des résultats, ce qui est nouveau j'ai l'impression.
Mais jusqu’où va t'il s'arrêter le GG? Il va être dominant partout! Limite ça fait un peut peur!
Je ne suis pas d'accord avec l'analyse selon laquelle Google se coupe d'une partie de ses revenus pour pousser son Google Graph.
Google ne vend pas d'AdWords sur les mots-clés concernés par le Knowledge Graph : taj mahal, brad pitt ou encore physique nucléaire : avez-vous déjà vu des AdWords sur des requêtes de ce type ?
Le nerf de la guerre pour les revenus de Google c'est "rachat crédit", "devis assurance" et autres "acheter appartement paris".
En effet Nicolas, j'y étais allé un peu trop catégorique, j'ai édité mon article.