bonsoir a tous
j essaye de comprendre pourquoi google a juste indexer mon fichier principal de mon site donc le index.php
par contre rien ne se passe pour les autres pages
je suis donc occupé a essayer de comprendre
je me suis rendu sur la search console de google
et j ai demande une inspection d une url d une page
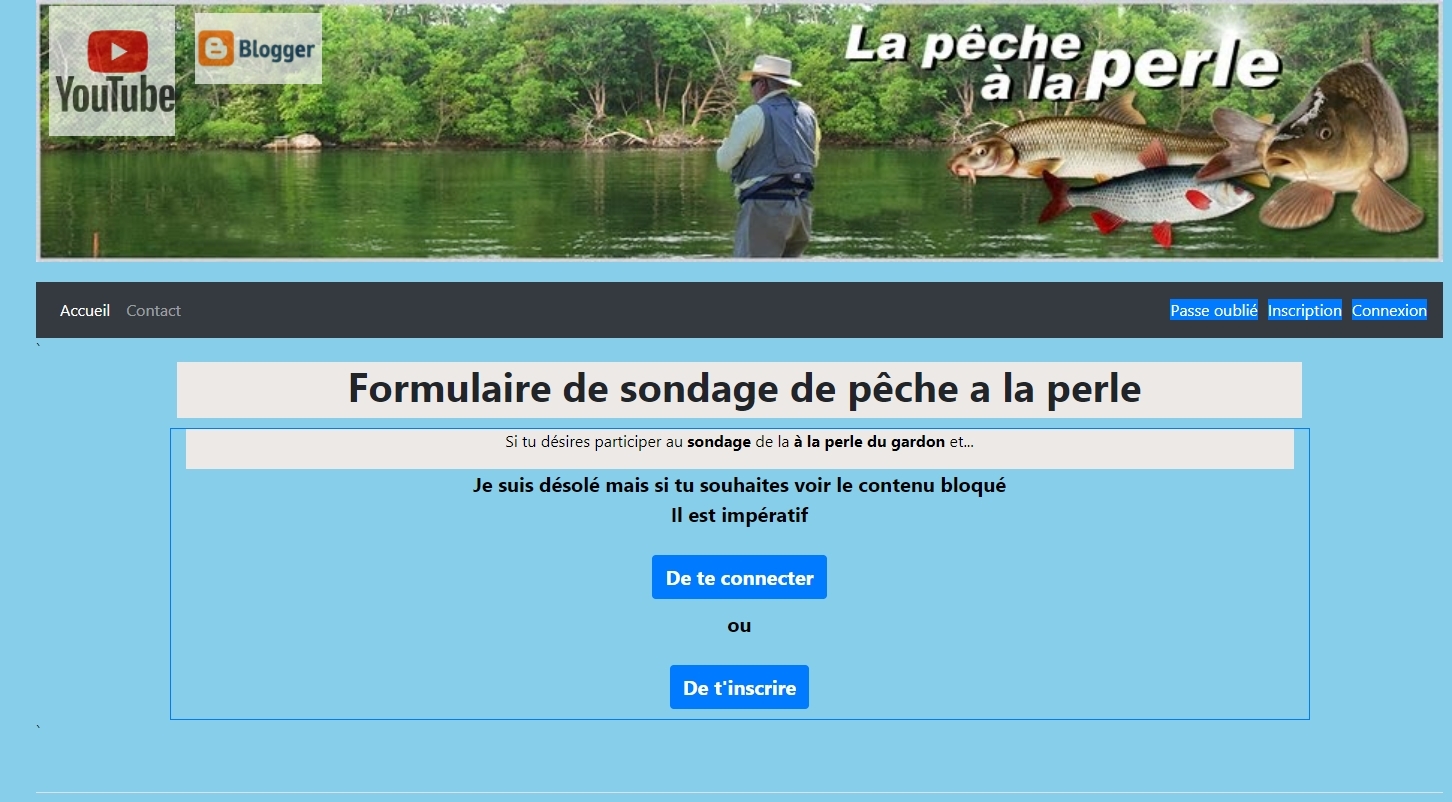
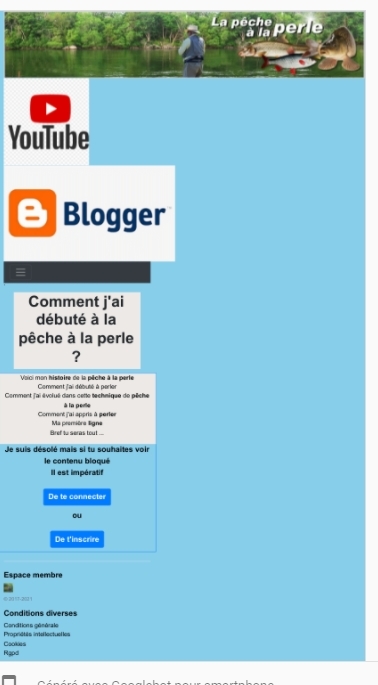
google la trouve mais lorsque je demande une capture d écran et que je consulte mon fichier fournit par google
google n a pas pris en compte mes fichiers include ...
Lorsque je teste la page tout fonctionne a merveille
j essaye de comprendre pourquoi google a juste indexer mon fichier principal de mon site donc le index.php
par contre rien ne se passe pour les autres pages
je suis donc occupé a essayer de comprendre
je me suis rendu sur la search console de google
et j ai demande une inspection d une url d une page
google la trouve mais lorsque je demande une capture d écran et que je consulte mon fichier fournit par google
google n a pas pris en compte mes fichiers include ...
Lorsque je teste la page tout fonctionne a merveille