

Vous pouvez suivre ce tuto quel que soit le niveau d'optimisation du référencement naturel de votre site :
- le trafic Google diminue de mois en mois
- le trafic Google stagne malgré vos efforts
- vous pensez avoir eu une pénalité Google et votre référencement semble bloqué
- vous cherchez de nouvelles idées
Voici les 5 étapes à suivre, dans l'ordre :
- Audit technique SEO
- Stratégie de mots-clés
- Optimisation du contenu
- Optimisation de l'expérience utilisateur
- Travail sur la notoriété du site
Vous allez voir, y'a du boulot ! Mais au moins vous avez une marche à suivre, avec des étapes précises et plein d'astuces et de liens...
Remarque : avec tous les dossiers présents sur WebRankInfo et ce tuto en particulier, vous devriez vous en sortir tout seul (avec l'aide des outils proposés).
Etape 1 Audit technique SEO
La toute première chose que je fais à chaque fois, c'est un audit technique exhaustif du site. L'idée est de profiter de la simplicité des outils pour repérer s'il y a le moindre problème ou sous-optimisation qui handicape votre site en termes de référencement Google.
Comment voulez-vous augmenter votre trafic Google si les fondamentaux du référencement ne sont pas remplis ?
Comme vous le savez sans doute, je propose sur la plateforme My Ranking Metrics (dont je suis co-fondateur) un outil dédié à ça : RM Tech. Il permet en quelques clics d'effectuer un audit technique à moindre coût. Vous devriez en lancer un immédiatement en version gratuite, rien que pour voir s'il trouve des problèmes :
- s'il ne trouve rien ou pas grand chose d'important, passez à l'étape 2
- sinon, corrigez les problèmes en suivant les explications détaillées fournies dans le rapport complet (payant)
Voici le genre de tableau de synthèse que vous pouvez obtenir (y compris dans la version gratuite) :

Tant que vous avez des ronds rouges, vous ne devriez pas passer à l'étape 2 : il faut d'abord corriger les problèmes.
Je pense qu'il faudrait aussi traiter les cas des ronds jaunes, mais c'est à vous de voir...
💡 Astuce : complétez l'audit technique par un audit avancé de vos sitemaps ! Il permettra de trouver vos pages orphelines ainsi que de vérifier si vos sitemaps sont bien à jour et complets.
Remarques :
- Si vous souhaitez voir directement ce que RM Tech vous fournit en sortie, voyez ce rapport d'audit SEO (PDF), c'est un bon exemple.
- Je vous explique aussi la marche à suivre pour faire un audit de référencement, avec toutes les étapes détaillées
- Il est également important de créer un compte Search Console et de vérifier régulièrement les erreurs ou avertissements indiqués par Google.
Etape 2 Repensez votre stratégie de mots-clés
Il est certainement très utile de reprendre du début la recherche des mots-clés les plus stratégiques, en partant des besoins des utilisateurs et non pas de votre offre. Explications...
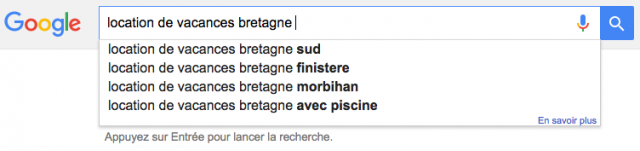
Vous avez certainement déjà constitué une liste de mots-clés, c'est-à-dire une liste des requêtes sur lesquelles vous pensez que votre site doit arriver 1er dans Google.
Je vous suggère de repartir d'une page blanche, avec un regard le plus neuf possible ! Plusieurs raisons :
- votre liste est peut-être dépassée, trop vieille : elle mériterait une mise à jour, car les internautes ont évolué, tout comme votre offre
- votre liste a peut-être été fournie par un référenceur : il n'est pas impossible qu'elle ne soit pas assez adaptée à votre site, ou assez complète
- votre site contient peut-être trop d'expressions-clés génériques : en grand débutant du référencement de site web, vous pensiez à l'époque que c'était ça qu'il fallait viser, mais aujourd'hui vous avez compris... Compris que viser des requêtes beaucoup trop concurrentielles ne sert à rien (sauf à perdre de l'énergie), que mettre des mots-clés qui ne transforment pas car trop vagues ne sert à rien ou presque

Sans aller jusqu'à vous décrire la méthode dans les détails, suivez ces étapes :
- Assurez-vous que pour vous, les objectifs précis du site sont très clairs (ce n'est pas toujours le cas quand on démarre un nouveau projet). Est-ce de la vente en ligne ? De la récupération de leads (contacts) ? Des revenus publicitaires ? Autre chose ou un mélange de tout ça ?
- Faites une liste des persona, ces "clients-types" que vous souhaitez faire venir chez vous. Visez-vous aussi bien les ados que les seniors ? Les amateurs que les spécialistes ? Les particuliers que les professionnels ?
- Faites une liste de vos principales offres (de contenus, de produits, de services, etc.). Plus tard vous ferez une liste complète.
- Pour chaque offre, essayez de vous mettre dans la peau de chaque persona et demandez-vous ce que cette personne cherche vraiment par rapport à cette offre. Ensuite, imaginez les requêtes qu'elle pourrait faire sur Google. A part un brain storming, utilisez des outils. Pour n'en citer que quelques uns, essayez
- Google Suggest (soit directement sur Google, soit via des outils comme keyword.io ou le mien)
- les recherches associées indiquées par Google en bas de page de résultats, ou celles associées à chaque résultat
- Google Trends
- des outils pour trouver d'autres idées de mots-clés comme SEMRush ou éventuellement des outils plus spécifiques comme 1.fr, YourText.guru, SEOQuantum ou d'autres (attention, ils ne sont pas toujours exploitables dans tous les cas...). Faites attention à ne pas bourrer vos pages avec ces mots-clés...
- éventuellement le planificateur de campagne Google Ads (pour trouver de nouvelles idées de mots-clés ou pour tenter de les trier par importance, même s'il faut beaucoup se méfier des volumes de recherches mensuels indiqués par cet outil)
- Notez toutes ces requêtes dans un tableau, une par ligne, en indiquant dans une colonne l'offre concernée.
- Normalement, ça ne devrait pas poser beaucoup de problèmes d'indiquer pour chaque ligne de ce tableau l'URL de votre site de la page la plus appropriée pour le mot-clé concerné.
Voilà, vous avez fait un beau travail très important ! En fonction des résultats de l'étape 6, vous pouvez pour certains mots-clés vous retrouver dans ces situations :
- soit aucune page n'existe sur le site : l'idéal serait de la créer, et au minimum de compléter une page qui s'en rapproche
- soit à l'inverse, vous avez plein de pages possibles pour un même mot-clé : c'est un problème de structure, il vous faut sans doute créer une page "mère"
Il y a plein d'autres subtilités mais dans ce tuto je reste le plus concis possible (si on peut dire !).
Etape 3 Optimisez votre contenu
Maintenant que vous avez une idée des faiblesses de votre site (via l'audit technique) et des manques de contenu (via l'analyse sémantique), il est temps de mettre tout ça en pratique et d'améliorer vos contenus.
Les pages associées aux mots-clés de la liste issue de l'étape 2 sont les premières pages à travailler, celles qui doivent avoir un contenu irréprochable. Cela ne vous étonnera donc pas si je dis que chaque page doit avoir :
- un titre descriptif, avec des mots-clés mais aussi très accrocheur
- une balise meta description rédigée à la main, elle aussi aussi bien descriptive du contenu qu'incitative au clic. L'internaute qui voit son libellé dans les résultats de recherche (snippet) doit mourrir d'envie d'en savoir plus. Lisez ces conseils pour augmenter le taux de clics dans les SERP, le CTR est un élément majeur sur lequel vous ne devez pas faire l'impasse.
- aucun problème de contenus dupliqués (j'ai une checklist ici, ou un dossier là)
- et surtout beaucoup de valeur ajoutée ! En général ça demande une certaine taille (nombre de mots) mais d'autres éléments entrent en jeu.
Comme vous le remarquez, j'insiste sur le fait que le titre (balise title) et l'extrait dans les SERP (souvent issu de la meta description) doivent être "accrocheurs". L'idée est que le taux de clic (dans les pages de résultats) sur vos pages doivent être très bons.
Le texte de chaque page stratégique doit inclure les expressions identifiées à l'étape 2, dans le tableau de synthèse. Ne vous "collez" pas aux mots, Google comprend de mieux en mieux le sens. Si vous ne le savez pas encore, Google est passé d'une vision "mots-clés" au sens qui se cache derrière, les thématiques précises (from strings to things). En d'autres termes, Google est devenu un moteur de recherche sémantique.
OK mais est-ce si rentable que ça d'investir dans la rédaction web ?
J'ai fait en avril 2019 une grande étude SEO pour répondre entre autres à cette question. La réponse, basée sur l'analyse de 84 millions de pages et 3,5 milliards de visites est la suivante :
Voici un extrait des résultats de l'étude My Ranking Metrics :
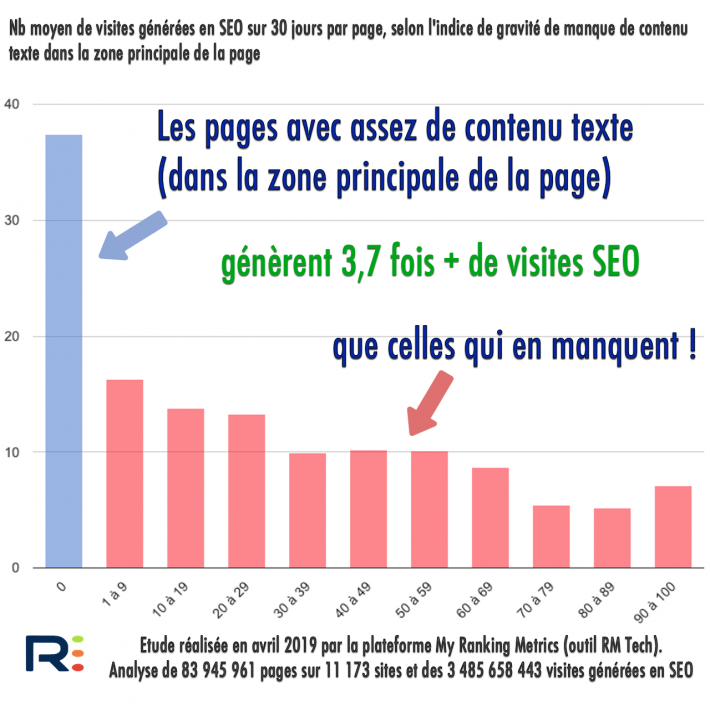
Si vous estimez ne pas avoir le temps pour la création et l'optimisation du contenu éditorial, la plus grosse erreur serait de se dire "je le ferai plus tard, quand j'aurai le temps". Franchement, ce serait une erreur majeure dans votre stratégie SEO.
Pour bien comprendre ce point essentiel, regardez cette courte vidéo (intérêt de la rédaction web pour le SEO) :
Je vous conseille donc plutôt de sous-traiter ça à des spécialistes de la rédaction web (qui connaissent le référencement). Regardez par exemple les offres d'Eve Demange, Isabelle Canivet + Jean-Marc Hardy ou Muriel Vandermeulen et son agence WeAreTheWords. Si vous n'avez qu'un budget très réduit, passez par des plateformes de rédacteurs web comme TextBroker, GreatContent ou Textmaster.
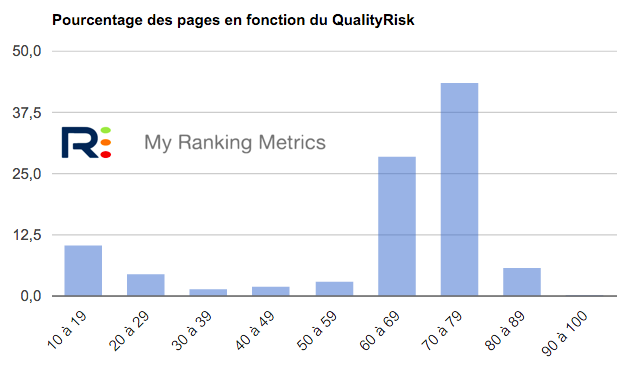
OK, j'ai plein de pages qui manquent de contenu, comment trouver les pages de plus mauvaise qualité à traiter prioritairement ?

Au-delà des pages stratégiques trouvées à l'étape 2, vous devriez vous assurer que votre site ne contient pas de pages de trop faible qualité, ou alors une toute petite proportion.
Vous avez 2 solutions :
- la meilleure est d'appliquer ma méthode Pages Zombies. Vous avez besoin d'un accès à Analytics et Search Console, ainsi que de savoir calculer l'indice zombie de chaque page. Mon outil RM Tech l'inclut de façon native.
- l'autre solution est d'évaluer la qualité intrinsèque de chaque page. C'est ce que je fais quand je n'ai pas accès à Analytics et Search Console (par exemple pour des devis). Pour cela, je vous recommande très chaudement :
- de lire en entier mon dossier Qualité et référencement Google
- et de regarder le replay de mon webinar sur QualityRisk
Tout ça est garanti très utile pour améliorer votre référencement :-)
Remarque : les pages les plus importantes de votre site sont a priori listées dans le tableau de l'étape 2. Pour chacune, vérifiez ses indices Zombie et QualityRisk dans les annexes de votre audit RM Tech. Elles doivent absolument avoir des indices à zéro.
Etape 4 Expérience utilisateur
L'optimisation traditionnelle d'un site pour le référencement n'est désormais plus dissociable de l'amélioration de l'UX (expérience utilisateur). Voyons comment faire d'une pierre deux coups (augmenter le taux de satisfaction ou de transformation ainsi que la visibilité dans les moteurs).
Vous pensez peut-être que je me trompe de tuto? Je vous rassure, améliorer l'expérience utilisateur et le taux de satisfaction est vital pour votre référencement (et pour votre business).
Si je devais résumer et ne vous donner qu'un seul conseil, ce serait celui-ci :
Soyez obsédés par l'idée que l'internaute qui arrive de Google (SEO) ne doit surtout pas revenir en arrière dans les résultats de recherche, surtout s'il a passé peu de temps sur votre site. La pire des choses serait qu'une forte proportion des internautes issus du trafic "organic" aient ce comportement. A l'inverse, tout faire pour qu'ils ne reviennent pas chez Google vous aidera à vous sortir des griffes de Panda, Phantom et autres algos liés à la qualité et à la satisfaction utilisateur.
Si ce sujet vous intéresse, j'ai un dossier très complet : comment garder l'internaute plus longtemps sur son site.
J'aborde ci-dessous quelques pistes...
Compatibilité mobile

Ai-je besoin de rappeler que vous n'avez pas le choix? Votre site DOIT être compatible mobile ; la visite de votre site sur smartphone doit être facile, agréable tout en assurant un très bon taux de transfo.
Si votre site n'est toujours pas "mobile friendly", c'est peut-être pour ça que vous voyez peu d'internautes mobiles dans vos stats Analytics. Ce n'est pas l'inverse ! Dans ce cas, prévoyez dès que possible une refonte de votre site.
Vitesse du site web
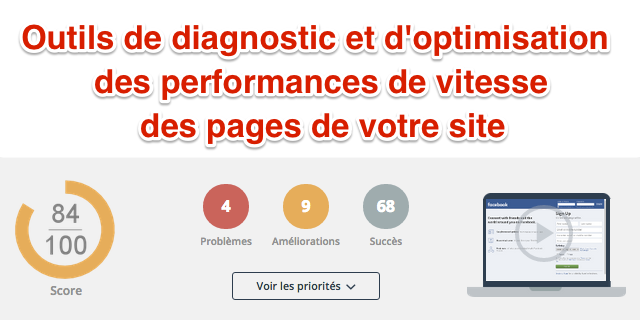
Votre site doit être ultra rapide ! La 1ère raison est que ça améliorera l'efficacité du site (revenus générés, contacts récupérés, etc.). La seconde est que cela améliorera votre SEO.
Vous le saviez déjà, n'est-ce pas ? OK, mais je veux rester très concret dans ce tuto, alors voici mes conseils :
Commencez par étudier la vitesse pour le crawl (de Google notamment) : je fais référence ici au temps de téléchargement (ça n'inclut pas les images, ni l'exécution de Javascript ou CSS). D'abord, allez dans Search Console rubrique "Exploration > Statistiques sur l'exploration" et vérifiez que le temps moyen de téléchargement est inférieur à 600ms (visez même 400ms, ou 200ms, c'est possible). Se baser sur la moyenne est nettement insuffisant. Si vous avez lancé un audit RM Tech, vous avez le temps de téléchargement de chaque URL, si bien que vous savez quelles pages doivent être optimisées en priorité. C'est très efficace !
Ensuite, étudiez la vitesse pour les internautes : je fais référence ici au temps de chargement (incluant les images et l'exécution des scripts Javascript et des CSS).
Pour améliorer la vitesse de votre site :
- utilisez cet outil de diagnostic très sophistiqué
- lisez ces conseils
- faites un audit pour trouver les images trop grandes et/ou trop lourdes
- voir aussi : SEO images
Facilité de navigation sur le site
Faites tester votre site à des personnes qui ne le connaissent pas encore. S'il répond "non" à une ou plusieurs questions, c'est qu'il faut améliorer votre site !
- Le modèle économique du site est-il compris en 1 à 2 secondes maximum, quelle que soit la 1ère page consultée ?
- Trouve-t-on rapidement les pages stratégiques ?
- Y a-t-il un fil d'ariane clair et visible sur chaque page ?
- Les menus sont-ils faciles à comprendre pour celui qui découvre le site ?
- Y a-t-il sur la plupart des pages des liens vers des pages connexes (articles ou produits similaires, marque ou catégorie, etc.) ?
Remarque : les pages les plus importantes de votre site sont a priori listées dans le tableau de l'étape 2. Pour chacune, regardez dans les annexes de votre audit RM Tech quelle est sa profondeur. Elles devraient être de niveau 1 (accessible en 1 clic de puis la page d'accueil) ou au pire de niveau 2, car une page trop profonde a souvent un mauvais référencement.
Optimisation du taux de conversion

Faire venir du monde sur votre site c'est bien, c'est même indispensable. Faire en sorte que les internautes remplissent vos objectifs est tout autant indispensable pour la réussite de vos activités en ligne ! Qu'il s'agisse d'achat en ligne, de remplissage de formulaires de contacts, d'appels téléphoniques, d'inscription à une newsletter, de renvoi vers des partenaires ou de revenus publicitaires, vous devez mesurer le taux de conversion afin de chercher à l'augmenter.
Il vous faudra au minimum un bon outil de mesure d'audience (style Google Analytics), mais sans doute aussi de l'aide de spécialistes de la "conversion". Utilisez des outils de tests A/B pour trouver comment organiser et présenter votre offre de la façon la plus efficace possible.
Je ne m'étends pas plus car ça sort vraiment du cadre "SEO" de ce tutoriel.
Etape 5 Améliorez votre notoriété
Comment depuis le début (PageRank), la notion de notoriété est majeure dans l'algo de Google. Aujourd'hui, elle ne passe pas seulement par les backlinks, mais aussi le développement de la marque (branding) et les réseaux sociaux.
La notoriété (backlinks, marque, réseaux sociaux) encore incontournable

La notoriété du site (telle que Google peut l'évaluer) reste encore un élément décisif dans le succès de votre référencement naturel. C'est ce qui fera décoller votre trafic - à condition d'avoir suivi à la lettre les 4 étapes précédentes.
Avant, on se bornait à dire "obtenez le plus de backlinks possible", ces fameux liens pointant vers votre site. Tant qu'à faire, avec vos mots-clés comme texte cliquable.
Avant de vous donner quelques idées très concrètes pour obtenir des bons liens, je voudrais vous faire remarquer qu'il y a au moins 2 autres éléments qui participent à augmenter la notoriété de votre site :
- une marque (officielle ou assimilée) est-elle associée à votre site ? Est-elle forte ?
- votre site a-t-il du succès sur les réseaux sociaux ? Ses pages y sont-elles souvent partagées ?
Il est évident que Google tente de déterminer la marque associée à votre site. Plus il y a d'internautes qui la cherchent chaque mois, plus Google la considère importante. Le top du top, c'est d'avoir plein d'internautes qui font des recherches mixtes "marque + mot-clé", ce qui indique à Google que votre site est important pour cette thématique.
Revenons aux backlinks... A part chercher des "spots" que Google ne "détectera jamais" pour y "poser des backlinks", je vous propose quelques idées assez simples :
- profitez de vos backlinks actuels qui pointent vers des pages en erreur 404 (suivez mon tuto ici)
- un peu dans le même genre, surveillez vos backlinks actuels pour être prévenu s'ils disparaissent : ça peut parfois se rattraper en contactant le site concerné
- contactez ceux qui mentionnent votre site sans lui faire de liens : voyez s'il est possible de leur demander de remplacer la simple mention par un lien
- contactez tous vos partenaires réels et demandez-leur de parler de vous sur leur site (avec un lien) : partenaires, fournisseurs, revendeurs, contacts en tous genres et pourquoi pas clients
- contactez des journalistes et dites-leur que vous êtes un expert dans telle thématique et que vous êtes disponible pour contribuer à leurs prochains articles
- étudiez les backlinks qu'ont obtenus vos concurrents, provenant de sites qui ne font pas (encore) de lien vers vous. Utilisez Ahrefs ou Majestic, 2 outils spécialisés sur l'analyse des liens. Si c'est trop lourd à faire pour vous, je peux le faire pour vous.
- la liste pourrait être bien plus longue, mais ce dossier se fait déjà un peu long ;-)
Questions-réponses SEO
Pas simple, ça ne se fait pas en 2 minutes. Pourtant, il faut suivre du bon sens et respecter les fondamentaux :
🔷 tous les aspects techniques doivent être parfaits : faites les audits nécessaires jusqu'à tout corriger
🔷 le contenu doit être bien mieux que ce que font tous les concurrents. Il doit répondre parfaitement aux attentes des personnes que vous visez. Chaque page doit être complète tout en étant agréable et facile à consulter sur mobile et sur ordinateur.
🔷 la marque associée au site doit être reconnue dans votre domaine d'activité, ce qui doit se traduire par des requêtes incluant la marque et des backlinks naturels...
Il n'existe pas de durée identique pour tous les sites, ça dépend de beaucoup de critères. A vous d'évaluer en combien de temps vous pourrez :
🔷 créer une page "pilier" (très complète) sur chaque sujet majeur pour votre activité, supportée par toutes les pages filles nécessaires (qui rentrent dans les détails non traités dans la page mère). Les anglais parlent parfois de contenu cornerstone.
🔷 vous démarquer de la concurrence en termes de notoriété
Il risque de se passer au moins 6 mois sans grands résultats. Au bout de 12 mois ça devrait avoir bien augmenté et vers les 18 mois le trafic devrait avoir fortement augmenté. Pour y arriver, il faut absolument combiner l'excellence des contenus à l'obtention de backlinks ou mentions de la marque.
D'abord, vérifiez que vous avez appliqué la méthode décrite ici, globalement.
Ensuite, rappelez-vous que Google n'affiche pas des sites mais des pages dans les résultats. Il faut donc trouver quelle page de votre site est une bonne candidate à arriver en 1ère position dans les SERP. Ensuite vous en trouverez plusieurs...
J'ai un truc à vous proposer à ce sujet. Lisez comment passer de page 2 à page 1 sur Google.
Oui, si vous parlez du référencement naturel (organic), vous pouvez le faire gratuitement dans le sens où vous n'avez rien à payer à Google pour être bien positionné.
Par contre ça demande de nombreuses ressources (techniques, humaines, financières) si bien qu'on ne peut pas dire que ça ne soit pas un coût. Disons que c'est un investissement, qui rapport généralement bien plus que le SEA (achat de pub sur les moteurs de recherches).
A ce sujet, voir aussi le lien entre Google Ads et le référencement organique.
Difficile de répondre en quelques lignes, surtout que cela dépend de nombreux facteurs, dont :
🔷 la taille et la complexité du site : nombre d'URL, nombre de modèles de pages, nombre de sous-domaines, CMS et technos utilisés...
🔷 l'ancienneté du site : un site ancien avec plein de particularités peut être plus difficile à améliorer (même si souvent la notoriété d'un ancien site est meilleure)
🔷 la concurrence du secteur d'activité
Il faut surtout prévoir dans votre budget les différents modules dont j'ai parlé dans cet article : audit technique (+ corrections), stratégie de contenus puis optimisations éditoriales (anciens et nouveaux contenus), amélioration de l'UX et travail sur la notoriété du site...
Pour un tout petit site, vous pouvez espérer une amélioration du SEO pour quelques centaines d'euros. Pour la plupart des sites, il faut compter plusieurs milliers d'euros, et pour les plus gros largement plus...
Un site WordPress doit être travaillé et optimisé pour le référencement comme tous les autres sites faits avec d'autres CMS ou sans CMS. Lisez tout de même ces conseils SEO pour les blogs afin d'en savoir plus.
Besoin d'aide pour votre site Internet ?
D'abord, si vous avez des questions, posez-les dans les commentaires, ça me permettra d'améliorer ce tutoriel SEO.
Avec tous les dossiers présents sur WebRankInfo et ce tuto en particulier, vous devriez vous en sortir tout seul (avec l'aide des outils proposés) et obtenir un meilleur référencement naturel.
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Salut !
Une ptite question:
Il est préférable de faire toute ces étapes avant ou après la finalisation de mon site ? Appliquer tes conseils pendant la création, ou retoucher à la fin ?
Merci
Il est préférable de faire tout ce qui est possible en amont, avant la mise en ligne.
Bonjour,
C'est quoi la "zone principale de la page" ?
Est-ce ce qu'on voit sur la page d'un smartphone, d'un pc, suivant les écrans le contenu affiché peut grandement varier.
La zone principale d'une page est constituée de contenus exclusifs à cette page. C'est son contenu propre. Généralement, ça démarre au H1 et se termine à la fin du contenu.
Inversement, le reste de la page est constitué de l'entête (avec le menu), d'une ou 2 barres latérales (ou pas), de blocs de contenus associés, de pub (éventuellement), du pied de page.
Salut
je vous remercie pour tous vos conseils prodigués.
Excellente mise à jour. L'article couvre bien le sujet et met bien en application les recommandations qu'il décrit notamment en termes de contenu.
Bonjour et merci pour votre article très pertinent sur le référencement. Nous sommes très content de vos articles sur le référencement, nous avons pu améliorer notre position dans les résultats de recherches, merci beaucoup.
Bonjour Olivier,
J'ai visionné votre vidéo "comment convaincre un client d'acheter de la rédaction web" et souhaiterais comme demandé, vous indiquer une autre technique qui peut convaincre.
Par exemple, on peut tout à fait montrer au client un précédent article ayant généré beaucoup de trafic. On peut lui apporter la preuve via Google Analytics et lui affirmer l'importance de la rédaction web dans l'apport de visiteurs sur son site.
J'espère que cette méthode peut vous être utile,
Sofia
Oui ça peut aider, mais il peut ne pas être convaincu que c'est grâce à l'éditorial...
Superbe article et merci beaucoup Olivier. Un site web de référence pour le référencement naturel. Je profite également de vos vidéos sur Youtube. Je rédige pas mal de contenus sur mes sites internet pour attirer du traffic, pour exemple mon site https://webmasterautop.com
Le contenu c'est bien mais j'ai besoin d'être à l'écoute de vos stratégies pour faire des progrès. A bientôt.
merci pour ces informations !
Bonjour,
Super cet article. Des choses que je sais dans les grandes lignes... Mais les grandes lignes ne suffisent pas.
Un process essentiel à reprendre calmement, juste pour être sure de ne rien louper.
Côté pingouin, le native avertising, faut mieux oublier non ? Ou Ca reste le nerf de la guerre ?
Merci
si le native advertising passe en Javascript par une régie, je doute que ce soit pris en compte par Google
Merci pour la remarque Olivier. Je ne manquerais pas d'apporter quelques corrections. Merci d'être passé par là.
Très bon article. Bien que long, j'ai pris le temps de le lire en entier, car il a de la valeur ajouté pour toute personne désireuse d'optimiser son référencement naturel. Comme complément, j'aimerais inviter tes lecteur à jeter un coup d'oeil sur cet autre article qui présente les techniques de rédaction web optimisées. http://www.afroblogging.com/2016/06/comment-ecrire-un-article-optimise-seo.html
en tout cas le vôtre est rempli de fautes d'orthographe :-(
Bonjour Olivier
Je suis venu sur une de tes formations à Marseille je lis régulièrement tes posts
Est ce google pénaliste le fait de répondre à des messages dans les blogs en y mettant le nom du site
Souvent on peut y mettre le nom , l adresse mail et l adresse url du site web
Cela aide un peu ou pas du tout au référencement
Je ne suis pas à plaindre au niveau référencement, 1er sur le mot dragées par exemple mais mon site à tendance à baisser depuis mi février peux être à cause la nouvelle mise en page de Google , 4 Google annonces , je ne sais pas si cela a un impact sur le référencement naturel
Je pense qu' une nouvelle formation est obligatoire pour 2016/2017
Merci pour ta fidélité à me suivre dans ce que je fais et propose ;-) Je suis content de voir que ça t'a aidé à être bien visible sur Google.
Mettre des liens dans les commentaires sur des sites hors thématique, on ne peut pas dire que ce soit les meilleurs liens qui soient... Je conseille donc d'éviter ou que cela reste en volume ou proportion très faible.
Salut Olivier,
Merci pour ce tuto. J'ajouterais qu'il peut-être nécessaire de nettoyer ses backlinks pour éviter des pénalités.
On remarque souvent sur les vieux sites des backlinks vraiment douteux (de l'époque où il fallait bourriner un maximum).
Moi j'utilise SEO SpyGlass qui permet d'avoir une idée des liens à risque, ou sinon sur MajesticSEO faire un export des liens sous Excel. Puis trier les URL le TF (Trust Flow) dans l'ordre croissant et le CF (Citation Flow) dans l'ordre décroissant.
Une fois la liste obtenue, vous pouvez commencer à vérifier ces liens puis à demander au webmaster la suppression et si pas de réponse les désavouer dans la Search Console. Evidemment à faire avec précaution !
@+
Un petit outil gratuit que j'utilise depuis quelques mois pour suivre mes mots-clés et qui est pas mal: serp labs (la version gratuite permet de suivre le positionnement de 500 mots); ahref et majestic sont encore un peu au-dessus de mon budget et ça dépanne bien en attendant!
Je ne connais pas, mais ces outils gratuits peuvent aider également en effet.
As-tu d'autres remarques sur ce tuto référencement ?
"chercher des "spots" que Google ne "détectera jamais".
Roh mais faut pas partir si défaitiste ^^