

Cet article est très long, j'ai passé un grand nombre d'heures à étudier les documents puis à rédiger ces conseils. Prenez le temps pour tout lire ! Posez vos questions dans le forum WebRankInfo. Si vous préférez du consulting, allez sur mon site WebRankExpert.
J'ai organisé ce dossier en grandes parties, avec pour chacune des actions concrètes que vous pouvez appliquer sur vos sites ou ceux de vos clients. Ceci sert aussi de sommaire :
ℹ️ Si vous ne voyez pas de quels documents je parle, consultez la discussion Fuite de documents Google (2024). Vous trouverez des explications ainsi que des liens vers toutes les ressources nécessaires.
⚠️ Je commence par une remarque importante :
- même si j'ai passé pas mal d'heures à décortiquer les documents
- même si j'ai lu plusieurs autres analyses de SEO reconnus
- même si j'ai l'habitude avec + de 20 ans d'expérience
- même si je sais qu'il faut éviter le piège du biais de confirmation
- ...
Vous devriez prendre tout ça avec du recul. Non seulement les documents eux-mêmes, mais également l'éclairage que je vous propose (ou l'interprétation que vous en ferez...). Peut-être que pour certains points, j'ai mal analysé ou interprété les choses, malgré ma vigilance.
Ce qui n'a pas changé depuis que je fais du SEO (fin des années 1990...), c'est qu'il faut tester. Testez ce qu'on vous conseille de faire ! Testez vos propres idées ! Vous apprendrez ce qui marche ou pas, dans quels cas.
Tous mes tests et "optimisations", je les mesure avec mon outil de test SEO RM Console. En "3 clics", j'obtiens des données fiables et précises sur l'impact SEO de mes actions. J'espère que vous faites pareil... Sinon faites un tour
Allez, c'est parti !
Analyse globale d'un site ou d'une page
De façon officielle, Google n'a pas souvent abordé les critères qui concernent l'ensemble d'un site (sauf pour HCU, exception notable). Il y a pourtant pas mal de choses à dire à ce niveau.
Un peu de termes techniques d'abord... Google utilise intensément les page embeddings et les site embeddings.
Les pages embeddings représentent des pages individuelles sous forme de vecteurs denses dans un espace à haute dimension (définition de Jeff Coyle sur MarketMuse, Leveraging Google’s Content Warehouse API for Structured Annotation, Semantic Analysis and Feature Tagging). Voyez ça comme un résumé très condensé de la signification sémantique et la pertinence du contenu d'une page. Google s'en sert notamment pour calculer la similarité entre pages et créer des clusters.
Les embeddings de sites étendent le concept des embeddings de pages à des sites entiers. Ils sont générés par l'agrégation des embeddings de toutes les pages d'un site. Avec ça, Google construit une représentation complète du contenu global du site dans un résumé condensé. Voyez par exemple site2vecEmbedding dans le module QualityNsrNsrData.
Il y a plusieurs applications majeures à ça...
Évaluer la qualité de l'ensemble d'un site
J'ai trouvé plusieurs scores de qualité calculés pour le site dans son ensemble, basés sur de nombreux critères notamment la qualité du contenu et l'engagement des utilisateurs.
- score Keto (modèle QualityNsrPQData) : ce score semble se référer à un aspect spécifique de la qualité du site mais je n'ai pas pu identifier lequel
- score Rhubarb (modèle QualityNsrPQData) : score de qualité basé sur les signaux delta du site et de l'URL (ce n'est pas très clair...). Ce score semble évaluer la qualité d'un site sur la base des modèles d'URL et des changements au fil du temps.
- score spambrainLavcScores (modèle QualityNsrNsrData), représente une évaluation du contenu par le modèle SpamBrain de Google, qui se concentre sur la lutte contre le spam et les pratiques abusives.
- scores encodedDaftScore et encodedCalibratedFringeSitePriorScore (modèle QualityFringeFringeQueryPriorPerDocData) : ces scores évaluent si le contenu doit être considéré comme marginal ou peu fiable. Par exemple, encodedChardXlqHoaxPrediction représente une prédiction codée sur la probabilité de canular dans le contenu, tandis que encodedDaftScore encode un score pour les documents sur des sujets marginaux (Document About Fringe Topic)
- chromeInTotal (modèle QualityNsrNsrData) : vues Chrome au niveau du site, c'est-à-dire je suppose le nombre de pages vues d'après Chrome
- chardScoreVariance (modèle QualityNsrNsrData) : Variance Chard au niveau du site pour toutes les pages d'un site.
✅ Comment agir concrètement ?
C'est facile de dire qu'il faut maintenir une excellente qualité sur l'ensemble du site (contenu et satisfaction utilisateur), mais en pratique c'est vraiment compliqué à faire, surtout pour les gros sites.
C'est pour ça que j'ai mis au point 2 indicateurs dans mon outil RM Tech :
- QualityRisk évalue à quel point une page cumule des problèmes de qualité (essentiellement sous un angle technique cependant)
- l'indice Zombie va un cran plus loin en tenant compte également des performances de la page dans les SERP
Bien entendu, on est loin, très loin de l'analyse faite par Google, mais c'est le seul outil que je connaisse qui permette d'avoir une vue d'ensemble de la qualité du site.
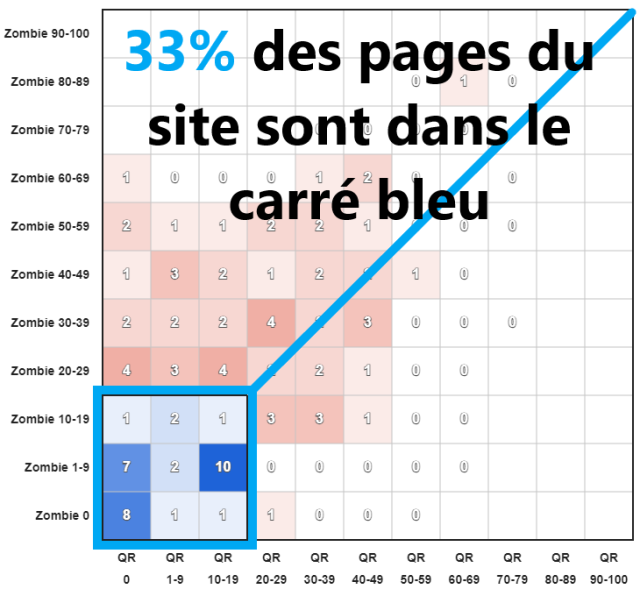
Regardez par exemple cette matrice QualityRisk Zombie, avec dans chaque case le pourcentage de pages. Vous voyez en un coup d'oeil si la majorité des pages du site sont de qualité (carré bleu en bas à gauche).
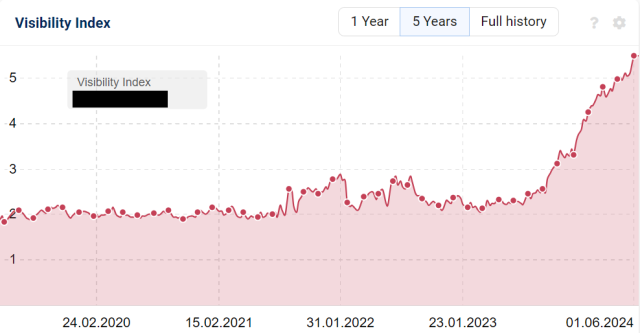
Exemple avec un site qui progresse super bien :
Voici sa courbe de visibilité Sistrix :
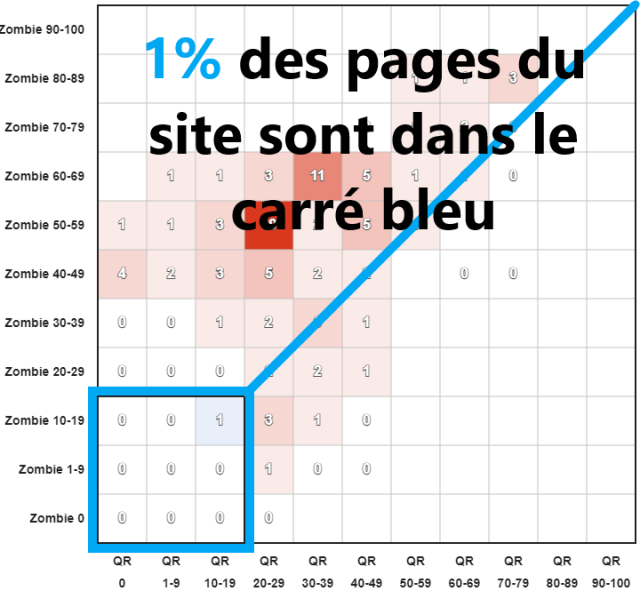
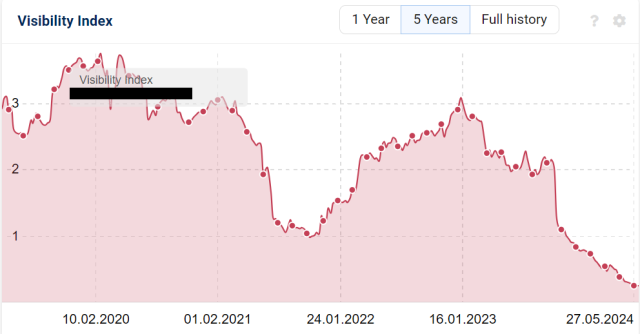
Exemple avec un site qui ne fait que chuter dans Google :
Voici sa courbe de visibilité Sistrix :
🎁 Obtenez cette matrice pour votre site (test gratuit)
Cette matrice vous indique la situation mais que faire pour améliorer le site ?
J'ai mis au point des algorithmes pour trouver quelles pages ont un fort potentiel SEO (si vous les retravaillez). Dans mon outil RM Console :
- tant qu'il y a des pages identifiées par le module "Pages à relancer", suivez les recommandations fournies pour faire remonter ces pages en déclin
- ensuite, tant qu'il y a des pages identifiées par le module "Pages à optimiser", suivez les recommandations fournies pour améliorer ces pages
Avec ça, vous améliorez la qualité du site, en mettant l'utilisateur au centre des optimisations.
Identifier la thématique principale du site et la dispersion des pages
- siteFocusScore du module QualityAuthorityTopicEmbeddingsVersionedItem quantifie le degré de focalisation d'un site sur un sujet particulier
- siteRadius mesure à quel point le contenu des pages individuelles s'écarte du thème central du site
Je n'arrive pas à avoir la certitude que c'est en place, mais ça pourrait expliquer pourquoi certains sites chutent alors qu'ils ajoutent du contenu de qualité. Y compris un contenu qui génère du trafic, comme en témoigne Glenn Gabe.
✅ Comment agir concrètement ?
Je vous conseille d'identifier les répertoires ou sections du site qui génèrent le plus de trafic.
Si vous avez déjà une idée des répertoires, c'est facile à faire avec Search Console. Dans le rapport Performances (résultats de recherche), faites un filtre sur les pages.
Si vous ne savez pas, regardez le module Répertoires de RM Console :
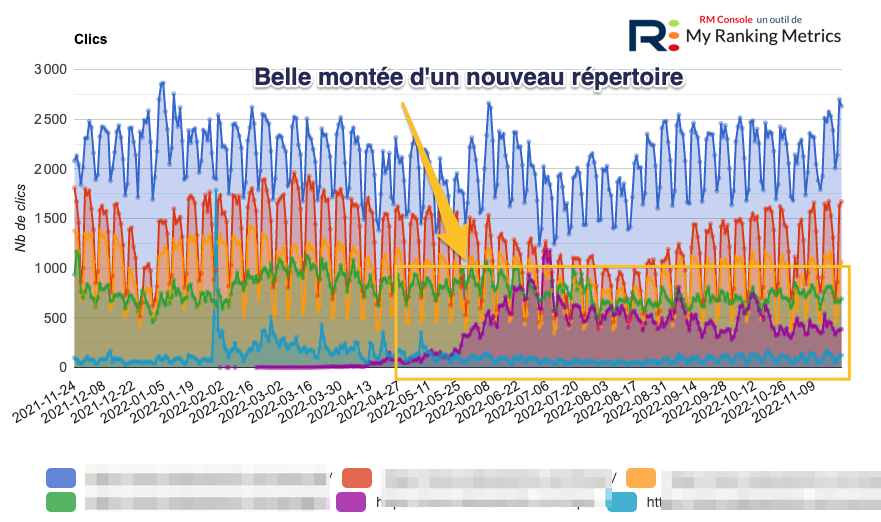
Ensuite, demandez-vous si cela correspond bien à votre principal domaine thématique, à votre spécialité.
Enfin, vérifiez que ces contenus sont non seulement de qualité mais plaisent aux utilisateurs.
Repérer les évolutions d'un site dans son ensemble
Les "embeddings" peuvent être versionnés afin de suivre les changements au fil du temps. Cela permet de suivre l'évolution du contenu et de la qualité d'un site.
Le numéro de version du module QualityAuthorityTopicEmbeddingsVersionedItem est un exemple de la manière dont les versions sont suivies pour les embeddings.
Analyse du comportement de l'utilisateur
On le savait (supposait) depuis longtemps, très longtemps. Puis Pandu Nayak a fait des révélations à l'automne 2023 au cours du procès de Google devant le DOJ. Ces documents semblent largement le confirmer : Google se base énormément sur les données liées à l'utilisateur, récoltées dans les SERP et par Chrome.
Importance cruciale de la satisfaction de l'utilisateur ou le rôle majeur de l'UX dans le SEO
Google scrute le comportement de l'utilisateur sur ses pages de résultats (SERP) mais également sur nos sites, avec le plus grand mouchard qu'il ait mis au point, j'ai nommé Chrome.
✅ Comment agir concrètement ?
D'abord, intéressez-vous aux SERP, avec les données à votre disposition : celles de la Search Console.
Cherchez si vous avez des pages (ou mots-clés) avec un très faible CTR (taux de clics) pour une bonne position avec beaucoup d'impressions. Dans ce cas, vous avez un problème à étudier. Ne vous faites pas avoir avec le cas particulier des liens des sitelinks pour lesquels c'est normal d'avoir un faible CTR.
Ajustez vos contenus en fonction pour qu'ils répondent parfaitement aux besoins des utilisateurs. Virez les contenus (textes) qui ne sont là que "pour le SEO".
Vérifiez que le premier écran répond très bien aux besoins de l'utilisateur (sur mobile ou ordinateur, donc ce qui est au-dessus de la ligne de flottaison). L'internaute doit se dire qu’il est arrivé au bon endroit et que ça vaut le coup de poursuivre sa visite.
Le format de ce 1er écran est absolument capital. Parfois le texte est la bonne solution, mais souvent ce sont d'autres formats : image, tableau, vidéo, formulaire, etc.
Le comportement des utilisateurs qui arrivent sur votre page (surtout ceux qui viennent des SERP Google) va déterminer si votre contenu est utile. Même avec un contenu de haute qualité, si le comportement des internautes montre une déception, alors l'algorithme de Google pourrait considérer la page comme "non utile". Je fais référence ici à l'appellation Helpful Content de Google. Si votre site a chuté lors d'un HCU, vous êtes concerné.
Que faire concrètement ? J'ai partagé une liste des améliorations à faire à chaque page, mais c'est un gros boulot. J'utilise désormais l'IA pour m'aider à comprendre ce qui ne va pas dans mes pages. Mon outil RM Console facilite ce type d'analyse et fait gagner du temps pour optimiser une page. Au final c'est à vous d'améliorer chaque page, mais vous avez des pistes.
Analyse des contenus
Dans ces documents, le modèle PerDocData liste 132 attributs rien que pour une page. Et ce n'est pas le seul modèle dédié à une page. Autant vous dire qu'il y a beaucoup de choses à étudier pour mieux comprendre comment Google analyse les contenus des pages.
Nombreux scores calculés pour chaque page
Ce n'est pas une surprise : Google évalue toutes sortes de choses pour chaque page. Par exemple dans le modèle PerDocData j'ai trouvé plein de choses en rapport avec la détection du spam ou la qualité de la page :
- uacSpamScore : score de spam UAC (je ne connais pas sa signification)
- trendspamScore : nombre de requêtes trendspam correspondantes
- ymylHealthScore : scores du classificateur de santé YMYL
- ymylNewsScore : scores du classificateur d'actualités YMYL
- spambrainData : scores issus de spambrain pour des parties du site (chunks)
- OriginalContentScore : score du contenu original (seules les pages à faible contenu ont ce champ)
- DocLevelSpamScore : score de spam du document
- KeywordStuffingScore : score de bourrage de mots-clés
- GibberishScore : score de charabia
- freshboxArticleScores : scores des classificateurs liés à la fraîcheur : score de l'article freshbox, score du blog en direct et score de l'article au niveau de l'hôte
- commercialScore : mesure de la "commercialité" du document. Un score > 0 indique que le document est commercial (c'est-à-dire qu'il vend quelque chose)
(il y en a encore des dizaines voire des centaines d'autres pour l'analyse de chaque page)
✅ Comment agir concrètement ?
Préférant ne pas spéculer, je n'ai pas d'actions concrètes directement dérivées de ces données. Voici tout de même ce que je recommande actuellement pour l'optimisation des contenus :
- concentrez-vous sur ce que cherche l'internaute (l'intention de recherche de l'utilisateur)
- adaptez-vous à ses besoins, ses connaissances, le niveau dans son parcours d'achat
- soyez hyper complet sur le sujet, en découpant en plusieurs pages pour que chacune soit assez focalisée (de quoi exploiter le maillage interne)
- utilisez le vocabulaire de vos personas, des synonymes et tout ce qui peut renforcer le champ lexical
- mentionnez toutes les entités, optimisez la saillance de celles attendues par Google. La saillance d'une entité (entity salience) mesure son importance ou sa centralité par rapport au texte dans son ensemble.
- évitez tout bavardage et remplissage inutiles
Pour le fun, les dinosaures du SEO comme moi s'amuseront de lire qu'il existe l'attribut toolbarPagerank, une valeur entière entre 0 et 10 considérée comme "Fake PR"...

Mise à jour significative du contenu
Google suit de très près les dates et notamment les mises à jour des contenus. On apprend qu’il existe la notion de "date de la dernière mise à jour significative du contenu de la page" (source : modèle NlpSaftDocument).
Bien entendu, c'est totalement insuffisant de modifier uniquement la date de l'article, ou changer l'année dans le titre.
✅ Comment agir concrètement ?
Actualiser vos contenus est important pour garantir un crawl régulier de Google (mais pas seulement pour ça) :
Les contenus mis à jour de manière irrégulière ont la priorité de stockage la plus basse pour Google et n'apparaissent certainement pas comme étant frais. Il est très important d'actualiser votre contenu.
Andrew Ansley (source Search Engine Land 30 mai 2024)
J'ai déjà expliqué sur WebRankInfo pourquoi il faut mettre à jour son site.
Je fournis aussi un guide pour actualiser son site grâce à RM Console via l'IA et des données précises liées à chaque page.
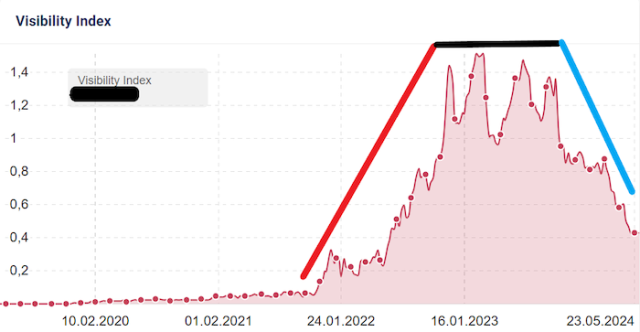
Regardez cet exemple de site qui a publié plein de pages en 2022 et jamais fait de mises à jour. 2 ans plus tard ça s'écroule :
Analyse sémantique, importance des entités
En tant que moteur de recherche sémantique, Google repose de façon intensive sur l'analyse des entités et de leurs relations. Cela mérite un détour !
Importance des entités et de leurs mentions
On trouve un grand nombre de références aux entités et aux mentions des entités dans les documents (voir par exemple le modèle NlpSaftDocument et les autres associés comme NlpSaftMention).
Google fait une analyse sémantique approfondie des contenus du web pour extraire les entités et définir leurs relations. Dans l'architecture logicielle, Google cite souvent SAFT qui signifie Structured Annotation Framework and Toolkit.
À quoi ça sert à Google ? En citant encore Jeff :
- Compréhension du contexte : en résolvant les coréférences et en annotant les entités dans le texte, SAFT permet de mieux comprendre le contexte et la signification des entités dans le document.
- Cartographie des relations : Grâce à des relations détaillées et à des nœuds sémantiques, SAFT cartographie les relations entre les entités, ce qui permet de détecter des interactions et des connexions complexes.
- Désambiguïsation des entités : Les capacités de profilage et d'annotation de SAFT contribuent à la désambiguïsation des entités, en veillant à ce que les différentes références à la même entité soient correctement identifiées et reliées.
- Enrichissement sémantique : Les riches annotations sémantiques et les représentations structurées fournies par SAFT améliorent la compréhension sémantique globale du document, ce qui facilite l'extraction d'informations significatives et améliore la pertinence des recherches.
- Intégration des connaissances : SAFT s'intègre au Knowledge Vault de Google, contribuant à la fusion et à la mise en relation d'entités provenant de différentes sources de données, ce qui permet d'enrichir le graphe de connaissances et d'améliorer la recherche d'informations.
J'espère qu'avec cette liste, vous arrêterez de dire que vous faites une "optimisation sémantique" alors que vous ne faites qu'enrichir le champ lexical d'un texte...
✅ Comment agir concrètement ?
Les entités ne concernent pas seulement les auteurs, ça concerne tout ! Google est depuis longtemps (2012 ?) un moteur de recherche sémantique, ça signifie qu'il ne se base plus sur les mots mais sur leur sens.
Je l'ai déjà expliqué il y a bien longtemps : votre SEO doit être basé sur une structure d'entités reliées entre elles par des mentions (et des liens).
En complément d'une approche éditoriale basée sur les entités (on n'est pas loin des cocons sémantiques), je recommande d'exploiter les données structurées de façon complète. Cela peut passer par la création d'un Knowledge Graph propre au site.
Si cela vous intéresse, lisez mon dossier Données structurées pour un SEO avancé.
Autres éléments
Je termine par d'autres points trouvés dans les documents ayant attiré mon attention, mais de façon plus secondaire. J'aborde également quelques affirmations lues ailleurs et qui me semblent erronées.
Branding
La notion de marque est présente dans les documents, mais pas de façon aussi évidente que ce qu'on pourrait croire. Même si c'est une excellente chose d'avoir le maximum de trafic marque, je ne l'ai pas identifié dans les documents.
Les marques sont avant tout vues comme des entités (j'ai trouvé brandEntityId par exemple). D'après la documentation, les marques sont entièrement réconciliées avec les entités KG (Knowledge Graph), de sorte qu'il ne devrait jamais y avoir d'ambiguïté quant à la marque qui s'applique.
✅ Comment agir concrètement ?
Sur votre site, présentez la marque en détails : histoire, à propos, équipe, adresse postale des établissements. Faites bien attention à être cohérent (toujours fournir les mêmes informations).
En dehors du site, plus vous avez de mentions de votre marque, plus ça aide Google à comprendre l'importance de la marque.
Et bien entendu, une bonne façon de suivre la force de la marque, c'est de suivre le trafic généré par la marque. Faites-le avec une expression régulière dans Google Search Console. Pour ma part, c'est inclus nativement dans RM Console.
C'est sympa aussi d'être prévenu chaque semaine si de nouvelles requêtes marque ont été faites (jamais vues avant). C'est également inclus dans le système d'alertes nouveaux mots-clés de RM Console.
Backlinks
On trouve beaucoup de détails sur Penguin, mais rien de nouveau pour moi.
Google semble avoir une politique de stockage différente pour les contenus moins susceptibles d'être servis. On pourrait en conclure que cela dévalorise les liens provenant de contenus anciens et non actualisés.
Dit autrement, les liens provenant d'un contenu plus frais où la source du lien a du trafic semblent avoir plus de puissance.
Cohérence des dates dans une page
Il est fréquent que les dates figurant dans les données structurées (et OpenGraph) ne soient pas synchronisées avec les dates de la page. Idem avec les dates figurant dans le sitemap XML.
Tous ces éléments doivent être synchronisés pour permettre à Google de comprendre au mieux l'actualité du contenu.
Lorsque vous actualisez votre contenu en déclin, assurez-vous que toutes les dates sont identiques afin que Google reçoive un signal cohérent.
"Google n'utilise que les 20 dernières versions d'un document"
Comme moi, vous avez peut-être lu ça dans des analyses "Google's documents leak". Je ne suis pas d'accord avec cette affirmation, j'ai l'impression que Google gère l'historique des 20 dernières URL du document. Les URL, pas le contenu.
Voici la mention dans les documents, à vous de vous faire votre idée :
urlHistory (type: GoogleApi.ContentWarehouse.V1.Model.CrawlerChangerateUrlHistory.t, default: nil) - Url change history for this doc (see crawler/changerate/changerate.proto for details). Note if a doc has more than 20 changes, we only keep the last 20 changes here to avoid adding to much data in its docjoin.
Fuite des documents Google, modèle CompositeDocIndexingInfo (source)
"Google pénalise les petits sites perso"
Voilà autre chose que j'ai lu dans certains articles. Pourtant, la seule mention que j'ai trouvée parle positivement des sites perso :
smallPersonalSite (type: number(), default: nil) - Score of small personal site promotion go/promoting-personal-blogs-v1
Fuite des documents Google, modèle QualityNsrNsrData (source)
J'ai sans doute raté une ligne dans les 2500 documents...
Nearest Seed PageRank
Les documents mentionnent plusieurs types de PageRank, dont pageRank_NS (NS signifie Nearest Seed).
D'après Andrew Ansley, NS se concentre sur un sous-ensemble localisé du réseau (le web) autour des nœuds de départ (pages). La proximité et la pertinence sont des éléments clés. On peut imaginer calculer un PageRank personnalisé (en fonction de l'intérêt de l'utilisateur ?) en tenant compte des pages d'un même groupe de sujets plutôt que de l'ensemble du web. Je ne sais pas à quel point c'est différent du PageRank thématique.
Google peut limiter le nombre de résultats par type de contenu
En d'autres termes, il peut limiter à X le nombre d'articles de blog ou à Y le nombre d'articles d'actualité pouvant apparaître dans une page de résultats donnée.
Avoir une idée de ces limites de diversité peut nous aider à décider des formats de contenu à créer lors de la sélection des mots-clés à cibler. Par exemple, si nous savons que la limite pour les articles de blog est de trois et que nous ne pensons pas pouvoir surclasser l'un d'entre eux, alors peut-être qu'une vidéo est un format plus viable pour ce mot-clé.
Néanmoins, ça me semble hasardeux de se baser dessus, étant donné que les pages qui sortent dans le top 10 peuvent changer à tout moment, tout comme ces valeurs X ou Y.
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.
