

La question peut paraître étrange à certains, pourtant elle est pertinente 🧐
Vous devriez savoir combien vous avez de pages à crawler, a priori à faire indexer, pour ensuite vérifier combien d'entre elles Google a bien voulu indexer. Et au final pour savoir combien génèrent du trafic organique.
Inversement, ça vous aidera à identifier combien Google a indexé de pages qui n'étaient pas prévues. Ce qui génère de la masse noire ou même des pages zombies 🧟♀️
Bonus : ce guide vous explique aussi comment savoir le nombre d'URL à indiquer à des crawlers SEO comme RM Tech (mon outil d'audit de site). Ou savoir si vous avez assez de crédits pour le nombre d'URL à étudier.
Pas de panique, ce dossier est prévu pour tous publics, avec les définitions des termes utilisés. D'ailleurs, on va commencer par un point de vocabulaire...
Nombre de pages ou nombre d'URL ?
Cette distinction est très importante ! En effet, les moteurs fonctionnent par URL, la notion de "page" n'est pas assez précise. Si je prends l'exemple d'une page catégorie ecommerce où l'on vend des tables, son URL pourrait être :
https://example.com/tables
Si on trie par prix croissant, ça peut donner ça :
https://example.com/tables?sort=price&order=asc
Peut-être que les 2 cas affichent le même contenu, ou presque le même, mais ça fait 2 URL !
Et si on va sur la page 2, ça peut donner ça :
https://example.com/tables?page=2
C'est encore une autre URL ! OK, cette fois c'est pour un autre contenu que celui de la page 1, mais y aviez-vous pensé pour dénombrer les URL du site ?
Remarque : que les URL contiennent des paramètres (derrière le signe ?) ou pas (grâce à la réécriture d'URL), ça ne change rien au fait que ça fait plusieurs URL différentes.
A retenir : vous devez compter toutes les URL du site, pas les "pages".
OK, désormais on va pouvoir comparer les méthodes pour savoir combien il y a d'URL à crawler sur un site.
Les différents moyens d'estimer le nombre d'URL d'un site
Je vous présente un tableau pour avoir une vue d'ensemble, avec des explications sur les différences. Je m'intéresse ici uniquement à Google mais vous pouvez l'adapter à d'autres moteurs de recherche.
| Méthode | Contenus identifiés | Commentaires |
|---|---|---|
| commande site: | URL indexées par Google | utiliser la commande site: de Google est sans doute le plus simple et rapide, mais c'est trop imprécis et ne concerne que les URL indexées. Le nombre d'URL à crawler peut être bien supérieur (parfois aussi inférieur !) |
| sitemaps | URL listées par le CMS (ou l'outil qui a créé le/s sitemap/s | c'est une des meilleures méthodes à condition que le sitemap soit exhaustif et à jour. Attention, il oublie sans doute plein d'URL pourtant crawlables |
| contenus dans le CMS | pages, articles, produits, catégories | il faut tout additionner, et cette méthode oublie généralement des URL crawlables |
| rapport couverture de Search Console | pages indexées et non indexées | pas une bonne méthode pour dénombrer les URL à crawler car ça tient compte de tout l'historique du site, ça mélange plein de cas de figure (avec seulement 1000 URL d'exemples à chaque fois) et n'est pas toujours bien à jour |
| pages crawlées par RM Tech | URL autorisées au crawl trouvables en suivant les liens dans les pages (ainsi que les redirections et les URL canoniques) | indique le nombre exact d'URL trouvables pour un crawl à un instant T, mais ignore celles connues dans le passé ou celles trouvables depuis l'extérieur du site. Nécessite un crawl (sic) |
Le saviez-vous ? Vous pouvez lancer un audit RM Tech gratuitement, jusqu'à 10.000 URL seront crawlées. Donc si moins de 10.000 URL sont trouvées, c'est une excellente manière pour savoir exactement combien il y a d'URL à crawler. Pour cette version gratuite, vous aurez un rapport d'audit très restreint, sans accès aux fichiers annexes.
Compter ses URL est une chose, décider lesquelles méritent d'être indexées en est une autre. Toutes les pages d'un site n'ont pas vocation à apparaître dans Google. Voici comment trancher.
Crawl, indexation, trafic : ce n'est pas la même chose !
Voici quelques définitions importantes à savoir :
| Type d'URL | Explications |
|---|---|
| autorisées au crawl | URL que le fichier robots.txt n'interdit pas de crawler |
| crawlables | URL dont l'existence a été identifiée et qui sont autorisées au crawl |
| crawlées | parmi les URL crawlables, ce sont celles que l'outil a effectivement crawlées (si jamais il s'arrête avant la fin, il peut y avoir une différence) |
| indexables | parmi les URL crawlées, ce sont celles qui sont techniquement indexables (code HTTP 200, sans contradiction au niveau de l'URL canonique, sans interdiction d'indexation) |
| indexées | parmi les URL indexables, ce sont celles que Google a indexées |
| générant du trafic | parmi les URL indexées, ce sont celles qui ont généré du trafic (organique) sur une période d'étude |
| générant des conversions | parmi les URL générant du trafic, ce sont celles qui ont généré des conversions, par exemple des ventes sur un site ecommerce ou des leads sur un site de récolte de contacts commerciaux |
Si besoin, comprenez la différence entre interdiction de crawl et d'indexation.
Voir aussi : étapes à suivre pour faire indexer son site dans Google
Remarque : généralement, en SEO on s'intéresse uniquement aux pages HTML, car ce sont elles qui sortent dans les résultats de recherches (SERP). Mais une page HTML est constituée aussi de nombreuses ressources (images, CSS, scripts JS, polices de caractères...) qui peuvent aussi être crawlées. Si vous souhaitez compter les URL, il faut savoir s'il s'agit uniquement des pages HTML ou également des autres ressources. Pour cela, il faut se baser sur le type MIME.
Comme vous l'avez bien compris, il y a donc une notion d'entonnoir SEO qui s'applique. C'est pourquoi j'ai prévu dans mon outil RM Tech l'affichage d'un entonnoir dans chaque rapport d'audit. Voici à quoi il ressemble :
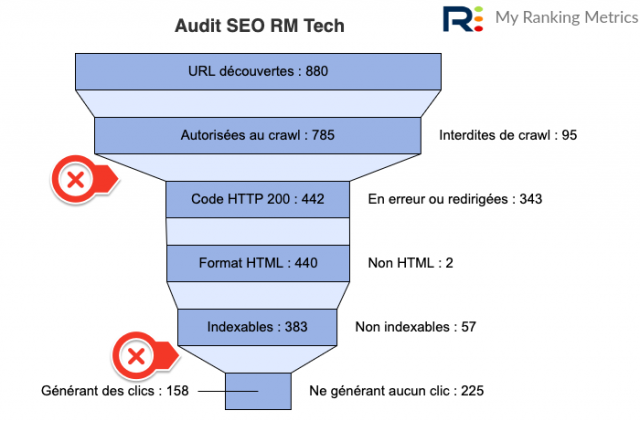
Je l'explique en vidéo :
Quelles pages faut-il vraiment référencer ?
Compter ses URL est une chose, décider lesquelles méritent d'être indexées en est une autre. Toutes les pages d'un site n'ont pas vocation à apparaître dans Google. Voici comment trancher.
Les critères pour décider qu'une page doit être indexée
Une page mérite d'être référencée si elle remplit ces conditions :
- Elle répond à une intention de recherche réelle : des internautes cherchent ce type de contenu sur Google.
- Elle apporte une valeur unique : son contenu n'est pas un doublon d'une autre page du site ou d'un contenu tiers.
- Elle est à jour et fiable : les informations présentées sont exactes et récentes.
- Elle est suffisamment étoffée : une page de quelques dizaines de mots sans contenu substantiel a peu de chances de se positionner.
Les pages à exclure de l'indexation
Certaines catégories de pages sont généralement mieux gérées avec une balise noindex (éventuellement aussi une règle dans le fichier robots.txt) :
- Pages de résultats de recherche interne (ex. :
/search?q=…) - Pages de tri et de filtres (ex. :
/chaussures?couleur=rouge&taille=42) - Pages de pagination au-delà de la page 1 (selon la stratégie choisie)
- Pages d'administration, de connexion ou de panier
- Pages au contenu trop faible ou dupliqué
Comment prioriser les pages à faire crawler selon vos objectifs
Si votre budget de crawl est limité (pour les grands sites), il vaut mieux concentrer les efforts de Google sur vos pages les plus importantes :
- Identifiez vos pages prioritaires : celles qui génèrent (ou pourraient générer) du trafic organique qualifié et des conversions.
- Assurez un maillage interne fort vers ces pages : plus une page reçoit de liens internes, plus Google la juge importante et la crawle fréquemment.
- Listez-les dans votre sitemap XML et n'y incluez que les pages que vous souhaitez voir indexées.
- Bloquez les URL parasites via
robots.txtounoindexpour ne pas diluer le budget de crawl.
Différences selon le type de site
| Type de site | Enjeu principal | Pages à surveiller en priorité |
|---|---|---|
| Blog / site éditorial | Contenu mince ou obsolète | Articles anciens peu lus, pages de tags, archives |
| E-commerce | URL en surnombre (filtres, tris, variantes) | Pages de filtres, pages produits hors stock, pages de pagination |
| Site vitrine | Peu de pages, mais qualité à soigner | Pages de services trop courtes, pages de mentions légales |
Questions fréquentes sur le comptage des pages d'un site
Je termine par les questions les plus souvent posées à ce sujet, notamment avec mon outil RM Tech... Contactez-moi si vous en avez d'autres.
Aucune méthode n'est parfaite, mais si vous avez un sitemap exhaustif, c'est un bon point de départ pour votre estimation. Si votre site fait moins de 10.000 URL, lancez un audit RM Tech gratuit et vous aurez l'information précise.
Oui, ces URL sont crawlées et donc comptées. La raison est simple : pour savoir qu'une URL est en erreur 404 ou pas, il est nécessaire de la crawler.
Si dans une page on trouve un lien vers une URL A qui en fait redirige vers une URL B, alors les URL A et B seront crawlées (soit 2 URL dans cet exemple).
Vous n'avez peut-être pas pensé aux URL de la pagination, aux URL des tris dans les listings, aux URL des variantes des fiches produits, etc. Vous avez peut-être aussi des erreurs techniques qui génèrent des contenus dupliqués internes, par exemple un / en fin d'URL ou pas, de la réécriture d'URL ou pas, une mauvaise gestion du sous-domaine www, des URL en HTTP et d'autres en HTTPS, des URL avec des majuscules et d'autres avec des minuscules, des URL avec du tracking interne, etc.
S'il y a moins d'URL qu'avec la commande site: ou que dans l'état de l'indexation (Search Console), il y a peut-être des pages orphelines. Cela signifie qu'il manque sur le site des liens vers ces URL (mais que ces liens existaient avant, ce qui a permis à Google de les trouver). Vous pouvez les trouver en faisant un audit RM Sitemaps couplé à un audit RM Tech. Autre raison possible : Google a suivi des liens situés ailleurs sur le web, pointant vers ces URL.
Voir aussi : meilleure structure d'URL en SEO
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.
