Nouveau WRInaute
Bonjour,
Ma question concerne l'indexation de pages "parasites" sur mon site.
Lorsque je lance la commande site:http://www.maxirobots.com/
et que je remonte jusqu'à la quinzième page, j'obtiens les pages ignorées pour cause de duplication de contenu.
En cliquant sur "relancer la recherche pour inclure les résultats ignorés" j'ai un aperçu des pages considérées comme dupliquées.
Le nombre de ces pages est d'environ 80. Quasiment toutes ces pages sont des pages panier..
Exemple :
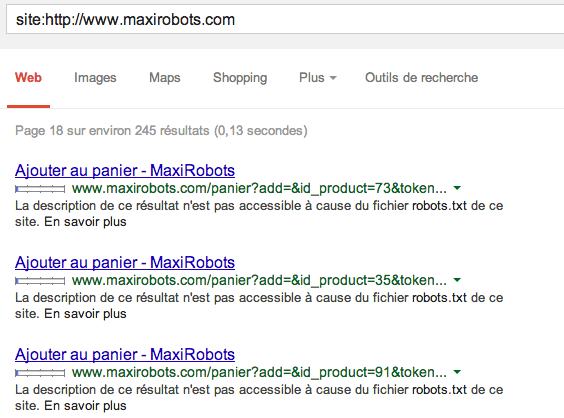
J'ai donc ajouté l'attribut NoFollow à mes liens ajout au panier.
<a class="button ajax_add_to_cart_button exclusive" rel="ajax_id_product_89 nofollow" href="http://www.maxirobots.com/panier?add=&id_product=89&token=7233c92c933269bab616ec02fac10874" title="Ajouter au panier">Ajouter au panier</a>
Mes questions :
Ces pages risquent-elles d'être pénalisantes pour mon site ?
Si oui, comment les sortir de l'index ?
J'ai également modifié mon fichier robots.txt mais ne faut-il pas rajouter un noindex directement dans le code ?
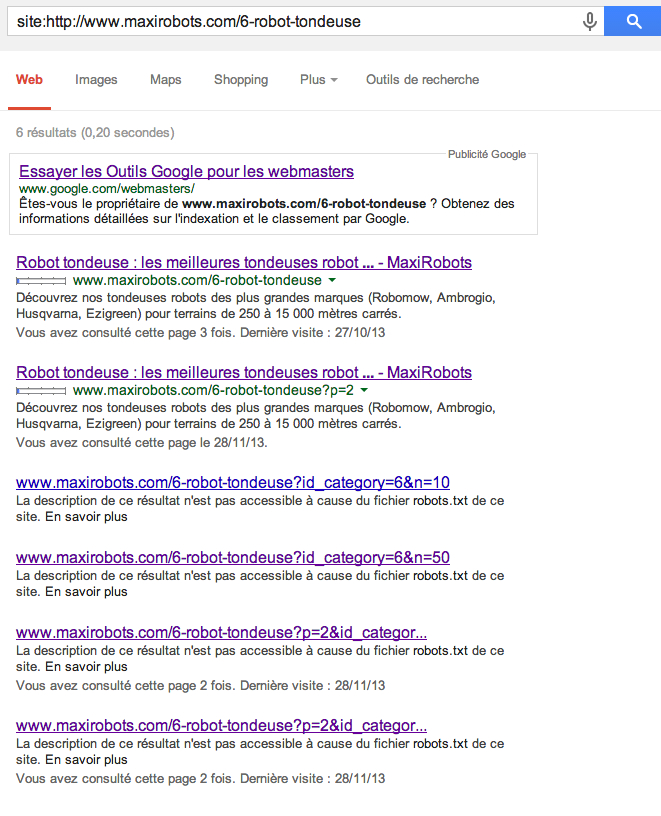
J'ai également ce genre de résultats qui sont probablement gênants ?
J'espère que ma problématique n'est pas trop "brouillon" et remercie par avance ceux qui répondront. Si vous avez également des remarques plus générales sur notre site d'un point de vue général, SEO, je prends avec plaisir")
Thibaud
Ma question concerne l'indexation de pages "parasites" sur mon site.
Lorsque je lance la commande site:http://www.maxirobots.com/
et que je remonte jusqu'à la quinzième page, j'obtiens les pages ignorées pour cause de duplication de contenu.
En cliquant sur "relancer la recherche pour inclure les résultats ignorés" j'ai un aperçu des pages considérées comme dupliquées.
Le nombre de ces pages est d'environ 80. Quasiment toutes ces pages sont des pages panier..
Exemple :
J'ai donc ajouté l'attribut NoFollow à mes liens ajout au panier.
<a class="button ajax_add_to_cart_button exclusive" rel="ajax_id_product_89 nofollow" href="http://www.maxirobots.com/panier?add=&id_product=89&token=7233c92c933269bab616ec02fac10874" title="Ajouter au panier">Ajouter au panier</a>
Mes questions :
Ces pages risquent-elles d'être pénalisantes pour mon site ?
Si oui, comment les sortir de l'index ?
J'ai également modifié mon fichier robots.txt mais ne faut-il pas rajouter un noindex directement dans le code ?
Code:
# robots.txt automaticaly generated by PrestaShop e-commerce open-source solution
# http://www.prestashop.com - http://www.prestashop.com/forums
# This file is to prevent the crawling and indexing of certain parts
# of your site by web crawlers and spiders run by sites like Yahoo!
# and Google. By telling these "robots" where not to go on your site,
# you save bandwidth and server resources.
# For more information about the robots.txt standard, see:
# http://www.robotstxt.org/wc/robots.html
User-agent: *
# Private pages
Disallow: /*orderby=
Disallow: /*orderway=
Disallow: /*tag=
Disallow: /*id_currency=
Disallow: /*search_query=
Disallow: /*back=
Disallow: /*n=
Disallow: /*controller=addresses
Disallow: /*controller=address
Disallow: /*controller=authentication
Disallow: /*controller=cart
Disallow: /*controller=discount
Disallow: /*controller=footer
Disallow: /*controller=get-file
Disallow: /*controller=header
Disallow: /*controller=history
Disallow: /*controller=identity
Disallow: /*controller=images.inc
Disallow: /*controller=init
Disallow: /*controller=my-account
Disallow: /*controller=order
Disallow: /*controller=order-opc
Disallow: /*controller=order-slip
Disallow: /*controller=order-detail
Disallow: /*controller=order-follow
Disallow: /*controller=order-return
Disallow: /*controller=order-confirmation
Disallow: /*controller=pagination
Disallow: /*controller=password
Disallow: /*controller=pdf-invoice
Disallow: /*controller=pdf-order-return
Disallow: /*controller=pdf-order-slip
Disallow: /*controller=product-sort
Disallow: /*controller=search
Disallow: /*controller=statistics
Disallow: /*controller=attachment
Disallow: /*controller=guest-tracking
[b]Disallow: /*panier?
Disallow: /commande*
Disallow: /panier*[/b]
# Directories
Disallow: /*classes/
Disallow: /*config/
Disallow: /*download/
Disallow: /*mails/
Disallow: /*modules/
Disallow: /*translations/
Disallow: /*tools/
# Files
Disallow: /*fr/mot-de-passe-oublie
Disallow: /*fr/adresse
Disallow: /*fr/adresses
Disallow: /*fr/authentification
Disallow: /*fr/panier
Disallow: /*fr/bons-de-reduction
Disallow: /*fr/historique-des-commandes
Disallow: /*fr/identite
Disallow: /*fr/mon-compte
Disallow: /*fr/details-de-la-commande
Disallow: /*fr/avoirs
Disallow: /*fr/recherche
Disallow: /*fr/commande-rapide
Disallow: /*fr/suivi-commande-invite
Disallow: /*fr/confirmation-commandeJ'ai également ce genre de résultats qui sont probablement gênants ?
J'espère que ma problématique n'est pas trop "brouillon" et remercie par avance ceux qui répondront. Si vous avez également des remarques plus générales sur notre site d'un point de vue général, SEO, je prends avec plaisir
Thibaud
