Sommaire
- Définition de la notion de cache
- Fonctionnement d'un cache
- Les différents mécanismes de cache
- Benchmark
- Conclusion
- PS : les buffers
Introduction
Malgré l'évolution exponentielle de la puissance de nos ordinateurs, les informaticiens se sont de tout temps attachés à mettre en œuvre des méthodes qui accélèrent le traitement des données. Les webmasters n'échappent pas à la règle avec pour objectif de préserver les ressources de leur serveur d'une part mais aussi d'améliorer l'expérience des utilisateurs de leurs sites web (il n'est jamais agréable de patienter plusieurs minutes à attendre qu'une page HTML ait fini de se charger dans notre navigateur !).
Récemment, les référenceurs se sont émus d'une annonce de Google indiquant que la vitesse de chargement d'un site serait désormais un critère pris en compte dans le classement des résultats de recherche.
Parmi les nombreux mécanismes mis au point par les informaticiens pour améliorer les performances d'une application, je vous propose d'examiner les systèmes de mise en cache des données mis en œuvre dans une architecture serveur web PHP+MySQL depuis la réception de la requête par le serveur web jusqu'à la restitution de l'information par le navigateur dans l'optique d'améliorer les performances d'un serveur web.
Mais avant tout, essayons de définir ce qu'est un cache en informatique.
Définition : la notion de cache en informatique
La littérature sur le web propose de nombreuses définitions, plus ou moins restrictives, des caches informatiques. J'ai retenu celle de Wikipedia (en anglais) dont voici la traduction :
En informatique, un cache est un système permettant d'améliorer les performances en stockant les données de façon transparente afin qu'elles soient servies plus rapidement lors de requêtes ultérieures.
Cette définition fait la séparation entre les caches et les tampons (buffer en anglais) qui sont "des systèmes de stockage des données dans l'attente de leur traitement". Je parle des tampons en fin d'article.
Fonctionnement d'un cache
Le paramètre le plus important influant dans le choix d'un mécanisme de gestion de cache est la capacité de stockage en regard du volume de données à stocker. On distingue 2 cas :
- Le volume de données potentiellement cachables est inférieur à la capacité de stockage du cache ou, en d'autres termes, la capacité de stockage du cache peut être ajustée au volume de données potentiellement cachables. Dans ce cas de figure, les données sont supprimées du cache dès que la source est mise à jour.
- Le volume de données potentiellement cachables est supérieur (ou très supérieur) à la capacité de stockage du cache. Il existe principalement deux algorithmes de gestion de ce type de cache, l'un basé sur la fraîcheur des données, dit LRU (pour Last Recently Used), l'autre sur leur fréquence d'utilisation, dit LFU (pour Last Frequently Used).
Avec le premier algorithme, lorsque le cache ne peut pas stocker une donnée, il supprime les données les plus anciennes pour libérer de la place. Avec le second, ce sont les données les moins fréquemment utilisées qui sont supprimées.
Pour plus de détails sur ces algorithmes et leurs variantes, je vous invite à consulter l'article Algorithmes de remplacement des lignes de cache.
Application des caches dans la chaîne de production d'information d'un serveur web
Le schéma ci-dessous décrit, de façon simplifiée, le cheminement d'une requête HTTP.

Nous allons aborder maintenant les différents mécanismes de cache mis en œuvre par le serveur MySQL, le moteur PHP, le serveur web et les possibilités de cache supplémentaires par programmation.
Le cache de requêtes MySQL
MySQL propose différents dispositifs de cache dont l'étude sortirait du cadre de cet article. Je décris le fonctionnement du plus important à mes yeux (et aussi le plus impactant sur les performances) : le cache de requête.
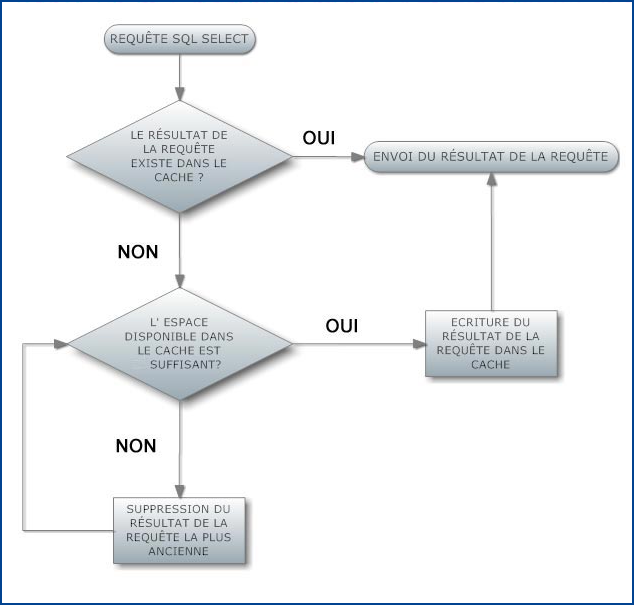
Ce cache fonctionne par allocation de bloc mémoire de taille variable selon un algorithme de type LRU pour les requêtes de type SELECT. Ce fonctionnement peut être très pénalisant dans certains cas (site implémentant son propre moteur de recherche par exemple). En effet, les requêtes effectuées par un moteur de recherche sur une base de données peuvent êtres qualifiées d'aléatoires contrairement aux requêtes utilisées pour générer le contenu d'une page web donnée. Une succession de recherches sur le site aura pour effet de remplir le cache avec des requêtes ayant peu de chance de se renouveler au détriment de requêtes plus anciennes mais plus fréquentes. De la même manière, l'algorithme ne tient pas compte de la complexité des requêtes et de leur consommation en termes de ressources. Heureusement, MySQL offre la possibilité de paramétrer le serveur en laissant au programmeur le choix des requêtes à cacher à l'aide des instructions SELECT SQL_CACHE et SELECT SQL_NO_CACHE.
D'autre part, le fonctionnement par allocation de blocs de taille variable impose l'utilisation d'un mécanisme de défragmentation afin de maintenir un taux de performance optimum, qui est obtenu par la commande FLUSH QUERY CACHE. Les commandes RESET QUERY CACHE et FLUSH TABLES ont pour effet de vider totalement le cache de requêtes.
Le cache de requêtes MySQL peut être activé/désactivé et paramétré (taille du cache, taille maximum des requêtes cachables, taille minimum des blocs d'allocation etc.) dans la configuration du serveur MySQL). Le paramétrage du cache de requête de MySQL ne saurait être universel : c'est une opération dédiée à chaque application, ce qui impose de procéder par essais et tests successifs afin de trouver le bon compromis entre l'utilisation des différentes ressources et les performances de l'ensemble.
Le cache d'OPCODE pour PHP
PHP (au même titre que ASP, Coldfusion ou JSP) est un langage interprété. Avant d'exécuter les instructions contenues dans un script, le moteur PHP doit effectuer plusieurs opérations. La première est la vérification syntaxique, qui est effectuée par le Lexer. S'il n'y a pas d'erreur de syntaxe, le script est transmis au Parser dont le rôle est de transformer les instructions contenues dans le script en pseudo code (OPCODE) exécutable par l'Executor, le Zend Engine que l'on peu qualifier de machine virtuelle.
Lorsque l'on examine ce processus, on voit aisément que pour un script donné qui n'est pas modifié entre deux exécutions, les deux premières opérations pourraient être évitées si on stockait l'OPCODE associé. C'est le rôle joué par les caches d'OPCODE (Zend Optimizer, eAccelerator, APC, ionCube, etc.).
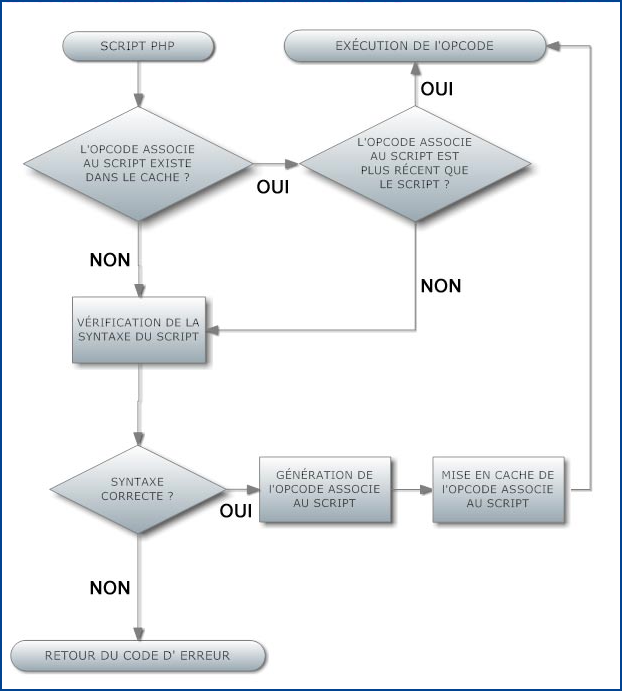
Le fonctionnement de ces caches est très simple. Il est basé sur la présence de l'OPCODE dans le cache et la comparaison de sa date de génération avec la date de dernière modification su script source. Lors de l'exécution d'un script, le système de gestion de cache vérifie si l'OPCODE correspondant existe dans le cache.
S'il n'existe pas, il est généré par le Parser, stocké dans le cache de manière horodatée en correspondance avec la date de dernière modification du fichier contenant le script puis exécuté par l'Executor de PHP.
Si un OPCODE correspondant au script existe dans le cache, le système vérifie que le fichier source n'a pas été modifié depuis la génération de l'OPCODE grâce à l'horodatage. Si c'est le cas, l'OPCODE présent dans le cache est exécuté, sinon il est régénéré, le cache est mis à jour puis l'OPCODE est exécuté.
Sur un serveur en production, on peut généralement accélérer ce processus en supprimant l'étape de comparaison des dates entre le fichier source (sur le disque) et l'OPCODE correspondant (en mémoire) et supprimer les accès disque de cette opération. Il appartient alors au webmaster de vider manuellement le cache mémoire lors de la modification des scripts source (les systèmes de cache d'OPCODE disposent généralement d'une API permettant de manipuler le cache depuis PHP, les possibilités de ces API sortant du cadre de cet article). Dans le pire des cas, le redémarrage de PHP réinitialise le cache.
Le principal paramètre à définir est généralement la taille de la mémoire cache. Dans la plupart des cas, le nombre de scripts étant limité, il est facile de dimensionner la taille du cache par approches successives afin qu'il puisse contenir l'ensemble des OPCODES. Dans les cas extrêmes mais rares (plusieurs centaines voire milliers de scripts), il existe des options de paramétrage pour limiter la taille ou le nombre des OPCODES mis en cache ainsi que la manière dont le système choisira les fichiers à cacher. Le paramétrage et les fonctionnalités variant d'un système de cache d'OPCODE à l'autre, voici donc les liens vers les documentations des plus couramment utilisés :
- Zend Optimizer
- eAccelerator
- Altenative PHP Cache (APC)
- ionCube
Cacher les données à l'aide de PHP
Il est également possible de cacher les données en mémoire ou sur le disque en utilisant des librairies PHP comme PEAR Cache Lite ou des applications comme memcached. Il est également possible d'implémenter son propre système de cache comme je l'explique dans mes deux précédents articles publiés sur webRankInfo (le 1er dans le forum et le 2nd ici dans les dossiers : script de cache PHP).
Et si on cachait les données au niveau du serveur HTTP ?
Je ne m'attarderai pas ici dans une présentation détaillée de la mise en cache au niveau du serveur HTTP ni dans l'utilisation d'un serveur proxy en guise de cache HTTP. Mon propos étant juste de vous donner une méthode simple (et radicale) pour court-circuiter PHP et MySQL en cachant les données au niveau du serveur web.
Au début de l'apparition des langages de scripts coté serveur, bon nombre de webmasters généraient manuellement une copie statique du site afin d'alléger la consommation des ressources serveur. Certains on même imaginé des méthodes permettant d'éviter d'avoir à faire cette opération manuellement et confiant la tâche au serveur HTTP lui-même. Je ne m'étendrais pas sur les avantages et inconvénients de cette technique, me contentant de vous la livrer car elle peut présenter un intérêt dans certains cas spécifiques.
Cette technique consiste à tirer parti des possibilités de réécritures d'URL et de redirection conditionnelle dans le paramétrage d'un serveur HTTP.
Considérons le cas du serveur Apache avec ces deux règles inscrites dans un fichier .htaccess :
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^(.*).html$ /script.php?uri=$1
La première ligne teste si la ressource demandée au serveur HTTP existe en tant que fichier. Si ce n'est pas le cas, la deuxième ligne indique au serveur HTTP que si la ressource demandée est un fichier ayant pour extension .html (typiquement une page html), le serveur doit exécuter le script script.php, avec en paramètre l'URI demandée. En clair, toute requête à une page HTML exécutera le script script.php. Il suffit alors que notre script.php enregistre la page HTML générée dans le fichier dont le chemin est défini par URI, pour que celui-ci soit renvoyé directement par le serveur HTTP (sans passer par PHP) lorsqu'il sera à nouveau demandé. Ce système simple est très performant pour des sites de petite taille ne présentant pas des mises à jour fréquentes, la gestion du contenu du cache pouvant aisément être faite manuellement lors d'une mise à jour.
Benchmark
Pour finir, un petit tableau comparatif du temps de génération d'une page PHP faisant des requêtes à une base de données MySQL en fonction des systèmes de cache activés (cache de requête Mysql, Cache d'OPCODE eAccelerator et cache de pages maison utilisant le script V2).
Les tests ont étés effectués sur la page d'accueil d'un site en production en faisant la moyenne de 100 requêtes effectuées à différents moments sur une période de 24h. Ils ne sont communiqués qu'à titre d'illustration de l'article (serveur fonctionnant sous Nginx avec PHP en serveur FCGI et MySQL distant).
| Temps de génération de la page par PHP en secondes | Mysql | eAccelerator | Cache PHP V2 |
| 0.0031 | x | x | x |
| 0,0032 | x | x | |
| 0,0099 | x | x | |
| 0,0104 | x | ||
| 1,3779 | x | x | |
| 1,8876 | x | ||
| 4,0898 | x | ||
| 4,6397 |
Remarques : Ces mesures font apparaître que l'ordre d'importance des caches en termes de performances est (dans ce cas précis) :
- Cache PHP V2
- Cache de requêtes MySQL
- Cache d'OPCODE eAccelerator
On remarque que l'influence du cache d'OPCODE, ne dépendant que du script PHP et pas des données à traiter, est à peu près constante et autour de 0.5 à 0.7 secondes de gain. Il est normal que l'influence du cache de requête MySQL soit nulle lorsque le Cache PHP V2 est activé puisque ce dernier ne fait aucune requête à la base de données.
Conclusion
Les développeurs de nos applications web favorites ont prévu des mécanismes puissants permettant d'améliorer les performances de ces applications. Malheureusement, mon expérience montre que ces mécanismes sont peu ou mal utilisés par les webmasters par méconnaissance, manque de compétence ou manque d'intérêt pour la chose. Il aura fallu l'annonce de Google indiquant que la vitesse de chargement d'un site influerait dorénavant sur son référencement pour mettre cette communauté en émoi et lui faire prendre conscience de l'importance de ces mécanismes (bien qu'il existe d'autres axes, nombreux, permettant d'améliorer la vitesse de chargement des sites web). Si demain le web devient plus rapide, même si ce n'était que dans le but de satisfaire à des exigences de référencement, cela me convient car ça contribue également à l'amélioration de l'expérience utilisateur du web.
Je souhaite que cet article aide le lecteur à mieux comprendre et mieux utiliser les mécanismes de cache lors du développement d'applications web. N'hésitez surtout pas à donner votre avis et à poser vos questions en commentaires de cet article ou dans la discussion engagée sur le forum : aperçu des mécanismes de gestion du cache PHP, MySQL, HTTP.
Post-Scriptum : les buffers (tampons de données)
Pendant que je m'attelais à la (lourde) tache de rédiger cet article, un ami informaticien qui lisait par dessus mon épaule, me faisait remarquer que mon article était incomplet car je n'abordais pas la présentation des tampons de données (bien que je les évoque au début de l'article pour mieux les évacuer ensuite). Après réflexion, j'ai pris acte de sa remarque et décidé d'ajouter un paragraphe sur les tampons de données (buffers pour les anglo-saxons) dans le sens ou, intervenants dans la chaîne de traitement d'une requête web, ils apportent un éclairage à certains dysfonctionnements de cette chaîne.
Pour faire bref, un tampon de données est généralement une zone mémoire gérée par un algorithme FIFO (First In First Out), en clair une file d'attente où le premier arrivé est le premier servi. Cette zone mémoire est destinée à amortir la différence de vitesse de transfert des données entre un producteur et un consommateur, afin d'éviter une perte d'information.
Voyons un exemple concret avec un serveur HTTP.
Lorsqu'un serveur HTTP reçoit une requête, il effectue un traitement puis retourne les données résultantes. Pendant qu'il effectue le traitement, il ne peut pas répondre à une autre requête (dans la pratique le serveur HTTP peut traiter plusieurs requêtes simultanément mais ce nombre est limité ce qui revient au même pour la compréhension du mécanisme). Pour éviter la perte des informations, les requêtes en attente de traitement sont stockées dans une file d'attente pour être satisfaites ultérieurement. Notre serveur HTTP est donc capable de différer le service d'une requête. PHP également lorsqu'il fonctionne comme un serveur indépendant du serveur HTTP (CGI ou FCGI par exemple). Par contre, MySQL n'en est pas capable, et lorsque le nombre de requêtes simultanées atteint le seuil indiqué dans sa configuration, il nous gratifie alors du fameux message « Too many connections » !
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Article utile, mais les tampons de sortie ne sont pas du tout ceux expliqués ici!
http://php.net/manual/fr/function.ob-start.php
C'est un concept très utile pour faire du cache fait maison :)
Il manquerait dans cet article le cache au niveau du reseaux (CDN)
Optimisé pour les données statics (généralement les images, vidéos, etc...), le cache CDN se comporte comme un proxy. Un requête arrive sur un des serveurs de cache, qui retourne la données s'il la possède, sinon appel le serveur d'application pour récupérer la données originale et la stock avant de la retourner a l'utilisateur. Le CDN allège donc le serveur au niveau de la bande passante et des IO..
L'objectif finale du CDN, est de fournir des serveurs proches de l'émetteur de la requête pour optimiser le temps de réponse ce qui implique une couverture du territoires (des territoires pour des site internationaux) et donc un coup relativement élevé mais un gain réel pour les temps de réponse des données statiques.
Il manque le cache le plus utile et celui qui coute le moins cher : Le cache navigateur ;)