
Pourquoi le crawl ("exploration" selon le terme français utilisé par Google) est-il si important pour votre référencement ?
Car pour qu'une page de votre site sorte bien dans Google, elle doit être indexée (et mise à jour) et donc être crawlée rapidement/souvent (dès qu'elle est publiée ou mise à jour).
Google ne pouvant pas crawler une infinité de pages par jour, il y a des limites quelque part. Dans ce dossier, je vais vous expliquer ce qu'on entend vraiment par "budget de crawl" et ce que ça signifie officiellement pour Google.
Mais surtout, je vais vous donner des astuces et vous suggérer des outils pour que le crawl de Googlebot soit hyper efficace sur votre site !

Le budget de crawl de Google
Le robot de Google, nommé Googlebot, passe son temps à explorer des URL : il n'est pas aux 35h, plutôt du genre 24h/24 365j/an ;-)
Un vrai glouton !
Mais concrètement, il a + de pages à récupérer sur certains (énormes) sites et ne semble pas aimer tous les sites au même niveau. Bref, tous les sites ne semblent pas traités de la même façon.
En fait, la première notion à bien comprendre, c'est que Googlebot cherche à ne pas atteindre les limites de votre serveur. Dès qu'il se rend compte que son activité commence à dégrader l'expérience utilisateur des internautes qui le consultent en même temps, il réduit sa fréquence de crawl.
J'imagine qu'il conserve une sorte de moyenne pour chaque site, et qu'il l'adapte à la situation en temps réel. C'est plutôt bon signe non ? En fait ça dépend comment on voit les choses :
- si votre serveur n'est pas assez "costaud", ça n'est pas grave puisque Google ne le sollicitera pas trop et donc les internautes pourront malgré tout le consulter sans problème
- OK mais dans ce cas Google va réduire le nombre d'URL explorées, si bien que l'indexation des nouvelles pages (ou la mise à jour des anciennes) sera ralentie
Les 2 critères de Google pour la vitesse d'exploration
Sur quoi Google se base-t-il pour estimer les capacités d'un serveur web ? 2 éléments principalement :
- le nombre de connexions simultanées possibles
- le temps qu'il doit attendre entre 2 crawls
En fonction de ça, Google établit donc une vitesse d'exploration maximale. Celle-ci peut donc augmenter ou diminuer en fonction de ces deux facteurs :
- L'état de l'exploration : si le site répond très rapidement pendant un certain temps, la limite augmente, ce qui signifie que davantage de connexions peuvent être utilisées pour l'exploration. Si le site ralentit ou répond par des erreurs de serveur, la limite diminue et Googlebot réduit son exploration.
- La limite définie dans la Search Console : si vous avez un accès de niveau "propriétaire" dans Search Console, vous pouvez réduire l'exploration de votre site par Googlebot (détails ici). Sachez que définir une limite plus élevée n'entraîne pas nécessairement une augmentation de l'exploration. A l'inverse, j'espère que vous n'aurez pas besoin de la réduire : il vaut mieux optimiser la vitesse de votre site.
Je vais donc vous montrer comment tester le crawl de Google, soit sur l'ensemble de votre site, soit sur une page en particulier.
Comment savoir combien Google crawle d'URL par jour sur un site ?
La façon la plus détaillée est certainement de faire une analyse de logs (vous trouverez plein d'outils sur Google).
Mais vous pouvez aussi obtenir cette information tout simplement dans Search Console, rubrique Exploration > Statistiques sur l'exploration. Celle-ci affiche des graphiques de ce genre :
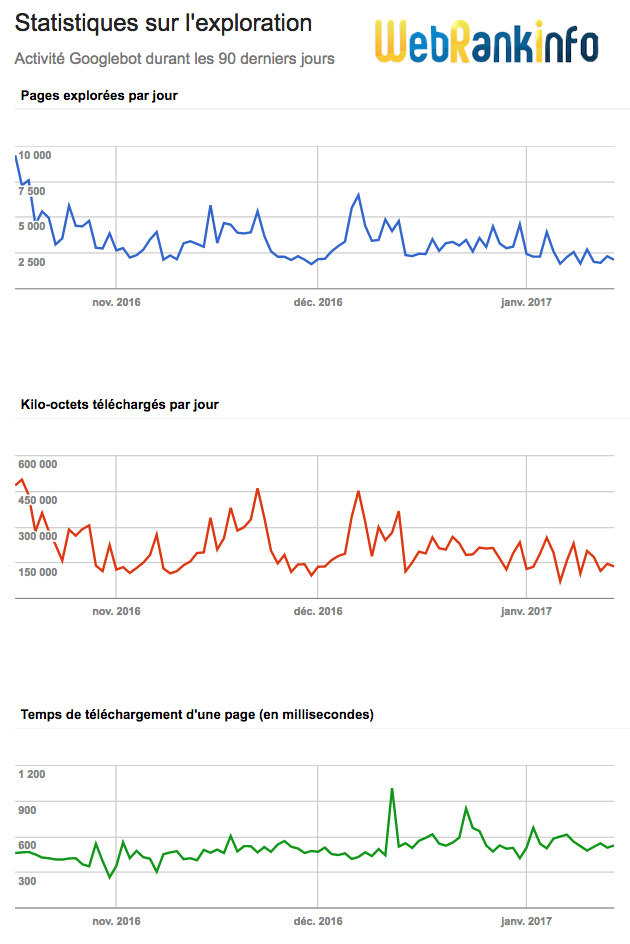
Le premier graphique (en haut) indique le nombre d'URL explorées par Googlebot pendant les 90 derniers jours pour la propriété concernée de Search Console (un seul sous-domaine, un seul protocole). Ceci concerne tous les types de documents crawlés par Google, pas seulement les pages HTML.
Selon les sites et les périodes, vous pouvez voir des courbes "plates" ou des gros pics ou creux...
J'explique justement dans la suite de ce dossier ce qui influe sur le crawl de Google.
Mais avant ça, voyons comment évaluer le crawl sur une page précise.
Comment tester le crawl d'une seule page par Google ?
La méthode que je vous recommande, c'est de demander à Google de venir crawler l'URL à tester. Pour une fois que vous pouvez lui ordonner quelque chose, profitez-en !
Voici comment tester le crawl Google d'une page et demander une indexation :
- Rendez-vous dans votre compte Search Console (nouvelle version)
- Dans le formulaire en haut d'écran ("inspecteur d'URL), indiquez l'URL et validez
- Si Google affiche "Cette URL est sur Google" alors l'URL testée est déjà indexée par Google.
- Si Google affiche "Cette URL n'a pas été indexée par Google", vous pouvez forcer le référencement de votre page en cliquant sur "Demander une indexation". Vous n'avez pas la garantie que Google l'indexera, mais bien souvent c'est fait en quelques minutes.
Une fois que Google a crawlé la page, vous pouvez obtenir des informations sur la "couverture" (pour savoir si elle a été indexée, avec quelle URL canonique, ou pourquoi elle n'a pas été indexée) et sur les "améliorations".
Pour analyser dans les détails, cliquez sur "Afficher la page explorée". Un panneau latéral s'affiche avec plusieurs onglets :
- "HTML" contient le code HTML récupéré par le robot de Google
- "Capture d'écran" affiche le rendu de la page tel que Googlebot a pu le construire (vous aurez besoin de cliquer d'abord sur "Tester l'URL en ligne")
- "Plus d'infos" précise :
- le code de réponse HTTP (et tous les entêtes si vous cliquez sur la ligne). Le code HTTP doit être 200 (ce qui signifie OK, voir ici la signification des codes HTTP)
- ressources de la page : liste des ressources que Google n'a pas pu récupérer
On a vu comment savoir combien Google crawle de pages par jour, et combien de temps il met à en crawler une. Voyons maintenant les détails...
Comment savoir quelles pages sont lentes à crawler ?
Je le vois souvent dans mes audits, certains types de pages peuvent être bien plus lentes à être téléchargées, par exemple les pages de listings (catégories) ou les fiches produits complexes.
Ce n'est pas l'analyse d'une seule page qui va vous le révéler (c'est trop fastidieux)...
Ce n'est pas non plus l'étude du 3ème graphique "Temps de téléchargement d'une page" fourni par Search Console qui donne la réponse.
Vous pouvez obtenir ce type d'infos avec un crawler, par exemple Xenu si vous êtes sous Windows, ou avec un crawler SEO comme RM Tech.
En voici un extrait :
Lancez un audit RM Tech, le rapport d'audit donne plusieurs tableaux dont un bilan de ce type :
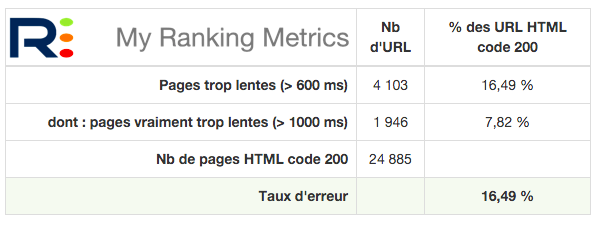
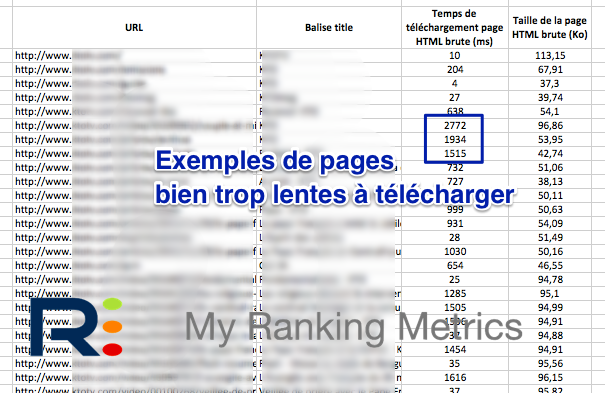
Bien entendu, les fichiers Excel (ou CSV) donnent tous les détails. Par exemple pour un site audité cette semaine, qui avait des temps de téléchargement très longs, j'ai identifié de grandes disparités selon les types de pages. Grâce à cette info, le client a pu corriger les problèmes bien plus rapidement.
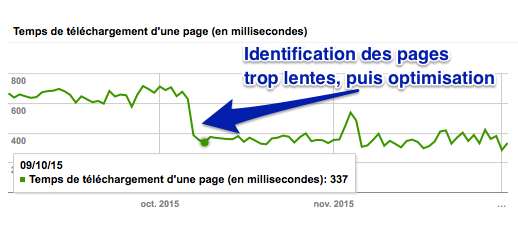
Une fois que vous avez identifié les pages trop lentes, vous pouvez agir afin d'accélérer votre site. Vous aurez alors peut-être le même graphique Search Console que celui de ce client :
Impact SEO
Pourquoi faut-il optimiser son crawl ?
Si vous lisez un peu trop vite les réponses de Google sur la notion de Crawl Budget, vous pouvez avoir l'impression que ce n'est absolument pas un problème, que votre site n'est sans doute pas concerné, peut-être même que ce "budget d'exploration" est un mythe inventé par les SEO.
Pourtant, dans la pratique c'est très différent, croyez-en mon expérience (je joue avec le SEO depuis que Google existe, mes débuts remontent à 1997...).
Concrètement, toutes vos pages ne seront pas crawlées par Google aussi souvent que vous le souhaiteriez. En conséquence, cela peut gêner votre référencement :
- pour faire découvrir très rapidement des nouvelles pages qui viennent d'être mises en ligne
- pour faire mettre à jour une grande quantité de pages sur lesquelles vous venez de faire une optimisation (par exemple l'ensemble de vos fiches produits)
Vous allez également découvrir plus loin dans mon article que votre site contient sans doute de la masse noire ! Ce n'est pas de la pollution classique, mais il vaut mieux s'en débarrasser malgré tout...
2 critères importants pour augmenter le crawl de Google
Google se base sur un ensemble de critères (techniques pour la plupart) pour décider quelles URL crawler, ainsi que dans quel ordre. D'après Google, les 2 facteurs importants sont les suivants :
- la popularité : les URL les plus populaires sur Internet ont tendance à être explorées plus souvent pour être le plus à jour possible dans l'index de Google. Une façon pour Google d'évaluer cette popularité est de calculer le PageRank, ce qu'il continue sans doute à faire même s'il ne communique plus sa valeur. Et vous ? Pour une évaluation du PageRank, utilisez des outils d'analyse de backlinks (par exemple Majestic, Ahrefs, Moz). Renseignez-vous aussi sur le calcul du PR interne.
- l'obsolescence : Google cherche à empêcher que les URL ne soient pas actualisées dans l'index. Donc de votre côté, vous avez intérêt à mettre à jour le contenu de vos vieilles pages pour redonner un coup de boost à votre crawl.
Je vais vous donner d'autres astuces pour faire crawler des URL, mais revenons juste sur ces 2 points officiels.
Pour que Google crawle souvent les pages stratégiques de votre site, il faut donc qu'elles aient un bon PageRank. Cela passe par l'obtention de bons backlinks issus d'autres sites (c'est le top !) mais aussi par un bon maillage interne. Vérifiez donc que ces pages-là :
- soient très faciles d'accès sur votre site (1 clic a priori ou peut-être 2 au maximum, vu qu'il s'agit des pages les plus stratégiques)
- aient plusieurs liens entrants internes (ceci favorise le crawl)
Si vous gérez un site vitrine vous devriez pouvoir le faire manuellement, mais si le site contient des centaines de pages ou beaucoup plus, ça devient difficile sans outil. Pour le vérifier sur l'ensemble de votre site, je vous suggère de tester mon outil RM Tech, il fait ça parmi des dizaines d'autres analyses !
Remarque : vous pouvez tester gratuitement l'audit RM Tech sur le site de votre choix, vous aurez un rapport gratuit très complet. Pour avoir le détail des URL à corriger, vous devrez utiliser des crédits (payants).
Autre moyen d'augmenter le crawl Google
Une façon simple d'inciter Google à crawler plein de pages, si vous ne l'avez pas encore testée, c'est tout simplement de lui fournir un fichier sitemap listant toutes les URL concernées (tout le site si besoin).
Si vous ne l'avez pas encore fait, vous devriez voir une forte augmentation du crawl dans les jours qui suivront. Par contre, si vous aviez déjà déclaré le sitemap, çà n'aura pas d'impact majeur.
Il y a au moins un autre cas où Google augmente fortement (mais temporairement) le crawl, c'est lors d'un changement de nom de domaine (quand vous prévenez Google via Search Console).
Google ne veut pas toujours crawler/indexer 100% du site !
A part si vous avez un petit site (moins de 100 pages environ), sachez qu'il n'est pas garanti que Google crawle et surtout indexe toutes vos pages. D'ailleurs j'en discute dans un article sur le taux d'indexation des URL d'un sitemap. Je cite Google :
En associant la vitesse d'exploration et le besoin d'exploration, nous définissons le budget d'exploration comme le nombre d'URL que Googlebot peut et veut explorer.
Conclusion :
On se rapproche de mon histoire de "masse noire"...
6 raisons qui plombent le crawl de votre site
C'est là que ça devient vraiment intéressant, car trop peu de monde en a bien conscience...
Voilà exactement ce qu'explique Google :
D'après nos analyses, la multiplication d'URL à faible valeur ajoutée peut nuire à l'exploration et à l'indexation d'un site.
C'est pour cette raison (confortée par mon expérience) que j'ai développé un algorithme spécifique pour tenter de repérer les pages à faible valeur ajoutée. Il s'agit de l'algo QualityRisk, inclus dans l'audit RM Tech.
Je continue, voici les 6 principales raisons qui freinent le crawl de votre site, selon Google :
D'après ce que nous avons pu constater, les URL à faible valeur ajoutée entrent dans ces catégories, par ordre d'importance :
- Navigation à facettes et identifiants de session
- Contenu en double sur le site
- Pages d'erreurs "soft 404"
- Pages piratées
- Espaces infinis et proxys
- Contenu de mauvaise qualité et spam
Voici mes commentaires :
- la navigation à facettes fait partie des choses les plus complexes à bien maîtriser d'un point de vue référencement ; si vous ne connaissez pas assez bien, mieux vaut bloquer tout le crawl des URL générées
- faites en sorte que Googlebot n'ait pas d'identifiants de session quand il vient crawler votre site ; si besoin, sachez que mon outil RM Tech le vérifie
- les contenus dupliqués gênent le crawl et l'indexation : évitez les erreurs classiques de DC interne, et vérifiez avec RM Tech que vous n'avez pas de DUST (Duplicate URL Same Text)
- les pages d'erreurs soft 404 ne sont généralement pas difficiles à repérer et éviter
- si par malheur votre site est piraté, surveillez votre email car Google devrait vous prévenir par le biais de votre compte Search Console
- évitez à tout prix les redirections en boucle, ça provoque des schémas de crawl infinis ! RM Tech les repère...
- enfin, le dernier point est plus complexe car pas seulement technique : assurez-vous de ne pas faire indexer (trop) de pages de mauvaise qualité sur votre site !
Tous ces points sont vraiment importants à comprendre et corriger, car comme le dit Google :
Gaspiller inutilement des ressources du serveur pour des pages de ce type détournera l'activité d'exploration de pages qui ont réellement de la valeur, ce qui peut considérablement retarder la découverte de contenu intéressant sur un site.

Evitez la masse noire !
Je pense que vous l'avez deviné, ce que j'appelle la masse noire est l'ensemble des URL que vous ne devriez pas faire indexer à Google, qui ne devraient même pas être crawlées et souvent pas même exister.
Pour être plus précis, celui qui a inventé ce terme c'est Fabien, cofondateur de Ranking Metrics et formateur SEO avec moi depuis 2005...
Il existe plein de cas de figure qui génèrent de la masse noire sur un site. Que ce soit dans mes audits ou en formation, j'ai très souvent vu des cas où :
- Google indexe trop d'URL par rapport à ce qui existe réellement
- et crawle vraiment beaucoup trop d'URL
Imaginons un site avec 300 pages de vrai bon contenu.
- En théorie, Google devrait indexer 300 pages, mais en pratique celui qui gère le site ne maîtrise pas tout et génère beaucoup de masse noire.
- En conséquence, Googlebot "se prend dans les pieds" 15.000 URL qu'il crawle plus ou moins fréquemment.
- Parmi ces 15.000 URL, Google tente de repérer les 300 bonnes, mais n'en repère que 200 (c'est déjà pas mal) et se trompe sur 800 autres.
- Résultat : 1000 URL sont indexées, dont 800 de mauvaise qualité.
- Au final, les algos de Google estiment que ce site est de qualité moyenne et le crawl n'est pas efficace...
Si vous avez des questions, n'hésitez pas à les poser dans les commentaires ou bien dans le sujet du forum : le budget de crawl de Google.
Source : Google
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Bonjour,
Concernant le DP interne, j'ai un jour modifié des URL sur mon site ce qui a créé du contenu dupliqué. Les anciens formats d'URL finissent à la manière des 404 par être désindexés ? Et au lieu de créer des redirections 301, je peux tout simplement faire une demande de suppression? Je compte ranker numéro 1 mais je ne compte pas garder ce site plus 6 mois après. Merci.
Pour réussir en référencement, il faut se donner toutes les chances, donc ne pas casser les URL comme ça... Dans ce cas de figure, je conseille de faire des 301. Sinon les anciennes URL (en 404) pourraient mettre des semaines ou des mois à être désindexées.
Ok je vois, autrement j'ai 2 URLs pour ma page d'accueil, dont l'une d'entre elles est redirigé vers l'autre. Le problème, c'est que Google à mis l'URL rediriger en erreur sur la search console à cause, je suppose de la chaîne de redirection qui est trop longue. Que suggéré vous de faire dans ce cas là s'il vous plaît ?
Peut-être que je dois rediriger l'URL en erreur de ma page d'accueil vers une page 404?
Il faut arrêter de faire des liens vers la mauvaise URL de page d'accueil, rediriger la mauvaise URL en 301 vers la bonne, et patienter.
Au passage, la bonne URL est censée être / tout court.
Merci pour l'article. Que pensez-vous de la navigation en ajax pour gérer le problème des filtres à facettes ? Serait-ce efficace de coupler cette technique au blocage via le fichier robots.txt ? ou bien il est préférable d'utiliser l'une des méthodes ? M
Si le code AJAX n'est pas vu par Google, alors oui ça permet d'éviter de perdre du budget de crawl.
Merci pour l'article !
Concernant le cas d'une pagination, /recherche ; /recherche?page2 ; /recherche?page3...
Et
Concernant le cas des filtres, /recherche; /recherche?prixasc; /recherche?prixdesc; ...
Conseilleriez-vous de mettre toutes ces urls en Noindex ? D'ailleurs, le noindex réduit-il le budget crawl (réduit = permet de le concentrer sur les autres pages que nous voulons voir crawlées).
Merci pour votre réponse,
Pour la pagination, il est nécessaire de laisser Google crawler les pages, car elles servent à faire des liens vers des pages de détails (articles, annonces, produits). Une optimisation de la pagination peut néanmoins permettre de limiter le nb total d'URL à crawler et donc exploiter au mieux le budget de crawl.
Pour les tris (par exemple par prix, ascendant ou descendant) : je déconseille non seulement de les faire indexer, mais aussi de les faire crawler.
Mettre en noindex n'a pas de rapport avec le crawl, donc ça ne réduit pas le budget crawl pour répondre à la question.
Bonjour Olivier,
Je vous remercie pour cette réponse très claire.
Mais, du coup, comment puis-je empêcher le crawl si le noindex (qui doit peut-être réduire un peu la fréquence du crawl ?) ne le permet pas ?
Merci,
Pour empêcher le crawl il faut utiliser le fichier robots.txt, comme je l'explique aussi plus en détails dans ce tuto crawl et SEO
On ne peut pas faire plus clair ! Merci !
Encore un article au top.
Le sitemap.xml possède une date et heure pour un contenu. Peut-on considérer que Google prend en compte les modifications de cette date/heure pour un contenu déjà indexé et fait en sorte de repasser son bot sur le contenu modifié ?
Je pense que Google se base surtout sur les heures/dates de son crawl, tout en évaluant ce qui a vraiment changé dans le contenu depuis la fois précédente.
Bref, pour ma part je ne m'intéresse pas à ces attributs du fichier XML
Merci pour l'article,
Deux reactions: tout d'abord que penses tu dans le cas des facettes ou identifiants de sessions (?SID=) du fait que Google ignore quasiment le robots.txt au profit du réglage des paramètres d'urls dans la search console (et encore je crois qu'il continue de crawler)
Et en deux : ce que t'appelles la masse noire c'est grosso modo ce qui finit dans l'index secondaire ?
Je suis étonné de lire que Google ignore "quasiment" le robots.txt, ce n'est pas ce que je remarque.
Pour ma part, je n'utilise pas les réglages dans search console, je règle les problèmes sur le site lui-même, c'est bien mieux (et ça marche avec tous les moteurs, question de principe).
J'ai expliqué dans l'article ma définition de la masse noire. Personne ne peut réellement dire ce qu'on appelle l'index secondaire, donc je ne commenterai pas ce point.