

En résumé :
- Principe : le moteur IA crée un éventail de sous-requêtes à partir de la question de l'utilisateur
- Impact SEO : on passe d'un modèle déterministe (classement stable) à un modèle probabiliste (présence dans un corpus temporaire)
- Le piège : ces requêtes n'apparaissent pas dans Gemini ou ChatGPT (ni dans votre Search Console)
- Action : identifier et travailler ces requêtes, structurer le contenu en "chunks" et utiliser la méthode FOX (intégrée à RM Console) pour détecter ces opportunités invisibles
Définition et origines : c'est quoi le "query fan-out" ?
Définition des requêtes fan-out
Les requêtes fan-out sont un ensemble de sous-requêtes synthétiques créées par un LLM à partir de la question de l'utilisateur. L'intérêt est de ne pas répondre bêtement mais d'anticiper tous les angles morts et les besoins de l'utilisateur. Le moteur IA construit ensuite un corpus personnalisé de documents qui vont servir à générer une réponse pertinente.
Exemple de requêtes fan-out
Si je demande ceci à Perplexity :
Je cherche des chaussures de running pour hommes avec un bon amorti et une bonne stabilité, quels sont les meilleurs sites pour en acheter avec des bons conseils ?
Avant de répondre, il fait ces recherches :
- achat chaussures running préférences
- sites ecommerce sport déjà utilisés
- préférences budget matériel sport
- habitudes running utilisateur
- meilleurs sites acheter chaussures running en ligne France conseils
- guides choix chaussures running pronation amorti stabilité
- avis sites i-run alltricks lepape ekosport running conseils
Le mécanisme de fan-out fait partie des premières étapes dans la réponse d'un moteur IA :
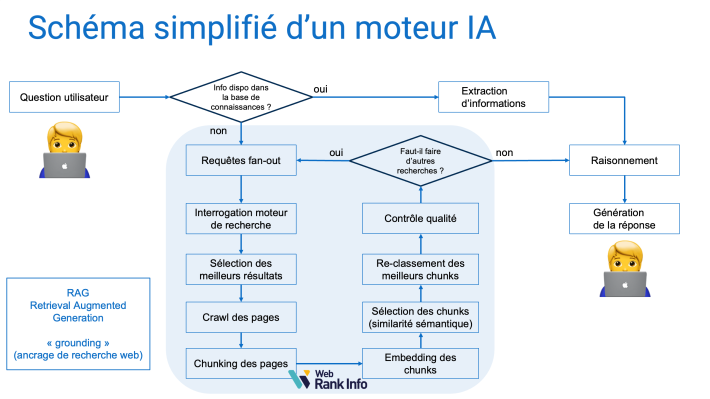
Les sources officielles
Pour bien comprendre où l'on va, il faut regarder d'où l'on vient. Ce concept n'est pas né avec la vague ChatGPT. Il trouve ses racines profondes dans les travaux de recherche de Google.
Je commence avec le plus simple : un article du blog de Google. En 2025, Google annonce une évolution des AI Overviews et l'arrivée de l'AI Mode. L'auteur explique :
[Google AI Mode] utilise une technique de "requêtes fan-out" qui consiste à lancer simultanément plusieurs recherches connexes sur des sous-thèmes et plusieurs sources de données, puis à regrouper ces résultats pour fournir une réponse facile à comprendre.
Robby Stein (VP of Product, Google Search), "Expanding AI Overviews and introducing AI Mode", 05/03/2025 (source)
Techniquement, la "query fan-out" (ou déploiement de requête) est donc une technique de décomposition.
Si l'article de blog de Google vulgarise le concept pour le grand public, c'est en analysant les brevets récents qu'on comprend réellement comment la mécanique du "Fan-out" est implémentée. J'ai épluché pour vous la documentation technique, et deux documents sortent du lot pour confirmer cette logique.
Le moteur de la diversification : les requêtes synthétiques
Le document le plus révélateur est sans doute le brevet WO2024064249A1, publié en mars 2024 (source). Même s'il ne contient pas l'expression marketing "Query Fan-Out", il décrit exactement le système qui le rend possible : "Systems and methods for prompt-based query generation for diverse retrieval" (Systèmes et méthodes de génération de requêtes basées sur des prompts pour une récupération diversifiée).
Concrètement, qu'est-ce que ça signifie pour votre SEO ?
- L'usage des LLM : Le brevet explique noir sur blanc l'utilisation d'un grand modèle de langage pour générer des données synthétiques. Google ne se base plus uniquement sur ce qui existe, il crée des variantes.
- La fin de la correspondance exacte : Le système utilise des prompts structurés pour créer des variations de la requête initiale (reformulations, expansions). L'objectif est clair : surmonter la "rareté des données" et aller pêcher des documents pertinents qui n'auraient jamais été trouvés avec une simple correspondance de mots-clés traditionnelle.
- Une diversification massive : Le brevet mentionne explicitement l'utilisation de 7 à 9 types de requêtes synthétiques (connexes, implicites, comparatives, etc.). Je les détaille plus loin.
💡 En résumé : Pour une seule requête tapée par l'internaute, Google en génère artificiellement près d'une dizaine d'autres pour scanner le web plus largement.
L'organisation des résultats : le "Thematic Search"
Générer des sous-requêtes, c'est bien, mais encore faut-il que les résultats soient lisibles pour l'utilisateur. C'est là qu'intervient un second brevet complémentaire, déposé fin 2024, intitulé "Thematic Search" (source).
Ce brevet agit comme le miroir fonctionnel du fan-out :
- Il identifie des thèmes (ou clusters) à partir des résultats remontés par les multiples requêtes synthétiques
- Il utilise l'IA pour générer des résumés pour chaque thème identifié
C'est la confirmation technique de la décomposition d'une requête unique en "sous-thèmes" (sub-themes). Google ne cherche plus une réponse unique, mais cherche à couvrir l'ensemble des intentions possibles liées à votre recherche.
⚠️ Mon conseil d'expert : Cette mécanique prouve une chose essentielle : optimiser une page pour un seul mot-clé précis est une stratégie dépassée. Vous devez penser en termes de couverture thématique globale. Si Google "éclate" la requête de l'internaute en 9 variations, votre contenu doit être assez riche (ou votre maillage interne assez puissant) pour répondre à ces variations.
L'objectif : réduire le "coût delphique"
Pourquoi Google déploie-t-il autant de puissance de calcul ? Pour réduire ce que les chercheurs appellent le coût delphique. C'est simplement l'effort cognitif que l'utilisateur doit fournir pour formuler la requête parfaite.
Au lieu de vous laisser taper 10 recherches successives pour planifier un week-end ("météo nice", "hôtel nice", "train paris nice"), le mécanisme fan-out anticipe et exécute ces 10 recherches simultanément pour vous servir une réponse consolidée. C'est un gain de temps phénoménal pour l'internaute, et un défi majeur pour le SEO.
L'analogie du buffet gastronomique
Voici une explication en image pour vulgariser ce changement de paradigme :
- SEO classique (les 10 liens bleus) : Vous commandez un plat au menu. Le serveur (Google) vous apporte 10 assiettes (10 URL) et vous choisissez la plus appétissante.
- Fan-out (Gemini, AI Overviews, AI Mode) : L'IA va au buffet à volonté. Elle prend une entrée chez l'un, un plat chez l'autre, un dessert chez un troisième. Elle compose une assiette unique et personnalisée censée correspondre aux attentes du client.
Votre contenu ne doit plus être le meilleur restaurant. Il doit être le meilleur mets sur ce buffet pour avoir une chance d'être un plat sélectionné. Encore mieux, vous devez être sélectionné pour le plus de plats possible. Ici, chaque plat est un morceau de page, ce qu'on appelle "chunk".
L'analogie du rédacteur en chef
Imaginez l'IA comme un rédacteur en chef exigeant. Il reçoit un sujet (la requête utilisateur) et envoie 10 journalistes d'investigation (les requêtes fan-out) sur le terrain. Votre but est d'identifier quelles questions ces journalistes posent, pour être sûr d'être l'expert qu'ils vont interviewer.
Mécanique interne : comment s'exécute le fan-out ?
J'ai analysé le mécanismes fan-out pour différents moteurs IA. Je vous résume ici ce que j'ai appris.
Processus de "query expansion" et exécution parallèle
Le LLM analyse le prompt initial et lance un processus de query expansion. Il ne cherche pas juste dans l'index web classique. Par exemple, Gemini orchestre une exécution parallèle sur plusieurs sources de données :
- L'index web : Pour les articles et contenus textuels.
- Le Knowledge Graph : Pour les entités (personnes, lieux, faits établis).
- Google Shopping / Merchant Center : Pour les produits et prix en temps réel.
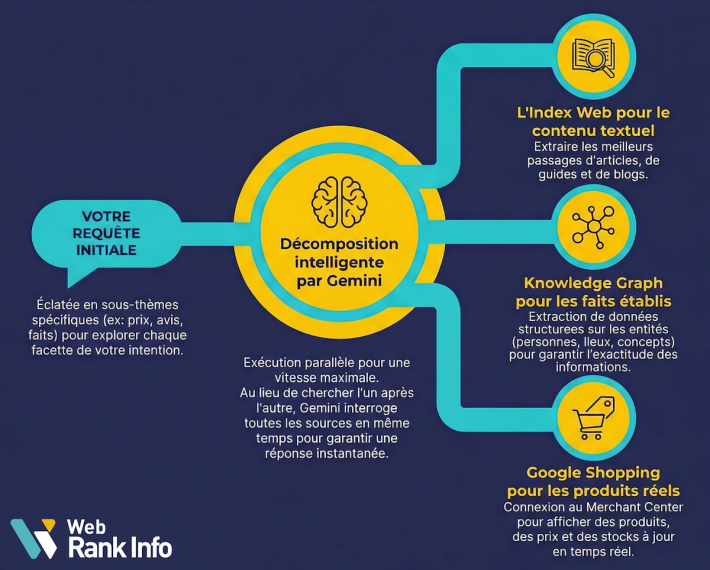
Bien entendu, chaque LLM se débrouille pour effectuer les requêtes sur les moteurs de recherches et sources à sa disposition.
Comparaison du fan-out selon les moteurs IA
Ce n'est pas de la théorie abstraite. Quand on met les mains dans le code, on voit des choses très concrètes :
- Sur ChatGPT : On peut voir les traces de ces requêtes fan-out directement dans le code JavaScript lors de la génération de la réponse. C'est d'ailleurs ce qui permet à certaines extensions Chrome malines de les "sniffer" assez facilement. Ces requêtes sont ensuite effectuées sur un ou plusieurs moteurs de recherche (rien d'officiel ici).
- Sur Gemini : Je constate que Gemini effectue beaucoup plus de requêtes fan-out que son concurrent. Ce n'est pas étonnant : Gemini joue à domicile. Il profite de son accès direct et illimité à l'index de Google pour multiplier les vérifications.
- L'évolution Gemini 3 : Mes derniers tests montrent que les versions les plus récentes (comme Gemini 3 Pro) poussent cette logique encore plus loin, avec un volume de sous-requêtes impressionnant. Cela apporte des informations plus juste et réduit les hallucinations.
Du "classement" au "corpus personnalisé"
Le résultat de ce fan-out n'est pas une page de résultats (SERP). Le moteur récupère des "shards" (des éclats d'information). On parle aussi de chunks ou de passages. Ils sont assemblés pour former un "corpus personnalisé" temporaire.
⚠️ Attention : Ce corpus devient une source majeure de la réponse générée. Si vos contenus ne sont pas récupérés lors de cette phase d'extraction, vous serez probablement invisible pour l'IA.
Typologie des requêtes fan-out générées
Quelles sont ces requêtes que l'IA génère à votre place ? J'en ai identifié plusieurs types, voici mon bilan.
Les catégories de requêtes fan-out
Voici les types de requêtes générées par la technique de Query Fan-Out, que j'ai trouvés dans le brevet PROMPTAGATOR (WO2024064249A1).
| Type de requête | Description |
|---|---|
| Requêtes de reformulation Reformulation Queries | L'IA réécrit la question en utilisant des synonymes, des tournures de phrases différentes ou un registre de langue varié (ex: langage courant vs formel) pour trouver des documents pertinents qui n'utilisent pas vos mots-clés exacts. |
| Requêtes connexes Related Queries | L'IA cherche des sujets "voisins" ou sémantiquement proches dans le Knowledge Graph. Elle élargit la recherche aux concepts qui accompagnent souvent le sujet principal (ex: chercher des accessoires quand vous cherchez un produit). |
| Requêtes implicites Implicit Queries | L'IA devine ce que l'utilisateur n'a pas dit explicitement. Elle déduit son intention réelle ou son besoin latent (le pourquoi de la recherche) et formule des requêtes pour y répondre directement. |
| Requêtes comparatives Comparative Queries | Si l'IA détecte une hésitation ou un besoin de choisir, elle génère des requêtes "Versus" (A vs B) ou cherche des tableaux comparatifs pour aider l'utilisateur à prendre une décision, même s'il n'a pas demandé de comparaison. |
| Requêtes étendues par entité Entity-Expanded Queries | L'IA remplace des termes génériques de votre phrase (comme "voiture" ou "téléphone") par des noms précis de marques, de modèles ou de produits identifiés dans sa base de connaissances pour obtenir des résultats plus concrets. |
| Requêtes de contre-argument Counter-Argument Queries | Spécifiquement mentionné dans le texte du brevet pour les sujets de débat, ce type cherche délibérément des preuves qui réfutent une affirmation ou présentent un point de vue opposé pour assurer une réponse équilibrée. |
D'autres brevets mentionnent d'autres types de requêtes fan-out, que je préfère séparer. En effet, pour savoir les générer, il faut disposer des données liées à l'utilisateur. Donc seul un moteur IA peut le faire, pas un outil (ou vous !)...
| Type de requête | Description |
|---|---|
| Requêtes personnalisées Personalized Queries | Variations basées sur le profil unique de l'utilisateur (intérêts, localisation, historique) injectées dynamiquement via des vecteurs de contexte Brevets : US20240289407A1, WO2025102041A1 |
| Requêtes récentes Recent Queries | Exploitation de la mémoire à court terme (session active) pour affiner la recherche actuelle en fonction des questions posées juste avant. Brevet : US20240289407A1 |
Comment voir et récupérer les fan-out ?
Si la Search Console est aveugle, comment travailler ? Il faut ruser avec ma méthode FOX 🦊
Récupérer les requêtes fan-out de ChatGPT
Sur la version web de ChatGPT, les requêtes fan-out sont explicitement renvoyées dans les métadonnées de la réponse JSON :
- Identifiez le point de terminaison
backend-api/conversation - Lisez la valeur du champ
search_model_querieset vous y trouverez les recherches effectuées
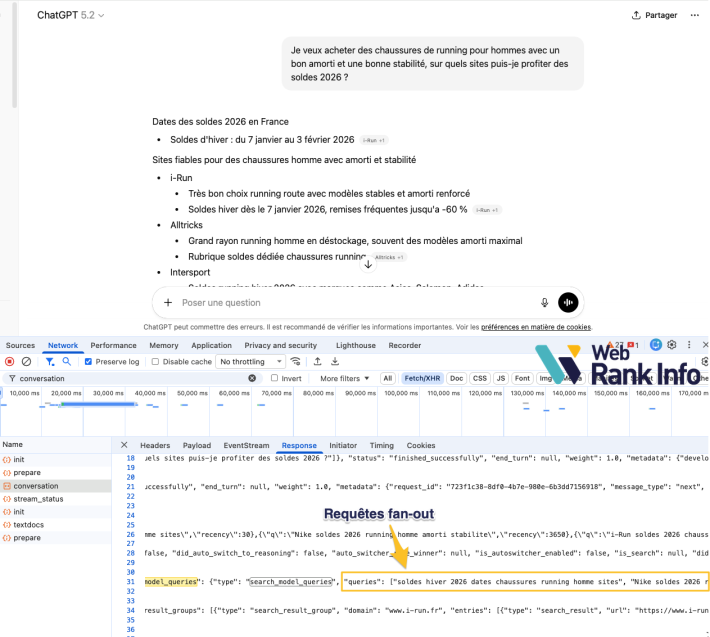
Il existe de multiples extensions Chrome permettant de simplifier cette récupération.
Mais ça reste du bricolage ! Vous ne récupérez que ce que vous avez vous-même cherché avec votre compte. Vous pouvez tenter d'envoyer des prompts en mode batch, mais soyons sérieux...
Récupérer les requêtes fan-out de Perplexity
Perplexity affiche les requêtes dans l'interface :
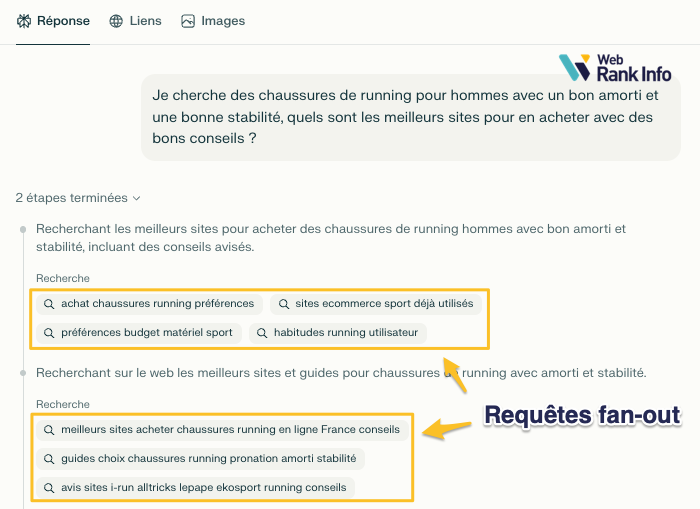
Récupérer les requêtes fan-out de Gemini
Sur Gemini c'est impossible de récupérer les requêtes fan-out par du scraping sur la version web. Gemini ne les envoie pas directement via le navigateur.
La seule façon de récupérer les fan-out de Gemini, c'est avec l'API. Voici ce qu'on peut obtenir comme réponse :
'webSearchQueries': ['dates soldes hiver 2026 France','sites vente en ligne chaussures running spécialisés','soldes chaussures running homme amorti et stabilité 2026','meilleurs modèles chaussures running stabilité et amorti 2025 2026']
Solution simple et efficace : méthode FOX 🦊 avec RM Console
Pour ne pas y passer mes nuits, j'ai intégré tout ça dans mon outil RM Console.
Cet outil fait le travail de reverse-engineering pour vous. Il récupère toutes les fan-out pour les questions de votre choix, sur les modèles sélectionnés de ChatGPT et Gemini.
L'outil utilise l'API avec le grounding activé : les données sont officielles, garanties.
Encore plus malin 🦊 : avec la méthode FOX directement dans RM Console, l'outil vous aide à identifier les requêtes à exploiter. Ces "trous dans la raquette" deviennent de formidables opportunités pour votre contenu actuel.
La méthode FOX permet d'optimiser aussi bien le GEO que le SEO. Pour chaque étape, l'outil vous assiste :

Voici mes explications en vidéo :
Stratégie GEO : optimiser pour le modèle probabiliste
Le SEO change de nature. Nous passons d'un modèle déterministe (je place mon mot-clé = je me classe) à un modèle probabiliste (j'augmente mes chances d'être sélectionné dans le corpus).
Mentalité "répondre à une facette"
Pour s'adapter, il faut abandonner les pages généralistes "fourre-tout". Vous devez adopter une approche modulaire. Chaque contenu doit répondre parfaitement à une facette spécifique du problème.
Structuration en chunks
L'IA consomme des chunks (passages autonomes dans une page). Votre contenu doit être découpé (par exemple avec des titres H2/H3 explicites) pour que chaque section puisse être extraite et comprise hors de son contexte global. C'est la condition sine qua non pour être "citable".
Alignement des embeddings
C'est un peu technique, mais crucial : le texte de vos chunks doit être sémantiquement proche des requêtes fan-out cachées. On parle d'alignement des vecteurs (embeddings). Si votre vocabulaire est trop éloigné de la manière dont l'IA formule ses sous-requêtes, la similarité vectorielle sera trop faible, et vous ne serez pas récupéré.
Le gain d'information
Ce n'est pas fini ! Pour être sélectionné, vous devez apporter une valeur ajoutée. Si vous répétez ce que disent Wikipédia et les 3 premiers concurrents, votre "gain d'information" est nul.
Fournissez des données uniques, des avis d'experts, des chiffres récents. C'est valable avec Google (SEO classique) et encore plus avec les IA (LLM).
Conclusion et plan d'action
Les requêtes fan-out sont le cœur du réacteur des moteurs de recherche modernes. Les ignorer, c'est accepter de disparaître progressivement des résultats au profit de ceux qui nourrissent l'IA.
Votre plan d'action immédiat :
- Arrêtez de piloter uniquement avec la Search Console (elle ne voit pas le fan-out)
- Utilisez des outils capables de cartographier ces nouvelles requêtes pour savoir sur quoi écrire
- Auditez vos pages clés avec une logique de chunking, de contenu "citable" et de "gain d'information"
Besoin d'aller plus loin ?
- Pour une stratégie sur-mesure, contactez-moi pour une mission de conseil
- Pour détecter vos opportunités fan-out, lancez un audit de visibilité IA dans RM Console
On discute des requêtes fan-out dans le forum.
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Super complet. Je remarque sur ChatGPT utilise beaucoup de Fan out en anglais. Traduire son site devient très interessant d'après moi.
Concept interessant ces requetes fan-out. Ça explique pourquoi les contenus très structures et bien segmentés performent mieux avec les IA. Le défi maintenant c'est d'optimiser à la fois pour le crawl classique et pour cette logique de décomposition des requêtes.