
Qu'est-ce qu'un lien nofollow ?
Introduit par Google en 2005 et rapidement supporté également par Yahoo! et MSN (les grands concurrents unis pour la même cause, on n'avait jamais vu ça), cet attribut permet à l'éditeur d'un site d'indiquer qu'il ne garantit pas la pertinence du lien.
En général, on met du nofollow sur un lien créé dynamiquement par un visiteur (commentaire de blog, message de forum, signature de livre d'or, etc.). On appelle ça un lien "UGC".
Les moteurs qui le gèrent indiquent qu'ils ne tiendront pas compte de ce lien dans leur algorithme (nous verrons plus loin comment de manière plus précise...).
Un lien standard est sous la forme suivante :
<a href="https://www.webrankinfo.com/">WebRankInfo</a>
Un lien nofollow non pris en compte par l'algo :
<a href="https://www.webrankinfo.com/" rel="nofollow">WebRankInfo</a>
Lisez mon article sur les liens internes nofollow pour comprendre pourquoi je déconseille ça.
Encore plus important, suivez mes conseils d'optimisation du maillage interne, c'est un axe extrêmement efficace pour renforcer le SEO.
Ce qui a changé en 2019
En septembre 2019, Google a décidé d'ajouter 2 autres valeurs possibles pour l'attribut rel d'un lien, en complément du nofollow :
- un lien rel=sponsored pour les liens sponsorisés (paid links)
- un lien rel=ugc pour les liens créés par les utilisateurs
Ce qui a changé en 2020
Depuis le 1er mars 2020, nofollow n'est plus d'un "indice" (hint). Cela signifie que Google peut décider de suivre un lien nofollow, qu'il soit interne ou externe.
Pour les liens internes, l'impact pourrait être important puisqu'il faut envisager que Google crawle et même indexe des pages qu'on n'avait pas envisagées. Cela contribue à créer de la masse noire et d'autres problèmes de dégradation de la qualité du site. C'est peu probable, mais ça peut arriver et surtout c'est possible de le vérifier en amont... Donc autant le faire !
Dossier complet : nofollow as a hint : impact sur le crawl et l'indexation
Pour les liens externes, Google pourrait tenir compte de certains liens nofollow. On pense par exemple à ceux situés sur Wikipédia. A la différence des liens internes, ça sera très difficile de vérifier si le lien a un impact sur le ranking.
Objectifs de l'initiative du rel nofollow
L'objectif des moteurs de recherche est de permettre aux responsables de sites de ne plus être victimes du spam de liens. Il faut dire que c'est très pénible de devoir supprimer un par un des commentaires sans intérêt dans un blog (des suites de liens sans aucun rapport avec l'article), des signatures dans des livres d'or disant juste "Bravo" avant quelques liens, ou des messages dans des forums.
Revenons sur les aspects techniques de la solution proposée. En relisant les déclarations des trois principaux moteurs, je constate que rien n'est très clair dans leurs "spécifications" :
- Google indique qu'il ne tiendra pas compte de ces liens ("those links won't get any credit when we rank websites in our search results").
- Yahoo! reste très flou et ne précise pas comment ils réagiront exactement à ces liens ("By adding a rel="nofollow" attribute to hyperlinks, webmasters and weblog owners can tell search engines that the links are effectively untrusted")
- MSN indique que son crawler ne suivra pas ces liens et n'en tiendra pas compte dans l'algorithme ("Any link with this tag will indicate to a crawler it is not necessarily approved by this page and shouldn’t be followed nor contribute weight for ranking").
Cela dit, on peut se demander si cette initiative des moteurs est vraiment la bonne solution. A première vue c'est une bonne idée, l'objectif avoué de la lutte contre le spam plait forcément à la plupart des internautes. Mais ne serait-ce pas aussi une forme d'aveu des moteurs qui n'ont pas trouvé de solution et qui reportent le problème sur les webmasters ? Leur algorithme est mis à mal à cause de ces spammeurs, ne serait-ce pas aux moteurs de trouver comment l'améliorer ?
Le nofollow peut-il être une solution efficace ?
Je ne suis pas sûr que ce système tue réellement le spam... peut-être même qu'il pourrait plutôt tuer le lien tel qu'il existe depuis toujours sur le web... Voici quelques réflexions à ce sujet.

A moins de l'indiquer clairement par un panneau, les spammeurs ne sauront pas que le lien qu'ils ajoutent ne leur servira à rien du point du vue du référencement : pourquoi donc s'arrêteraient-ils ? Idem bien entendu pour les programmes automatisés qui remplissent des livres d'or ou des blogs. Tous ces liens resteront visibles pour les internautes et seront toujours une plaie pour les responsables de sites.
Les liens fournis dans des commentaires de blogs ou dans des messages de forum restent encore dans la majorité des cas intéressants pour le lecteur. Ne pas en tenir compte c'est supprimer une partie du contenu en le jugeant inintéressant a priori :dommage !
Comme on le disait dans la discussion l'attribut rel="nofollow" pour combattre le spam ? du forum WRI :"Il y aurait donc bientôt 2 types de liens. Ceux pour les visiteurs et ceux pour Googlebot. De quoi créer une vraie fracture entre la réalité du web et l'index de Google."...
Les échanges de liens vont devenir difficiles à gérer sereinement... Il faudra vérifier sur la page qui pourrait nous faire un lien :
- qu'elle n'est pas orpheline
- qu'elle n'est pas interdite dans le fichier robots.txt
- qu'elle n'est pas interdite par une balise meta robots
- que le lien n'est pas interdit aux moteurs par l'attribut rel=nofollow
- que le lien n'est pas fait en JavaScript bloqué ou par une mauvaise redirection
- etc.
Pour en savoir plus et partager votre expérience, je vous invite à rejoindre les discussions sur le forum WebRankInfo :
- Google, Yahoo et MSN unis contre le spam ? (discussion à propos de cet article précis)
- l'attribut rel="nofollow" pour combattre le spam
Fonctionnement du nofollow en 2007
Loren Baker a publié sur Search Engine Journal les résultats d'une petite enquête auprès des moteurs de recherche à propos de l'attribut rel="nofollow", intitulée How Google, Yahoo & Ask.com Treat the No Follow Link Attribute.
C'est d'autant plus intéressant d'avoir le point de vue des moteurs eux-mêmes que la prise en compte du rel=nofollow n'a jamais été claire. Pour ma part, j'ai toujours trouvé que le terme no follow
avait été très mal choisi car apparemment les moteurs ne s'interdisaient pas forcément de suivre le lien, ils avaient plutôt dit qu'ils n'en tenaient pas compte dans leur algorithme de classement des pages... Mais ceci a apparemment évolué chez Google !
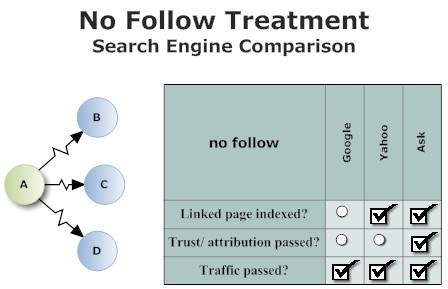
En résumé, voici ce qu'il faut retenir :
- pour Google : un lien nofollow n'est plus suivi (ils le faisaient même avec le rel nofollow) donc évidemment la page liée n'est pas crawlée et indexée, et le lien n'aide pas la page liée à être mieux positionnée. Les liens nofollow peuvent apparaître dans les résultats de la commande link: ou dans Webmaster Central.
- pour Yahoo : un lien nofollow est suivi et la page liée est crawlée et indexée, par contre le lien n'aide pas la page liée à être mieux positionnée. Les liens nofollow sont malgré tout listés dans Yahoo Site Explorer.
- pour MSN : cette étude n'en parle pas puisque MSN n'a pas répondu aux questions de Loren Baker. Certains pensent que MSN gère le nofollow comme Yahoo.
- pour Ask : le moteur n'a jamais officiellement supporté l'attribut rel="nofollow", donc pas de conclusion
Attention à bien comprendre ce qui est indiqué ici : quand je dis que Google n'indexe pas la page liée par un lien nofollow, il faut comprendre ce lien ne peut pas permettre à la page liée d'être indexée grâce à ce lien, mais évidemment elle peut être indexée si elle reçoit un autre lien (sans nofollow)
.
On en parle aussi sur :
- Search Engine Land : How Search Engines Handle The Nofollow Attribute
- le blog de Sébastian : How Google & Yahoo handle the link condom
D'autres études avaient déjà été menées, je résume ce que leurs auteurs ont indiqué :
- The NoFollow Experiment :
- Yahoo suit le lien et indexe la page, mais la page sort très mal dans les résultats.
- Ask suit le lien, indexe la page et celle-ci sort bien dans les résultats
- Google n'indexe pas la page
- MSN n'indexe pas la page
- rel="nofollow" Google, Yahoo and MSN : Google et Yahoo suivent le lien avec leur crawler mais seul Yahoo indexe la page.
Bien entendu si certains parmi vous ont effectué le même genre de test sur cet attribut nofollow, qu'ils n'hésitent pas à nous en faire part !

Suivi ou pas par le moteur, un lien est un lien, des clics potentiels, donc elle ne sert à rien cette règle. Le SPAM à encore un bel avenir devant lui.
Certains spammeurs renoncent à spammer quand ils voient que le "spot" est en nofollow (c'est un des buts initiaux du nofollow).