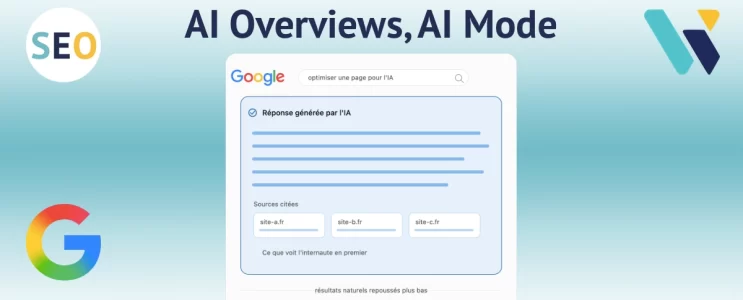
Comment optimiser une page pour être cité dans les AI Overviews et l'AI Mode de Google
AI Overviews et AI Mode arrivent en France d'ici le 23 septembre 2026. Les pages qui ne sont pas citées dans la réponse générée vont perdre du trafic. Voici comment optimiser les vôtres pour rester visible.








 Créateur du site WebRankInfo en 2002, je suis consultant SEO et éditeur de la plateforme SEO MyRankingMetrics. J'ai travaillé pour de très nombreux clients de toutes tailles et formé des milliers d'autres référenceurs. J'interviens régulièrement dans des conférences (FePSeM, SEO Summit...).
Créateur du site WebRankInfo en 2002, je suis consultant SEO et éditeur de la plateforme SEO MyRankingMetrics. J'ai travaillé pour de très nombreux clients de toutes tailles et formé des milliers d'autres référenceurs. J'interviens régulièrement dans des conférences (FePSeM, SEO Summit...).
