

Sommaire :
- l'annonce officielle de Google
- comment avoir un site compatible mobile ?
- comment Google tient-il vraiment compte du critère Mobile Friendly ?
- comment profiter de son appli mobile en SEO ?
Article mis à jour le 31/08/2016, publié initialement le 27/02/2015
Google a officialisé la mise à jour version 2016 (Tweet de John Mueller) :
L'avènement du mobile comme critère de ranking
On le sentait venir depuis très longtemps, avec l'arrivée dans Google Search Console (GSC) d'une rubrique listant les incompatibilités mobiles du site. Puis début 2015 Google a envoyé de nombreux mails (toujours via GSC) pour alerter les webmasters du nombre d'URL présentant des problèmes de compatibilité mobile. Voici un exemple de ce mail :
Corrigez les problèmes d'ergonomie mobile détectés sur http://www.example.com/
Nos systèmes ont testé N pages de votre site et ont découvert que X % d'entre elles contiennent des erreurs majeures d'ergonomie mobile. Les erreurs présentes sur ces N pages nuisent gravement à la bonne utilisation de votre site Web par les mobinautes. Ces pages ne seront pas considérées comme mobile-friendly (adaptées aux mobiles) dans la recherche Google, et seront affichées et classées en conséquence pour les utilisateurs de smartphones.
Le 26/02/2015, Google a publié un article annonçant que les pages incompatibles avec les mobiles seront moins bien positionnées dans les résultats de recherche mobiles.
Deuxième annonce : les applications mobiles compatibles avec les critères d'indexation de Google seront plus souvent mises en avant dans les résultats mobiles. Détails ci-dessous...
Pour commencer, voici le texte exact de l'annonce de Google :
Starting April 21, we will be expanding our use of mobile-friendliness as a ranking signal. This change will affect mobile searches in all languages worldwide and will have a significant impact in our search results.
Dont voici une traduction libre :
A partir du 21 avril [2015], nous allons étendre notre utilisation de la compatibilité mobile pour en faire un critère de positionnement. Ce changement concernera les recherches mobiles dans toutes les langues partout dans le monde. L'impact sur les résultats de recherche sera significatif.
La sortie fut mondiale, concernant tous les pays et toutes les langues. Depuis, les autres moteurs de recherche ont également adapté leurs algorithmes afin de tenir compte de la compatibilité mobile.
Lisez bien ce dossier, il contient plein de conseils pour améliorer votre référencement mobile sur Google !
Comment rendre son site compatible mobile ?
Pour vous aider, j'ai identifié les meilleures ressources et les nombreux conseils de Google pour effectuer les changements techniques nécessaires. Vous trouverez un peu plus loin des réponses à toutes vos questions.
Qu'est-ce qu'un site compatible mobile ?
Comme je l'explique plus loin, on travaille page par page. Une page est considérée comme adaptée aux mobiles si Googlebot détecte qu'elle respecte les critères suivants :
- Elle évite d'utiliser des logiciels peu courants sur les appareils mobiles, tels que Flash. (Flash est d'ailleurs totalement à bannir)
- L'utilisateur peut lire son contenu sans devoir zoomer sur la page.
- Le contenu de la page s'adapte à l'écran utilisé et l'utilisateur n'a donc pas besoin de zoomer sur la page ni de la faire défiler horizontalement.
- Les liens présents dans la page sont suffisamment éloignés les uns des autres pour faciliter les interactions tactiles. La largeur de la pulpe du doigt d'un adulte est en moyenne de 10 mm, et les consignes relatives à l'interface utilisateur Android recommandent un élément tactile d'environ 7 mm au minimum ou de 48 pixels CSS sur un site avec une fenêtre d'affichage pour mobile correctement configurée. En outre, il ne doit y avoir aucun autre élément tactile dans les 5 mm (32 pixels CSS) autour des liens ou boutons, horizontalement ou verticalement, afin qu'un internaute qui appuie sur un élément tactile n'en touche pas un autre par inadvertance
- Quand l'internaute arrive sur le site mobile, si vous affichez une publicité interstitielle pour qu'il installe votre appli mobile, elle ne doit prendre qu'une partie de l'écran. Lisez les détails dans mon dossier sur les publicités interstitielles.
Les 3 méthodes pour rendre un site compatible mobile
On distingue 3 façons de rendre son site compatible mobile. Pour un bon référencement naturel mobile sur Google, vous devez en choisir une et valider que votre site est bien compatible, mais aucune des 3 n'est favorisée en termes de positionnement ("ranking"). Cela dit, Google (comme beaucoup de monde) recommande le responsive design.
- Responsive Web Design (design adaptatif) :
- le même code HTML est affiché sur la même URL quel que soit l'appareil utilisé : ordinateur, tablette, téléphone mobile ou navigateur non visuel. Toutefois, le design s'adapte selon la taille de l'écran, par exemple l'agencement des blocs ou la présence d'un menu ou d'une barre latérale.
- Pour le référencement, il faudra s'assurer de servir le même code à Googlebot qu'aux internautes, et ne pas bloquer de ressources à Googlebot (JS, CSS, images). Dans ce cas, la détection de la compatibilité mobile se fera toute seule sans soucis.
- Dynamic Serving (diffusion dynamique) :
- utilise la même URL quel que soit l'appareil utilisé, mais génère une version distincte du code HTML pour les différents types d'appareil selon les informations dont dispose le serveur au sujet du navigateur (cloaking selon le User Agent). L'avantage sur le Responsive Design est de pouvoir alléger la taille des fichiers téléchargés par les appareils mobiles.
- Pour le référencement, il faut signaler à Googlebot qu'il existe une version dédiée aux appareils mobiles, afin qu'il envoie bien sa version Googlebot for smartphones. Ceci se fait par l'envoi d'un entête HTTP "Vary".
- URL distinctes (site mobile sur une URL spécifique) :
- un code HTML distinct est affiché sur chaque appareil et sur des URL distinctes (par exemple le site mobile se trouve sur m.example.com tandis que le site desktop se trouve sur www.example.com). Cette configuration essaie de détecter le type d'appareil de l'internaute, puis le redirige vers la page appropriée à l'aide de redirections HTTP et de l'en-tête HTTP "Vary".
- Pour le référencement, il faut signaler à Googlebot les différentes URL par le biais d'annotations.
Conseils pour faire un bon site mobile efficace en SEO
Pour améliorer votre SEO mobile, commencez par faire un tour sur le site de Google "les fondamentaux du web" ainsi que sur "faire un site mobile-friendly".
Encore d'autres ressources sur le référencement mobile :
- le forum WebRankInfo ! posez toutes vos questions SEO, mobile, développement web
- Aide Google : développer des sites pour mobile
- W3C : bonnes pratiques pour le web mobile
Faire un site mobile avec les principaux CMS
Si votre site est fait à l'aide d'un CMS mondialement connu, ça sera sans doute bien plus facile de le modifier pour avoir une version mobile. Avant de vous lancer dans cette refonte, prévoyez bien les étapes suivantes :
- Faites d'abord une sauvegarde complète de votre site (base de données, fichiers uploadés, thèmes, templates, etc.)
- Trouvez et installez un thème compatible mobile : ils le sont presque tous aujourd'hui, mais vérifiez tout de même que c'est indiqué responsive design, ou adaptatif
- Mettez à jour votre CMS
Les 7 erreurs fréquentes des sites mobiles
C'est Google qui les indique et les explique (suivez les liens) :
- Fichiers JavaScript, CSS et image bloqués
- Contenu ne pouvant être lu
- Redirections incorrectes
- Erreurs 404 uniquement sur mobiles
- Interstitiels de téléchargement d'applications
- Liaisons transverses non pertinentes
- Chargement lent des pages mobiles
Comment Google exploite vraiment le critère Mobile Friendly pour le SEO ?
Les informations qui suivent proviennent d'une conférence de Gary Illyes et de différents hangouts organisés par d'autres employés de Google.
Pas d'avantage particulier pour le responsive design
Même si Google recommande officiellement la technique du responsive web design (RWD), tant que le site est compatible mobile, aucune des 3 méthodes n'est favorisée par rapport aux autres.
Ne bloquez pas les CSS et Javascript à Google !
Le robot Googlebot a besoin d'accéder à vos fichiers CSS et JS pour "comprendre" votre site et notamment sa version mobile. Si vous les bloquez, Google pourra considérer que votre site est incompatible même s'il l'est en réalité pour les internautes. Ne bloquez donc surtout pas les feuilles de styles CSS et codes Javascript via votre fichier robots.txt.
Les ingénieurs de Google savent bien que certaines ressources externes au site peuvent être bloquées au crawl sans que le webmaster puisse changer les choses. Par exemple, des fichiers JS ou CSS de Twitter, Google Analytics ou autres peuvent être indiqués comme étant bloqués, mais ceci ne sera pas néfaste pour votre référencement naturel chez Google.
Le critère "Mobile Friendly" est évalué page par page
Comme le critère HTTPS, celui sur la compatibilité avec les mobiles est évalué par Google au niveau de chaque URL. En d'autres termes, certaines URL du site peuvent être compatibles et d'autres non, mais Gary Illies recommande que 100% de vos URL soient compatibles mobiles !
Quel est le délai de prise en compte par Google ?
Dès que Google crawle une URL et constate qu'elle est compatible mobile, il en tient compte immédiatement.
Ce "ranking signal" est-il en temps réel ?
Oui, en quelque sorte, disons qu'il est mis à jour en continu. A chaque fois que Google crawle ou recrawle une page, l'algorithme évalue si la page est compatible mobile. Dans la foulée de ce crawl, la page est indexée (ou mise à jour dans l'index) et bénéficie immédiatement du boost - si elle remplit les conditions.
Y a-t-il un impact SEO sur les recherches sur ordinateur ?
Non ! Le critère SEO Google de compatibilité mobile n'a pas d'impact sur les résultats de recherches effectuées sur desktop et tablette. C'est en tout cas ce que Google indique très clairement, même si de nombreuses personnes estiment le contraire...
L'impact sera sur les recherches effectuées sur mobile mais pas sur celles effectuées sur ordinateurs de bureau. Concrètement, quand vous prenez votre téléphone pour faire une recherche mobile, les résultats seront concernés (affected). Les sites compatibles mobiles seront remontés pour être plus visibles dans les résultats, et par conséquence les sites incompatibles mobiles seront listés plus loin.
Vous pouvez le voir ou l'écouter dans le hangout du 24/03/2015 en anglais vers 8mn50.
Pas de critère Tablet Friendly
A la connaissance de Gary, Google n'a pas prévu de critère concernant spécialement les tablettes. D'ailleurs, c'est souvent le site "desktop" qui est servi aux tablettes, non ?
C'est confirmé depuis par des hangouts : ce critère ne concerne que le mobile (smartphones) et pas les tablettes.
Google prévoit-il de gérer un index mobile totalement séparé ?
Gary a étonné l'assistance en répondant que Google travaillait déjà sur un tel projet. N'ayant pas plus d'informations sur l'équipe concernée, il n'a pas donné plus de détails.
Néanmoins, Zineb (de Google) semble l'avoir contredit lors du hangout du 25/03/2015 : elle a indiqué que Google a le même index pour mobile, desktop et tablette et qu'ensuite des filtres s'appliquent selon les cas, produisant des résultats différents...
Edit novembre 2016 : cet index mobile est officiel désormais !
Y a-t-il des degrés d'optimisation mobile ?
Non, le critère est binaire, du type OUI/NON, sans niveaux intermédiaires. Si la page est compatible mobile alors elle profite du boost, et sinon elle est incompatible et n'en profite pas.
Quel lien avec l'étiquette "site mobile" dans les SERP ?
Cette question n'a plus lieu d'être, puisque le label "site mobile" a été retiré des SERP en août 2016. Voici pour mémoire les explications de l'époque.
Cette mention "Site mobile", arrivée en novembre 2014, ressemblait à ça :
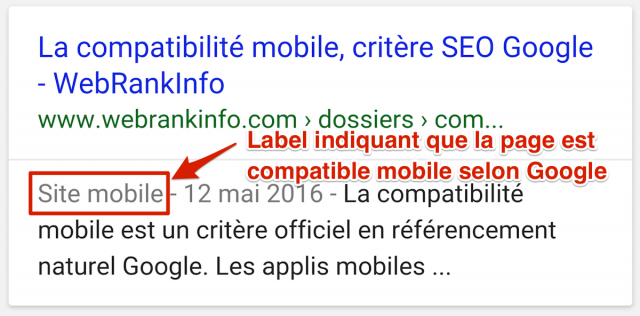
La raison est que 85% des pages mobiles apparaissant dans les SERP de Google sont compatibles mobiles (source).
Ce "tag" a disparu des pages de résultats (sur smartphones) vers le 31/08/2016, ce qui fait donc un peu plus de place pour afficher le reste du snippet, donc la description, ce qui n'est pas plus mal.
Par contre, l'avantage "psychologique" qu'avaient ceux avec des pages compatibles mobiles a disparu également. Ce qui ne va pas inciter ceux qui gèrent les 15% de pages incompatibles à faire le pas...
Pour savoir si une page est compatible mobile selon Google, il faut donc utiliser l'outil concerné, on ne peut plus le savoir en regardant les pages de résultats mobiles.
Qu'en pensez-vous ? On en discute dans le forum : suppression du label mobile-friendly dans les SERP.
Hangout en français
Il a eu lieu le 25/03/2015
Hangout en anglais
Il a eu lieu le 24/03/2015
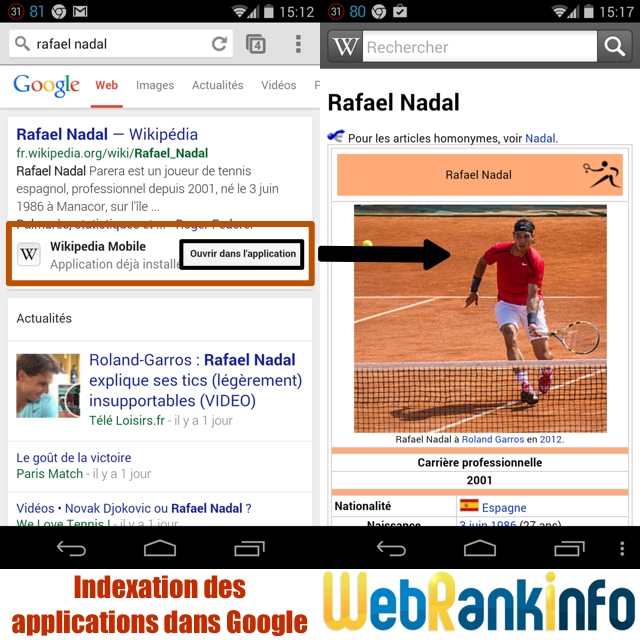
Mise en avant des applications mobiles indexées
La seconde annonce concerne l'indexation des applications mobiles dans Google. Voici la déclaration officielle de Google :
Starting today, we will begin to use information from indexed apps as a factor in ranking for signed-in users who have the app installed. As a result, we may now surface content from indexed apps more prominently in search.
Dont voici une traduction libre :
A partir d'aujourd'hui [26/02/2015], les informations que nous trouvons dans les applis indexées sont utilisées comme critère de positionnement pour les utilisateurs connectés qui ont déjà installé l'application. En conséquence, les contenus trouvés dans ces applications indexées seront affichées de manière plus importante.
Concrètement, Google indique que les applications concernées auront un meilleur positionnement, en plus de pouvoir bénéficier d'une mise en évidence dans les résultats de recherche.
Concernant la mise en avant visuelle des applications dans les SERP, elle existe depuis juin 2014 :
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Bonjour,
C'est bien de moderniser son site et le rendre mobile friendly mais souvent c'est les clients qui ne sont pas à jour. Il faut essayer de garder un équilibre entre la modernité de son site et le rythme d'adaptation de nos clients. Merci pour votre article.
Comme vous le dites tous, rendre son site mobile est la base pour réussir sur internet. Il faut se moderniser pour espérer devenir plus grand :)
Bonjour à tous,
Comme vous le dites dans votre titre, le mobile est bon pour le référencement mais surtout c'est essentiel à mettre en place si vous voulez garder vos clients ! Mais l'un ne va pas sans l'autre. Merci beaucoup. Zia
Pour un projet en cours de développement, je me pose la question du choix du site mobile en sous-domaine (redir via cookie) ou de l'utilisation du responsive en sachant que nous souhaitons ne pas afficher une partie du contenu de la version desktop pour ne pas surcharger l'affichage de la version mobile.
Olivier qu'elles sont vos préconisations ? Est-il risqué de ne pas afficher une partie du contenu pour le responsive mobile ?
Je recommande le responsive design, comme la plupart des gens et notamment Google.
Bonjour,
Super article ! Merci beaucoup pour toutes ces informations.
C'est tellement essentiel qu'un site soit adapté au mobile, en particulier dans le e-commerce. Ce ne sont pas toutes les plateformes qui offrent cette option et c'est bien dommage... mais avec un bon comparatif du type Shopify vs Kingeshop, Wix vs Weebly, etc, il est possible de savoir quelle plateforme est à jour dans ce sens :)
Bonne continuation à tous,
Will
Merci Olivier
pourtant de nombreux sites (vraiment) importants sans version mobile continuent à grimper dans les indices searchmetrics par exemple...
@Matthieu : l'algo tient compte de centaines de critères, ça peut donc être logique.
Bonjour Olivier,
Comme d'habitude, super article ! Il regorge de ressources et conseils pratiques que nous allons continuer à suivre pour avoir un site aussi mobile friendly que possible :)
Bonsoir, l'inconvénient du responsive Design, c'est que côté utilisateur ont peu se retrouver avec une page trop lente à charger. Des feuilles de styles css trop volumineuses, et des fichiers JS trop volumineux. Il suffit de faire une comparaison sur PageSpeed Insight, pour se rendre compte qu'un site en responsive ... on est dans les choux pour la version mobile. Idéalement, c'est de faire une version Responsive pour computer + Tablettes + Grands écrans, et une version dédiée aux téléphones mobiles / Smartphones, qui elle, utilisera des fichiers CSS et JS adaptés, et des images adaptées au format mobile. C'est beaucoup plus facile aussi pour créer une version mobile qui prend en compte l'expérience utilisateur / l'ergonomie. Et les temps d'affichages peuvent être beaucoup plus performants. Et donc plus agréable pour l'utilisateur. Tout le monde connait Bootstrap pour créer des sites responsive, il existe aussi une version Light "GoRatchet" pour créer rapidement une version mobile simple et efficace.
Bonjour
Je viens de prendre une grosse baffe Seo et je viens de commander la responsive pour mon site. Google reviendra-t-il sur sa decision une fois la modification faite ?
Merci
@cedric : si la baisse était vraiment due à l'incompatibilité mobile des pages, alors oui ça reviendra. Mais j'ai du mal à y croire car 1- le changement a eu lieu en avril, pas maintenant et 2- on n'a pas vu d'exemple de baisse importante. La "baffe SEO" est sans doute liée à un autre algo de Google.
Bonjour, tout d'abord un grand merci pour cet article !
J'ai une question, je voudrais savoir pourquoi mon site mobile (m.nomdedomaine.com) ressort sur desktop pour certaines requêtes, à la place de mon site desktop (www.nomdedomaine.com) :/ et comment empêcher ça ? Parce que ce n'est pas du tout pertinent de tomber sur le site mobile lorsque l'on navigue sur desktop, ça m'étonne que Google laisse passer ça...
Merci d'avance !
Marc
@Marc : peut-être que l'implémentation n'est pas 100% correcte ? Je veux bien connaître l'URL (en réponse par commentaire, que je ne publierai pas)
Mon site a passe le test responsive il y a plusieurs jours et toujours pas de label .?? J'ai lu que c'était instantané !
@donzac : quelle est l'URL de la page concernée ? a-t-elle bien été re-crawlée par Google ?
Il y a tablette et tablette, la résolution de l'Ipad mini implique une adaptation par rapport au desktop
La mention site mobile est bien là c'est très rapide
En revanche dans les GWT ils sont à la ramasse !!!!
pour GWT, il faut attendre que Google ait recrawlé les pages et mis à jour GWT, donc en effet il y a un délai
Merci pour votre réponse.
Merci pour votre article Olivier. Je remarque une accélération des messages d'erreurs dans les Webmaster Tools (message de type [WNC-451500]) lorsque des sites ne sont pas mobile-friendly, alors même qu'ils présentent une version mobile. Pensez-vous que la création d'un sitemap mobile pourrait satisfaire notre ami Google ?
Le site peut proposer une version mobile sans qu'elle soit compatible avec les exigences de Google. Un sitemap mobile ne me semble pas obligatoire, il faut simplement lancer l'outil de test sur certaines URL et suivre les conseils (ou consulter le rapport d'erreurs dans GWT).
Suite à l'annonce, on vient de passer 2 sites en responsive, tout du moins les 90% des pages les plus visitées. Les infos mises en avant ne sont plus forcément les mêmes et on s'est vraiment mis à la place d'un internaute sur PC et d'un internaute sur smartphone pour essayer de comprendre et de proposer la meilleure expérience utilisateur. Et qui dit expérience utilisateur, dit Panda... Donc passer par la case Mobile Friendly c'est aussi gagner des postions lors de la prochain maj de Panda.
Très bonne remarque Nicolas. C'est le cas depuis que Panda existe : en améliorant la satisfaction de l'internaute mobile sur votre site, vous améliorez votre "note selon l'algo Panda". Plus il y a d'internautes mobiles, plus c'est stratégique d'y penser. Y'a du boulot (en cours) pour WRI ;-)
C'est tellement difficile de faire comprendre à un développeur qu'il ne faut pas indexer la version mobile d'un site, qu'il est préférable de faire un site qui soit simplement responsive.
En plus ça coute moins cher en maintenance car on a qu'un seul site à maintenir...
Le thème de cet article fait partie des prédictions Seo 2015 de notre agence. Avec la croissance rapide des utilisateurs mobiles, Google n'a pas vraiment d'autre choix que de créer à terme deux index s'il souhaite continuer à "générer les meilleurs résultats pour les requêtes des utilisateurs" car les utilisateurs mobiles et les utilisateurs desktop n'ont pas les mêmes besoins en termes de navigation et de webdesign.
Sur quoi Google se base pour dire qu'un site est mobile friendly ou pas ?
En gros, que faut-il passer en priorité en responsive ? Sachant que je ne pourrais passer mon site 100% en responsive avant le 21 avril, selon vous, que faire ? Passer les catégories qui ont le + de pages ou celles qui ont le + de trafic ?
Le seul problème c'est que les critères mobile friendly de google ne tiennent pas la route :
- une page de 100km de long à scroll vertical : OK
- une page avec petit scroll horizontal : pas bon
- une page ou il faut zoomer sans scroll vertical ni horizontal : pas bon.
N'importe quoi !
Merci pour cet article ! Le truc le plus étonnant reste l'annonce de l'index mobile spécifique... Le référencement devient de plus en plus complexe avec plus de paramètres à gérer (géographie, réseaux sociaux, et maintenant adaptation aux terminaux de lecture)... En rendant le référencement naturel plus complexe, Google cherche-t-il à mettre en avant le référencement payant (même si celui-ci ne se prend pas en main en une heure non plus) ? Qu'en pensez-vous ?
Merci et comme d'habitude un super article et sans surprise d'en arriver là, nous sommes en 2015 tout de même.
Merci Xavier ! C'est vrai que j'ai pris soin de faire un article complet, mis à jour 2 fois de suite.
Bonsoir,
Bonne nouvelle, certains de mes concurrents ne sont pas compatibles mobiles :D
Ces décisions pointent des contradictions. Le responsive oblige a surcharger les pages en CSS. Donc des pages plus lourdes. Ce qui n'aide pas l'indexation.
Ensuite faire du 100 % responsive en Ecommerce, c'est impossible car il y a un passage par la banque et là personne n'a la main dessus... enfin sauf les très gros ecommerçants.
Avoir un site mobile ? un site unique en responsive design ou un site mobile dédié ? Google appréciera t-il les 2 formules. Lorsque le site internet classique existe, il est plus simple de faire un site plus light pour mobile...
Qu'en pensez vous ?
Dans les liens que j'ai donnés, Google rappelle qu'il existe 3 possibilités et qu'il recommande le responsive design.