
Le problème d'une meta robots noindex dans le corps d'une page HTML
Google tient compte du noindex en dehors de <head>
Je suis tombé sur ce conseil de Gary Illyes
Please be mindful with noindex directives and remember that most search engines will honour it, even if it's in the BODY element.

Il indique (rappelle pour certains d'entre nous) que Google tient compte d'une balise meta robots même si elle est placée en dehors de l'entête HTML (donc entre les balises <head> et </head>). Par exemple, si une page contient ceci quelque part entre <body> et </body>, alors Google ne l'indexera pas :
<meta name="robots" content="noindex">
Si jamais la page était indexée et qu'avec une mise à jour ce genre de balise est ajoutée, alors après le prochain crawl de Google, elle sera certainement désindexée.
Remarque : si besoin, relisez la syntaxe de cette balise et toutes ses valeurs possibles. Par exemple, le problème sera identique avec une balise meta robots "none".
Attention, on parle bien d'une balise intégrée dans le code HTML, pas du texte comme vous pouvez le lire ici dans mon article...
Google privilégie noindex à index si les 2 sont indiqués !

En règle générale, il n'y a pas de raison de fournir 2 directives contradictoires pour une même page, par exemple "index" et "noindex". Mais l'erreur est humaine ! Ceci peut très bien vous arriver un jour.
Selon John Mueller (source), Google utilise le paramètre le plus restrictif que vous avez sur la page :
- s'il y a à la fois "index" et "noindex", c'est "noindex" qui est pris en compte
- s'il y a à la fois "follow" et "nofollow", c'est "nofollow" qui est pris en compte
En plus, toujours selon lui, Google tient compte du code final obtenu après interprétation du Javascript au chargement de la page. Donc si un script JS modifie dynamiquement le HTML initial pour ajouter "noindex", alors Google considèrera que la page ne doit pas/plus être indexée.
Comment vérifier si vos pages ont ce problème
En lisant le début de cet article, vous avez sans doute eu le réflexe de penser que cela ne vous concerne pas, car quand vous avez besoin de cette balise, vous la mettez toujours dans l'entête HTML. Ceci suppose que vous ne faites jamais d'erreur, ni tous ceux qui interviennent sur votre site, ni tous les plugins, extensions et autres codes de votre CMS.
Si vous avez un doute sur une page précise, ouvrez le code HTML et cherchez si ce genre de balise se balade là où elle ne devrait pas.
Si vous souhaitez le vérifier sur 100% des pages de votre site, à moins d'avoir un petit site, je doute que la méthode manuelle vous plaise.
Je vous propose donc de tester mon outil RMTech qui fera ça fort bien (ainsi que plein d'autres choses d'ailleurs). Même la version gratuite vous alertera si vous faites de nombreux liens internes vers des pages pourtant interdites d'indexation. Seuls les changements faits en Javascript ne seront pas repérés.
Justement, une semaine avant le rappel de Gary sur ce sujet, un client de ma plateforme My Ranking Metrics a eu la surprise de constater que 98% des pages de son site ecommerce n'étaient pas indexables ! Autant vous dire que ce fut une surprise pour lui, en tout cas ce n'était pas voulu...
Il a été alerté par la synthèse de son rapport d'audit (version complète) :
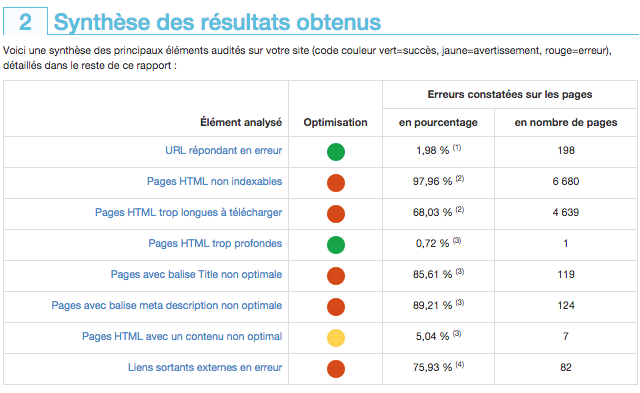
Ce problème est ensuite détaillé un peu plus bas :

Que certaines URL crawlées aient une autre URL canonique, pourquoi pas (encore qu'il y en a beaucoup dans cet exemple). Mais autant de pages interdites d'indexation, c'est louche !
Un clic sur le fichier annexe lui a permis de découvrir rapidement qu'une grande partie des pages (listings et fiches produits) étaient concernées. Concrètement, il avait justement lancé RMTech car depuis une semaine environ, son trafic SEO était en forte décroissance. Cela correspondait à une mise à jour de son site, mais il n'avait pas encore trouvé la cause du problème.
En fait, certains produits étaient mis en avant sous forme de vignettes, et au survol de la souris on disposait d'informations supplémentaires. Celles-ci étaient regroupées dans un <div> qui pour une raison obscure contenait une balise meta robots noindex. Voici un extrait de son code :

Il lui avait simplement fallu lancer lui-même l'audit SEO en ligne pour trouver le problème - et la solution. Les autres erreurs relevées par RMTech furent pour lui "du bonus", tout comme les suggestions d'optimisation.
Alors, qu'attendez-vous pour tester RMTech dès maintenant sur votre site, celui de vos clients ou même prospects ?
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Bonjour
Question qui semblera sans doute débile à un connaisseur, mais malgré moult recherches, je ne parviens pas à y répondre. Je précise que je suis débutant en matière de SEO, balises et autres joyeusetés.
Je veux éviter l'indexation de pages spécifiques de mon site (sur wordpress). Je vois à gauche et à droite qu'on conseille plutôt de rajouter une balise dans le code de la page. Très bien. Le hic, c'est que je ne pige par OÙ je peux ajouter une ligne dans le code.
Où je dois aller dans wordpress pour accéder au code de la page en question (je compte le faire pour plusieurs pages) pour pouvoir ajouter une ligne audit code, et sauver après.
Désolé pour cette question "mais c'est tout con, suffit de...", mais là je bloque. Bien à vous, M. Gérard
@Moger : WordPress ne permet pas de le faire sans ajouter un plugin... Un des plus connus, Yoast SEO, permet de le faire.
On est d'accord sur le principe. Prenons l'exemple du site de zalando, un exemple parfait de maitrise du référencement à mon sens. Pour les pantalons homme, il y a des dizaines de pages de produit, et on remarque que toutes les pages de 2 à 23 sont en Noindex, follow (sauf la 1 évidemment) pour éviter que le texte sur la page ne soit dupliqué.
OK, mais ça reste une mauvaise chose d'avoir plein d'URL en noindex, même de la pagination.
Bonjour,
Un site, comme un blog par exemple, peut détenir des centaines de pages. Surtout si des dizaines et des dizaines d'articles d'une catégorie se retrouvent en page 2, 3, 4.... Si le webmaster a décidé, pour éviter le DC, de placer ces pages 2, 3, 4 en noindex, follow, il se peut que le rapport d'audit montre effectivement un taux de pages non indexables très élevé, mais cela serait normal pour ne pas pénaliser son référencement non ?
En effet, dans ce cas il aura beaucoup de pages en noindex mais avant que ça ne représente un fort pourcentage de l'ensemble de son site, il y a de la marge normalement. D'ailleurs, il faut éviter la pagination car elle est très mauvaise pour le référencement.