
Différence entre crawl et indexation

N'oubliez pas qu'il y a une différence entre le crawl (l'exploration selon la traduction usuelle en français) et l'indexation.
D'abord, Google vient consulter une page (pour la 1ère fois ou pas) : il s'agit de récupérer une copie de la page pour la stocker sur ses serveurs. En général, la page est alors disséquée, analysée et mise dans l'index de Google, c'est-à-dire dans le catalogue de l'ensemble des pages connues de Google et pouvant sortir un jour dans les résultats. A ce niveau, Google a déjà préparé toutes sortes d'analyses afin de retrouver facilement la page pour les requêtes pour lesquelles elle est jugée pertinente.
Dans le cas d'une nouvelle page que Google découvre, elle doit forcément d'abord être crawlée pour être indexée. Pour une page déjà dans l'index de Google, Googlebot (le crawler de Google) doit la crawler à nouveau pour découvrir si elle a changé - et pour refléter ces (éventuels) changements dans les pages de résultats.
Maintenant que vous avez bien noté la différence entre crawl et indexation, voyons les mécanismes qui vous permettent de limiter les actions de Google.
Le blocage du crawl : par le fichier robots.txt
Pour bloquer le crawl, il faut indiquer la ou les URL des pages pour lesquelles vous souhaitez interdire l'accès. Pour cela, il faut publier ces directives dans le fichier robots.txt à la racine du site. Pour être très précis, sachez que :
- le nom de ce fichier est imposé : ne mettez pas robot.txt (sans S) ou autre chose, il ne serait pas pris en compte
- il doit y avoir un fichier robots.txt pour chaque sous-domaine
Ce n'est pas l'objet de cet article d'expliquer les détails, donc si ça vous intéresse, consultez mon dossier sur la syntaxe du fichier robots.txt ou l'aide de Google.
Le blocage de l'indexation : par une balise meta robots noindex
Pour interdire à Google d'indexer une page qu'il a précédemment crawlée, il faut ajouter une balise meta robots noindex (ou googlebot noindex). Si la page concernée n'est pas au format HTML, vous ne pouvez pas ajouter de balise meta, mais vous pouvez dans ce cas passer l'instruction dans l'entête HTTP. Pour en savoir plus, consultez mon dossier sur l'entête X Robots Tag ou l'aide de Google.
Présenté comme ça, vous devez certainement avoir compris un point spécial : si une page a déjà été indexée, alors un blocage par le robots.txt ne permet pas de la faire désindexer, même si ce blocage est doublé d'une interdiction d'indexation ! En effet, Google n'ayant pas votre autorisation pour consulter la page, il ne peut pas constater que vous lui interdisez d'indexer la page (ou que vous demandez la désindexation).
Dans ce cas précis, pour désindexer une page, il faut simplement arrêter de bloquer le crawl. Dès que Google visitera la page et constatera qu'il y a une balise meta robots noindex, il la désindexera.
Il y a néanmoins une autre possibilité : passer par Google Search Console et demander une désindexation immédiate.
Google respecte-t-il toujours les directives du fichier robots.txt ?
C'est une question qui revient souvent et effectivement il y a parfois de quoi se poser des questions. En effet, Google essayant toujours d'indexer plus de pages, il peut arriver des cas où vous demandez pourquoi Google a crawlé (et indexé) des pages.
De simples indications, pas des obligations
Aussi étonnant que ça puisse paraître, Google considère en fait que les règles que vous lui demandez de suivre dans le fichier robots.txt sont de simples indications, pas des obligations.
En clair, la plupart du temps il en tient compte, mais pas dans 100% des cas. Je vais l'expliquer ci-dessous.
Pour comprendre la nuance :
- l'URL canonique n'est qu'une indication que Google respecte souvent mais pas obligatoirement
- le noindex (balise meta ou entête HTTP) est une obligation : Google en tient toujours compte quand il la rencontre
Attention à la chronologie des modifications du fichier robots.txt
D'abord, l'explication la plus simple est que Google n'a pas encore consulté votre fichier robots.txt. Vous devez donc d'abord vérifier dans les logs de votre serveur que Google a effectivement consulté le fichier robots.txt.
Google connait des pages sans pourtant y accéder !
J'ai découvert un autre cas un peu particulier : Google semble indexer des pages pourtant interdites d'accès par le robots.txt. Concrètement, voici ce que j'ai fait comme 1er test (répété plusieurs fois pour valider) :
- j'ajoute une interdiction de crawler le fichier testabc.php (à la racine du site) dans mon fichier robots.txt
- j'attends plusieurs jours, en tout cas le temps nécessaire pour m'assurer que Google a bien pris en compte la nouvelle version du fichier robots.txt
- seulement alors, je mets en ligne la page testabc.php et lui fais un lien depuis la page d'accueil. Voici les détails :
- le texte de lien est "WRI", sans nofollow
- la balise title de la page testabc.php est "ABC DEF test titre"
- cette page est interdite d'indexation via une balise meta name="robots" content="noindex"
- cette page étant interdite de crawl (et même d'indexation, au cas où), je ne m'attends pas à ce que Google vienne la consulter et l'indexer. Je mets en place mon système de surveillance des robots pour être prévenu si Google vient voir la page ou l'indexer, et j'attends...
- quelques jours plus tard, alors que Google n'est jamais venu crawler la page (double vérification dans mes logs !), la page se retrouve indexée dans Google ! En tout cas, ça y ressemble fort, comme vous pouvez le voir dans cette capture d'écran :
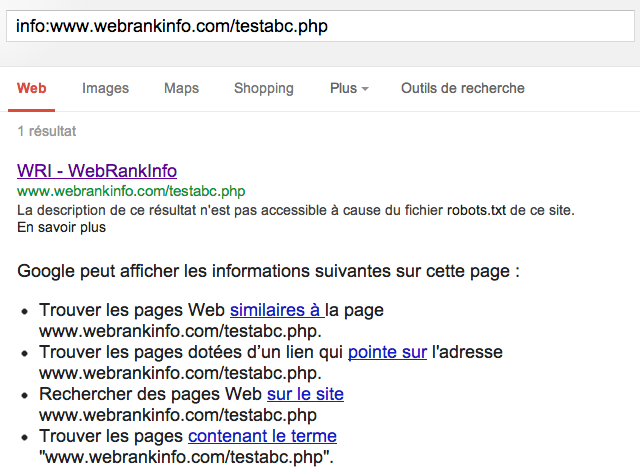
Conclusion : Google peut indexer une page sans l'avoir crawlée !
A la place de la description de la page, Google affiche dans le snippet la phrase suivante :
La description de ce résultat n'est pas accessible à cause du fichier robots.txt de ce site. En savoir plus
Alors, Google comment Google a-t-il pu indexer une page qu'il n'a jamais crawlée ? Réponse : elle n'est pas indexée, ou alors pas comme on l'entendu habituellement. A y regarder de plus près, Google ne connaissant pas son contenu, il est obligé d'inventer un titre (il assemble l'anchor text "WRI" et la marque du site "WebRankInfo") et indique ne pas pouvoir créer de descriptif ("La description de ce résultat n'est pas accessible à cause du fichier robots.txt de ce site.").
On remarque également que Google ne propose pas d'accéder à la version en cache de la page. Logique, puisqu'il n'a pas pu y accéder.
En fait, Google fournit exactement ces informations dans ses pages de support :
Même si le contenu des pages bloquées par le fichier robots.txt n'est ni exploré, ni indexé, il est possible que nous indexions les URL de ces pages si nous les rencontrons sur d'autres sites Web. Cela signifie que l'URL de la page et, éventuellement, d'autres informations accessibles au public, notamment le texte d'ancrage des liens qui pointent vers le site ou le titre créé par l'ODP (Open Directory Project, www.dmoz.org) peuvent apparaître dans les résultats de recherche Google.
Concrètement, Google indique à l'internaute qu'il connait l'existence de la page mais qu'il n'a pas pu y accéder (pour cause d'interdiction). Ce genre de page ne sort donc quasiment jamais pour des requêtes classiques, seulement dans des cas très particuliers. Et justement, quand on s'intéresse au référencement, on peut faire partie de ces cas particuliers, surtout quand on utilise des commandes spéciales de Google. En effet, à cause du mécanisme que je viens de décrire, vous ne pouvez plus vous fier au nombre de résultats indiqué par Google pour une commande site: (déjà que ce n'était pas très fiable...).
Remarque : depuis, suite à d'autres tests, j'ai laissé cette page se faire indexer, donc vous ne pouvez plus constater la même chose que dans ma capture d'écran ci-dessus.
J'ai fait d'autres tests de plus grande ampleur que je ne peux pas détailler ici, notamment parce qu'ils concernent un autre site que WebRankInfo. Quand je dis "plus grande ampleur", cela veut dire plusieurs milliers de pages. Au bout d'un mois de test, j'ai eu la surprise de constater que ces pages jamais crawlées ont généré en SEO Google 340 visites. Conclusion : Google peut vous générer du trafic grâce à des pages qu'il n'a jamais crawlées !
Peut-on faire disparaitre des résultats Google des pages que l'on ne veut absolument jamais voir dans les résultats ?
Dit autrement : peut-on désindexer ces pages (qui pourtant n'ont jamais vraiment été indexées et n'auraient jamais dû apparaître puisqu'elles étaient bloquées à Google) ? Pour le savoir, j'ai encore fait un test ! Au passage, si vous ne faites pas comme moi de nombreux tests sur le référencement, vous ne pouvez pas assez bien progresser...
J'ai donc enlevé la directive Disallow du fichier robots.txt afin de laisser Google accéder à la page, pour qu'il constate qu'elle est interdite d'indexation. Pour gagner du temps, je suis allé dans Google Webmaster Tools faire une demande de crawl express. Moins d'une minute après, je reçois une alerte par mon système m'indiquant que Googlebot est venu voir la page. Par contre, la page reste désespérement dans cet état de "semi-indexation"...
Pour une autre page de test "pseudo-indexée" de la même façon que la première, j'ai utilisé une autre méthode pour la faire disparaitre de Google : une demande de suppression via Google Webmaster Tools. Et là miracle, au bout de quelques heures, la page disparait effectivement totalement (introuvable par des commandes info: ou site:).
Le cas de la directive noindex dans le fichier robots.txt
Version 2019 : Google ne tient plus compte de la noindex dans robots.txt
Google a annoncé que depuis le 1er septembre 2019, la directive noindex dans le fichier robotx.txt n'est plus supportée.
Si jamais vous l'utilisiez, mettez en place une autre solution !
Je laisse la suite en guise d'historique, pour vous aider à mieux comprendre.
Version 2013 : Google tient compte de la noindex dans robots.txt
Tant qu'à faire tous ces tests, j'ai également essayé la directive NoIndex que j'ai déjà trouvée sur dans le fichier robots.txt du site d'un de mes clients. Attention, il ne faut pas confondre avec la balise meta robots noindex standard. Ne la connaissant pas, ne trouvant aucune trace dans la documentation officielle de Google et ne trouvant que peu d'informations à son sujet sur le web, j'ai moi aussi testé.
Dans Google Webmaster Tools, je demande à Google de crawler immédiatement la page. Voici la réponse :
Impossible d'explorer la page pour le moment, car celle-ci est bloquée par la dernière version du fichier robots.txt téléchargé par Googlebot. Sachez que si vous avez mis à jour le fichier robots.txt dernièrement, son actualisation peut prendre jusqu'à deux jours.
Il n'y a pourtant aucune directive Disallow concernant cette URL. La seule directive présente dans le fichier robots.txt est la suivante :
User-agent: * Noindex: /dossiers/google-desindexation-presse-france.php
D'ailleurs, cette paire de lignes génère des erreurs dans les outils de validation du robots.txt car la ligne "User-agent: *" n'est suivie d'aucune directive Allow ou Disallow.
Mon test a montré que cette commande noindex dans le robots.txt bloque même le crawl. J'ai voulu faire le test inverse pour compléter l'analyse : j'enlève la directive Noindex, je laisse indexer la page, et seulement ensuite j'ajoute la directive Noindex. Il a fallu attendre plusieurs jours, mais la page a fini par être désindexée, sans que Google revienne crawler la page.
J'en conclus donc que Google respecte la directive Noindex du robots.txt même s'il ne fournit aucune documentation dessus.
J'ai toutefois relevé que John Mueller déconseille clairement de l'utiliser :
Et vous ?
Je suppose que vous avez déjà rencontré des cas similaires : n'hésitez pas à nous donner des retours d'expérience ou à poser vos questions. Si cela ne suffit pas, n'oubliez pas les solutions habituelles :
- demander de l'aide gratuitement sur le forum crawl et indexation
- me demander un audit de référencement naturel
- assister à ma formation, notamment le module qui explique comment faire indexer son site dans Google (avec détails sur le crawl, la désindexation, la "masse noire", etc.)
Audit SEO de site à base de crawl
Si vous souhaitez optimiser le référencement naturel de votre site, il est indispensable de vérifier que les bases sont correctement faites, à savoir tout le socle technique du SEO. Pour comprendre comment mon outil RM Tech d'audit SEO peut vous aider, consultez cette vidéo d'analyse de site touché par Panda :
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Bonjour, merci pour ces infos. Donc au final, il ne faut pas s'inquiéter si Google indexe des pages exclues du crawling par le fichier robots.txt ?
Ca ne grignote pas notre budget de crawl ? Ni ne fait baisser la qualité générale du site perçue par Google ?
Si, il faut s'en inquiéter, car ce n'est pas normal que des pages bloquées au robots.txt soient indexées.
Mais alors, comment faire pour empêcher cela ?
Mettre une balise robots noindex et laisser les pages se faire crawler ? Mais du coup, on perd en budget crawl...
J'ai ce problème avec un site d’événements.
Les événements en cours et futurs sont crawlables et indexables. 1 mois après la fin de l'événement, la page est toujours crawlable mais avec une balise robots no index, Google respecte bien cela et désindexe la page. Puis, les événements passés des années précédentes sont exclus du crawl (l'année est dans leur url, il est donc facile de les Disallow dans le fichier robots.txt) et c'est à ce moment là que Google les indexe à nouveau.
Je ne vois pas comment m'en sortir. J'ai des pages du type archives où les anciens événements sont listés + des sites font des liens vers les événements passés, c'est pour cela que Google continue à trouver des liens de pages qui sont exclues du crawl.
C'est clair que c'est très pénible que Google ne respecte pas toujours le fichier robots.txt
Le mieux je pense est :
1- de ne pas bloquer le crawl (les problèmes de budget de crawl concernent les sites de + de 10.000 voire 100.000 pages, est-ce ton cas ?)
2- de ne plus faire de liens vers les événements passés (ni les mettre dans des sitemaps)
Non, je ne suis pas à 10000 pages, environ 3000. Merci pour tes indications.
Bonjour,
Nous apercevons de jour en jour que tous les robots (Googlebot, SemrushBot...) ne sont présents uniquement que pour se faire de l'argent sur le dos de votre site: vos informations ne vous appartiennent plus !!!
Cordialement.
ça m'a l'air très exagéré cette affirmation... Semrushbot vient sur le site sur demande de son propriétaire généralement. Ou sinon, il suffit de l'interdire dans le robots.txt (il le respecte).
@olivier Merci pour ta réponse, je vais réfléchir à l'audit ;) Mais je vais dans un premier temps attendre un peu pour voir si Google corrige "l'erreur" tout seul et sinon je changerai les paramètres d'URL... Merci
Bonjour à tous,
Depuis quelques jours, Google indexe les URLs avec paramètres (de tri, de session... la totale). Donc normalement il faudrait qu'il indexe 250 URLS et là il est à plus de 1 400...
Le site est sur Magento, dans la console Google Search, les paramètres d'URL sont présent avec la méthode d'exploration "Laisser GoogleBot décider".
Pas de restriction au niveau du fichier robots.txt.
Donc je ne sais pas pourquoi, il s'est mis à me crawler et indexer toutes ces URLs... alors que depuis 2 ans, il se contentait des 250 "bonnes" URLS.
Bizarre non ?
@Julien : il aurait fallu prévoir ça en amont et ne pas faire confiance à la rubrique paramètres d'URL de search console. Il faut traiter le pb en amont, sur le site, avec des interdictions de crawl et/ou d'indexation selon les besoins.
Un petit audit RM Tech pourrait aider ;-)
Bonjour Olivier,
Je déterre un peu cette page car j'ai testé la balise noindex dans le robots.txt récemment sur un client. Je n'avais jamais testé avant préférant les valeurs surs (meta noindex).
Mon retour c'est que la directive noindex du robots.txt bloque bien le crawl et désindexe la page lorsqu'il l'a crawlé, ce qui contredit légèrement ton observation lorsque tu dis qu'il désindexe la page sans que google revienne crawler la page.
ça reste une directive bien pratique mais ce n'est pas magique, google doit revenir sur la page en question pour qu'elle soit désindéxée grace à cette balise noindex, ce qui peut être très long selon les cas.
@Serge : je l'avais testé, j'ai eu ce que j'ai indiqué. Ca ne change pas grand chose au final, c'est par curiosité, car au final c'est tout de même mieux d'utiliser la meta robots noindex. Pour accélérer le crawl, on peut se débrouiller ;-) ça dépend juste des volumes d'URL concernés
Ce n'est pas totalement le sujet, mais j'ai un débat en cours avec Google pour des pages qui se retrouvent dans l'index et n'ont jamais existé. En fait, Google va piocher je ne sais ou des pages très anciennes d'un sous domaine et la replace dans un autre sous domaine.
le problème, c'est que le sous domaine est un département (ex 01-ain . NDD) et la page une ville, et que je retrouve la page Marseille classée dans l'index Google avec le sous domaine 18-cher ... il y a bizarrement un cache récent avec un contenu très ancien qui n'existe pas dans le répertoire.
Mes logs et webmasters tools me confirment la tentative de crawl en erreur, ca ne vient pas de chez moi donc. Peutêtre mon serveur a déconné un jour et depuis, c'est la pagaille, mais après 5 mois, les erreurs ressurgissent avec ces pages qui sortent d'on ne sais ou. Et comme c'est par dizaine de milliers, je ne peux pas toutes les rediriger.
Bref, j'ai deja developpé le détail est ici ; https://www.webrankinfo.com/forum/t/2-rappels-importants-404-et-pages-vides.168189/
Les mécanismes interne a Google pour l'indexation des pages est un mystère et parfois curieux.
Il est possible aussi que certaines commandes telles que "site:" interroge des data autres que celui de l'index primaire. Mais effectivement, on retrouve parfois ces pages dans les résultats sous forme de lien sans contenu, résultat construit sur une url et non pas sur le crawl comme l'explique très bien Olivier.
@Marc : "Mes logs et webmasters tools me confirment la tentative de crawl en erreur, ca ne vient pas de chez moi donc."
=> non, cela ne prouve pas que le pb ne vienne pas de chez toi, ça peut venir d'un mauvais lien interne
Merci Olivier, je vais me renseigner sur la balise meta robots noindex !
Bonjour à tous,
Merci pour cet article très complet et fouillé. Cela me rassure : j'ai récemment mis en place un robot.txt sur mon site web-tech.fr (pour éviter que les articles sponsos soient indexés), et force est de constater que cela n'empêche pas Google de crawler. Décidément, c'est bien lui le chef !
Bonne continuation,
Désolé Gregorix mais ça n'est pas comparable, en tout cas pour votre site il n'y a rien dans le robots.txt en place qui pourrait empêcher les articles sponsos d'être crawlés (et indexés).
Si on veut qu'ils ne soient pas indexés, il faut mettre une balise meta robots noindex et je vois qu'il n'y en a pas (j'ai testé sur un exemple).
Bonjour Olivier,
pour ce qui est du trafic naturel que cette page pseudo indexée à obtenu il serait intéressant de nous dire si les requêtes ayant généré des visites avaient un rapport avec :
- Le contenu de la page elle même
ou plutôt avec
- Le contenu de la(des) page(s) qui pointaient vers cette page interdite au bot ?
En gros la pertinence de cette page sur certaines requêtes est elle obtenu grâce à son propre contenu ou par hérédité grâce aux contenus présents sur les pages qui la lient ?
merci
Désolé, je pensais que c'était clair : Google n'ayant jamais lu le contenu des pages concernées, ne peut se baser que sur leurs backlinks.
D'ailleurs le titre dans les SERP est constitué de l'anchor text suivi du nom du site.
Merci pour cet article, j'ai testé le Noindex dans le fichier Robots, beaucoup plus efficace que le Disallow... ;o)
@Olivier Duffez
Je ne comprend pas ta réponse...
Une page que l'on ne désire pas mettre à la vue des robots n'apparaitra pas dans les moteurs... Il n'y a donc aucun pb de SEO vu qu'il n'y pas à en faire.
Et bloquer les robots ne bloque pas les internautes "humains", donc...
Non, je ne comprend pas ta réponse...
@ Koxin-L.fr
si justement, c'est l'objet de cet article. Des pages qu'on a toujours bloquées à Google (via robots.txt) afin qu'elles ne soient jamais listées dans Google, peuvent apparaitre dans Google. C'est donc bien un pb SEO.
"Sachez que si vous avez mis à jour le fichier robots.txt dernièrement, son actualisation peut prendre jusqu'à deux jours."
Pour avoir connu le cas récemment (2 pages que j'avais bloquées via robots.txt puis débloquées), j'ai continué à avoir une alerte dans webmaster tools comme quoi ces deux url étaient bloquées par robots.text pendant plusieurs semaines après le déblocage.
Pourtant, en dépit de ce message d'erreur, ces page étaient bel et bien indexées et apparaissaient dans les recherches.
j'en conclue que, dans le cas d'un déblocage, la prise en compte est rapide (crawl et indexation suite à déblocage et ajout des url au sitemap) mais que l'interface webmaster tool est longue à entériner le changement.
Bonjour,
Merci pour cet article très intéressant !
Voilà j'ai un problème dont je n'arrive pas à me dépêtrer ! Nous avons lancé notre nouveau site le 15 mai, à la suite de quoi, j'ai demandé une réindexation via GWT. Et là explosion des pages introuvables (plus de 323000 à ce jour !) et ça ne cesse de monter. Pour info, cela a fait remonté de vieux dossiers, déjà redirigés ou supprimés depuis des années !
J'ai donc agit sur le robots.txt pour mettre ces fameux dossiers en disallow.
Le nouveau robots.txt est bien passé sur GWT. Pensez vous que je doive à nouveau envoyer pour indexation pour faire chuter ces erreurs, car j'ai peur étant donné le nombre, de me faire pénaliser sous peu...
Avant cela dois je mettre le disallow + le no index dans le robots.txt ?
Merci de votre aide !
@ #so# : le plus efficace serait de créer une discussion dans le forum, en indiquant les URL concernées
@Olivier : c'était juste un clin d'oeil à la chaude actulité concernant Prism et les services de Google. Ceci dit, Google crawlera ce qu'il a envie de crawler, la barrière du ficher robots.txt doit être bien peu solide et contournable (non?).
@fred : tout le monde sait que le robots.txt n'est pas un outil de sécurité web. Par contre, tous mes tests m'ont montré que Google respecte les directives du fichier robots.txt, à savoir que si on interdit le crawl, il ne crawle pas.
"Dans le cas d'une nouvelle page que Google découvre, elle doit forcément d'abord être crawlée pour être indexée."
Je suis pas certain, si on la bloque par le robots.txt, google sait que la page existe, il l'index quand même (mais elle va presque jamais sortir), et on aura d'ailleurs le message "description non accessible blablabla".
@silvain156 : faudrait définir ce qu'on appelle indexer, mais en règle générale, il s'agit d'analyser le contenu et de le stocker dans une base de données (index). Bref, dire qu'une URL (sans son contenu) est indexé n'est pas ce qu'il y a de plus courant comme définition.
1. Ta page abc.php est bel et bien indexée, comme le montre la requête suivante. Elle y apparaît avec un titre et un snippet tout à fait correct.
Elle a aussi un cache qui actuellement date du 26 mai.
Et cette indexation n'est pas due au fait que des internautes ayant une google barre aient visité ta page à la lecture de ton article parce que le cache date du 26 mai.
2. D'autre part, il y a une page identique avec une URL erpgokldfgkjf_lfjgkhfd.php et un cache du 28 mai mais qui figure dans le moteur depuis le 15 mai déjà.
3. Quant au fait que ces pages donnent du trafic, cela n'est pas (si l'on peut dire étonnant) parce que il y a des requêtes de toutes sortes (y compris par jeu, test, ou autre).
@willgoto :
1- oui je sais, ma page de test a servi à d'autres tests ensuite, notamment pour voir la réaction de Google quand j'enlève l'interdiction de crawl et/ou d'indexation. Donc oui c'est normal que désormais elle soit "totalement" indexée.
2- désolé je n'ai pas compris
3- je ne dis pas que ces pages puissent se positionner sur des requêtes stratégiques, loin de là, mais elles ont tout de même généré du trafic par des internautes qui n'étaient absolument pas en train de faire des recherches bizarres : il s'agissait bien de requêtes avec des mots standards. C'est simplement étonnant d'avoir du trafic depuis des pages non crawlées...
Avec le projet PRISM des services secrets américains, je doute que de telles indications soient une barrière efficace. Après, qu'elle soit indexée ou pas par Google est une autre histoire.
Désolé Fred, je n'ai pas compris le rapport avec PRISM. De quelles indications et barrière parles-tu ?
Il faudrait poser la question à Google (John Wiley ?) de quel est l'intérêt d'afficher ces snippets dans les SERPs. Simple bug ?
En tout cas, j'ai l'impression avec mes collègues que cela revient de plus en plus régulièrement.
Je prends bonne note de la directive Noindex dans le robots.txt au cas où :)
Victor
Article intéressant : la prise en compte effective du no-index semble assujettie à l'endroit de sa déclaration (page ou robots.txt).
Une autre solution est placer un link rel canonical sur les pages à désindexer. C'est certes moins rapide et moins large (pas de grosse regexp comme dans un robots.txt), mais au moins sur chaque page on peut faire des conditions et donc avoir une granularité plus fine dans la sélection des pages à désindexer.
Slt,
J'ai toujours dit qu'il fallait un blocage des robots aux pages "interdites" via le htaccess parce que le fichier robots.txt n'est pas un blocage mais une information...
Je suis bien content aujourd'hui d'avoir toujours utilisé cette procédure.
Rod
Oui enfin... ta solution ne convient pas pour les pages que les internautes doivent pouvoir consulter librement, tout en ne posant aucun pb SEO
à moins de faire du cloaking ?