Comment définir le sens d'un lexème ?
Nous avons vu que pour traiter de manière automatisée les mots, il fallait les découper en lexème et morphème.
Bref rappel du lexème et du morphème
Considérons l'exemple ci-dessous :
"chantons", "chantant", "chanteur"
Ces 3 mots partagent le lexème "chant", ils sont différenciés par les morphèmes :
- -"ons" : marque la 1ère personne du pluriel de la conjugaison (nous) ;
- -"ant" : marque le participe présent ;
- -"eur" : marque la personne qui réalise l'action de chanter (suffixe -eur/-euse : chanteur/chanteuse).
Les 3 mots de notre exemple ont en commun le sens contenu dans le lexème "chant". On part donc de cet élément avant de spécifier le sens de chacun en identifiant des formes verbales (pour désigner l'action de chanter) ou des suffixes (pour désigner la personne qui réalise l'action).
Le sens étant essentiellement contenu dans le lexème, le problème est donc de disposer d'un outil sémantique permettant de le traiter. Le morphème de son côté apporte "seulement" des précisions de sens par rapport au lexème !
Pour traiter le sens des lexèmes, la sémantique réalise des analyses sémiques.
Principe de l'analyse sémique appliqué au canard
De même que l'on "découpe" les mots avec la morphologie, on peut "découper" leur sens avec la sémantique. Il existe en effet des unités (minimales) de sens , appelées les sèmes, qui permettent d'identifier le sens des mots ou lexèmes.
A titre d'exemple, voici l'analyse sémique du "canard" d'après une méthode ancienne mais qui permet d'en comprendre le principe.
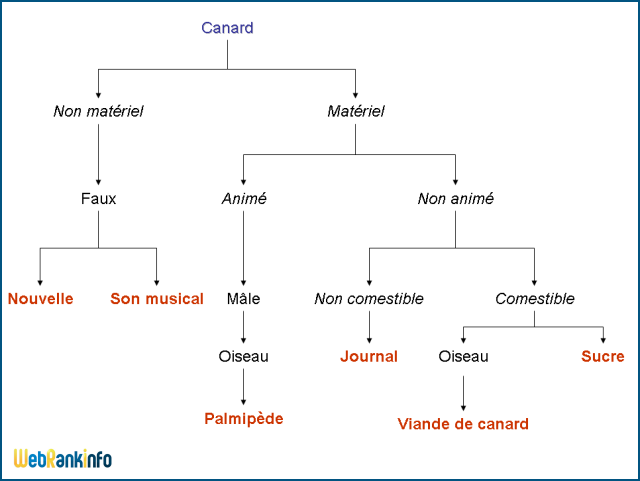
Analyse sémique de canard (schéma de Katz et Fodor)
On voit ici qu'il s'agit d'établir des classifications sous forme d'arborescence rendant compte des différents sens (polysémie) du lexème canard qui peut selon les contextes être un son discordant, une fausse information, un volatile, un journal, un sucre ou un bon magret ;-)
Un "canardeau" (le petit du canard) bien que partageant le même lexème n' aura pas l'ensemble des traits sémantiques (appelé le sémème) du lexème "canard". Il en partage cependant une partie, il a des sèmes communs ! Ainsi si ces deux mots sont employés ensemble, leur présence indique la pertinence de certains sèmes et l'exclusion probable d'autres !
Imaginez que l'on réalise l'étude sémique d'un autre lexème, par exemple "oie", nous trouverions des sèmes communs avec "canard". Faisons de même avec "volaille", nous trouverions des sèmes communs avec "oie", "canard" et d'autres très différents. Le principe de l'analyse sémique a ainsi un double intérêt, il permet de rendre compte :
- des sèmes qui caractérisent un lexème (donc les éléments de sens qui concernent plusieurs mots d'une même famille),
- des sèmes communs pour différents lexèmes (donc les éléments de sens identiques pour des mots de formes différentes).
On peut ainsi reconnaître et traiter les familles de mots, la polysémie (en partie, ne rêvons pas trop !) et commencer à construire des relations sémantiques entre les mots.
Si nous reprenons l'exemple du lexème "chant" du début, il est aisé d'établir une relation de sens avec des termes comme "musique", "instrument" ou "note" mais aussi "oiseau" et bien sûr "canard" ;-)
Les analyses proposées par la sémantique ouvrent donc de larges perspectives !
Google est-il intelligent ?
La question est provocatrice. La sémantique propose aujourd'hui des analyses arborescentes plus pertinentes que l'exemple ci-dessus, analyses qui permettent la constitution de thésaurus (dictionnaire des relations entre les termes) et d'ontologies (modélisation des relations sémantiques d'un domaine de connaissance). Travailler à la constitution de ces outils n'est pas nouveau, c'est le propre de la linguistique informatique depuis des années.
En ce qui concerne le référencement, les moteurs de recherche effectuent ce type d'opérations mais de manière encore très limitée. Ces questions sont, vous l'avez compris, au cœur des problèmes d'indexation et de traitement des données, et au cœur du balbutiant Web sémantique. Évidemment, les moteurs ne nous laisseront pas comprendre quel modèle précis ils utilisent et comment ils ont intégré tout cela dans leur précieux algorithme mais chez Google et les autres on travaille d'arrache-pied !
Sur les questions sémantiques, les moteurs puisent déjà largement dans la linguistique informatique et s'inspirent pour la suite des techniques d'intelligence artificielle ! Certes, Google n'est pas (encore ???) une intelligence artificielle mais des chercheurs du domaine ont depuis déjà quelques temps de beaux bureaux à Mountain View...
La linguistique et la sémantique sont des outils précieux pour les moteurs de recherche et pour tout domaine traitant le langage naturel. Évidemment ce ne sont pas les seuls (heureusement !) mais j'espère vous avoir donné un aperçu de leur caractère indispensable.
A bientôt dans le forum WebRankInfo Rédaction web et référencement où l'on discute de cet article : Comment Google traite-t-il le sens des lexèmes ?
Véronique Martin
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

L'analyse sémique appliquée à la recherche est fascinante, mais la pratique a montré que Google s'appuie aujourd'hui bien plus sur des plongements vectoriels (embeddings) que sur des arbres de sèmes rigides. BERT puis MUM ont changé la donne : le sens émerge de la distribution des co-occurrences plutôt que d'une taxonomie préétablie. C'est un détail de valeur, mais il reconfigure toute l'approche SEO — nos clients constatent ces détenir, et les intégrer dans une stratégie de contenu change la performance.
Bonjour,
Bravo pour votre article. Je pense et cela n'engage que moi, qu'actuellement Google a encore besoin de notre aide en l'abreuvant de nos liens pertinents posés sur des expressions et mots clés contenus dans nos pages, le dirigeant sur des sites comme Wikipédia ou d'autres communautés axées sur secteur identique. De plus, si la page est optimisée, j'entends par là un bon title comme"Comment bien cuisiner le magret de canard chez webrankinfo :)" et bien le tour est joué, Google connait quelle est la thématique de la page. J'adhère entièrement le fait que le traitement sémantique est important, mais je crois que pour l'instant il offre plutôt les chances d'avoir une longue traîne et ainsi faire sortir la page sous plusieurs expressions. Une fois ces facteurs en places, il ne devrait plus y avoir : Je vous cite "des problèmes d'indexation et de traitement des données", mais fort heureusement comme vous l'expliqué "les moteurs de recherche effectuent ce type d'opérations, mais de manière encore très limitée".
François
J'ai bien compris vos remarques. Et je ne demande pas d'explications supplémentaires dans ce domaine.
Ce qui m'intéresse, d'une part, c'est de savoir où vous voulez en venir et à quelles conclusions concernant le traitement "intelligent " de Google. Comment selon vous Google intègre-t-il ces notions théoriques de sémantiques ?
D'autre part, je me demande s'il est pertinent d'essayer d'appliquer des théories linguistiques qui ne font pas appel à la langue parlées car je doute que Google s'intéresse à des notions "théoriquement dépassées" et uniquement adaptables à des modèles théoriques.
Google analyse-t-il d'une façon ou d'une autre la polysémie des lexèmes de sa bdd ?
Merci.
ref123
Bonjour,
Merci pour cet article.
Je voudrais ajouter un détail de valeur : l'analyse sémique tirée de Katz & Fodor est un modèle adapté sur une théorie linguistique et sémantique établissant les langues comme des simili-nomenclatures. Or le langage parlé n'en est est pas une. De plus, ce modèle date des années 70 si ma mémoire est bonne...
Qu'en est-il des théories modernes de sémantique ? Des études ont-elles été menées même à titre expérimental ?
Les moteurs de recherche tel Google prennent-ils en compte le caractère vivant des langues et des locuteurs ?
Merci de vos réponses.
ref123
Je ne m'intéresse pas ici à la problématique du langage parlé ! Le Web reste de l'écrit même s'il s'agit d'un nouveau mode d'écrit... Le modèle de Katz et Fodor est en fait plus ancien que vous ne le supposez, il date des années 60. J'ai choisi de donner celui-ci en exemple car c'est le plus accessible même s'il est théoriquement dépassé. Les décompositions sémiques de ce type viennent tout droit du structuralisme. Elles ont été reprises en 70 par des chercheurs en intelligence artificielle qui ont axé leur problématique sur la représentation des connaissances. Depuis la sémantique a élaboré d'autres formes d'analyses mais la modélisation informatique en revient toujours à un structure arborescente de plus en plus hiérarchisée, c'est ce que je voulais illustrer.
Existe-t-il des travaux sur la question ? Bien sûr, ils sont même appliqués puisqu'ils concernent l'élaboration de thésaurus et d'ontologie. Le propre de cet article, comme je l'explique en préambule n'est pas de présenter les théories ni les travaux les plus pointus mais de donner une culture linguistique pour le référencement. Je m'en tiens donc à des exemples simples pour initier à un mode de fonctionnement, si vous voulez plus d'informations théoriques et pratiques, il faut suivre des formations en linguistique informatique :-)