SEMrush a publié le 13/11/2017 les résultats d'une étude des Ranking Factors, c'est-à-dire les critères qui agissent sur le positionnement dans les résultats de recherche. Il s'agit de la 2ème étude, une mise à jour de la précédente sortie début 2017.
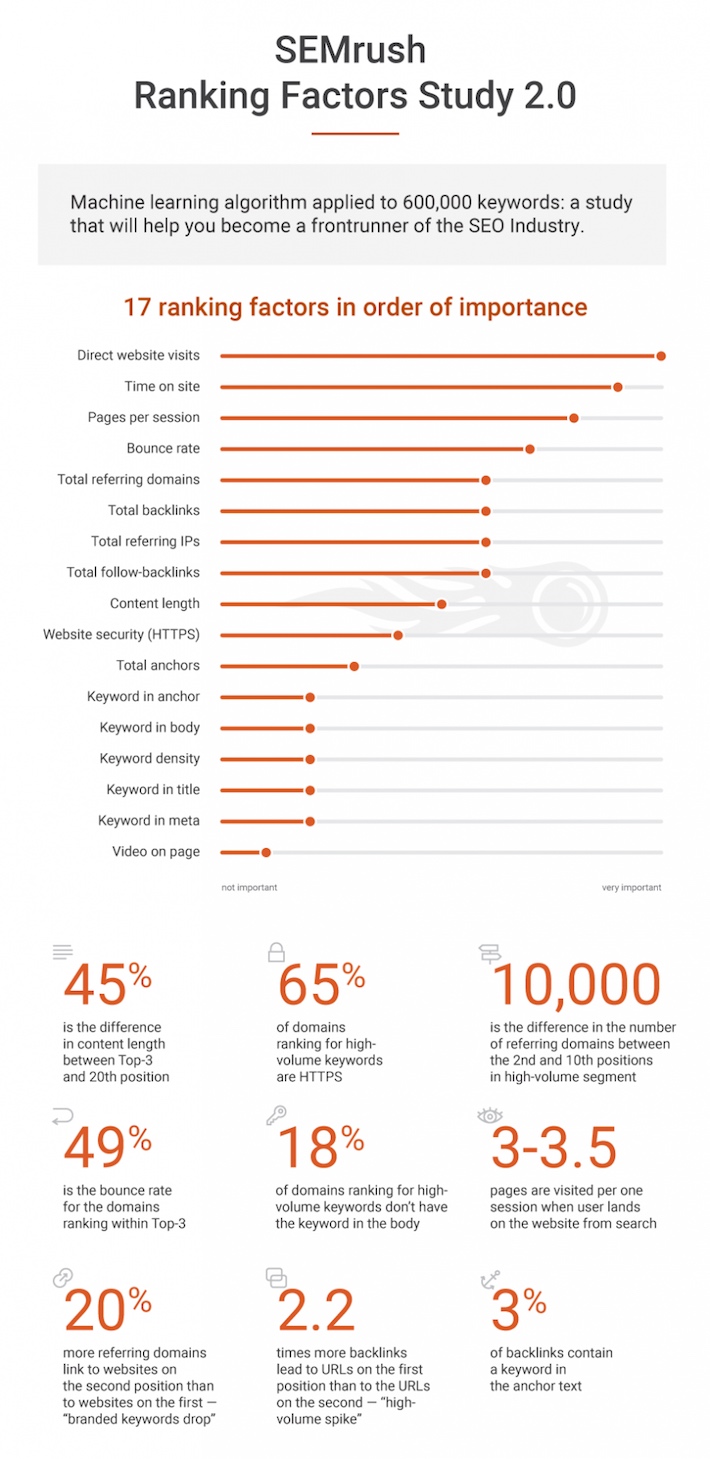
Selon eux, le critère n°1 est de loin le trafic direct, suivi par des métriques liées aux sessions de l'internaute sur le site (temps passé sur le site, nombre de pages vues, taux de rebond).
Ensuite seulement arrivent les critères de popularité traditionnels (liés aux backlinks) et au contenu éditorial (notamment sa taille).
Vous pouvez télécharger le rapport ici (il y a aussi un document qui présente la méthodologie).
Que pensez-vous de leur étude et des résultats présentés ?
Voici mon humble avis, pour démarrer la discussion...
J'ai choisi de pointer du doigt 4 points
1- Pour ma part, j'ai d'abord regardé le doc de méthodologie, car je faisais partie des "très sceptiques" quand la 1ère version de l'étude était sortie. Je déteste qu'on appelle ça une analyse des ranking factors, car je me demande s'il existe vraiment une entité au monde (externe à Google) qui puisse réellement identifier et mesurer l'importance des ranking factors.
La plupart de ceux qui font ce genre d'études utilisent ces termes (dans le titre) car ça marche bien pour la comm.
Dans le cas présent, je note une incohérence car dans les explications, les auteurs nient le fait qu'il s'agisse d'une étude de ranking factors. C'est très net avec le début de la conclusion (du doc méthodo) :
2- J'ai apprécié leur virage à 180° : enfin, ils admettent qu'avoir basé les études précédentes sur de la corrélation était une erreur.
")
Si des experts en algorithmie pouvaient nous donner leur avis, ça serait top.
En tout cas au final je n'arrive toujours pas à être convaincu qu'on puisse faire de l'ingénierie inverse dans le cas qui nous intéresse...
3- Selon cette étude, le critère le plus important est le "trafic direct". Je suis vraiment très sceptique... Je pense même que c'est une erreur d'affirmer ça. Vous trouverez dans cet article et surtout ses commentaires de solides arguments pour l'expliquer.
En gros, le trafic direct est le canal d'acquisition que j'appelle "poubelle"... En effet, on classe dedans toute source de trafic inconnue. C'est en fait assez rare qu'il s'agisse de trafic directement lié à la notoriété, il y a plein d'autres cas de figure qui alimentent ce trafic direct (et la montée en puissance de HTTPS n'aide pas). Ce qui réduit d'autant la précision de ce critère, et me fait douter de la place qui lui est accordée dans l'étude.
A mon avis, Google pourrait se baser sur des métriques liées à la renommée de la marque (ou plus généralement du nom) du site. Par exemple le nombre de recherches de la marque, ou de recherches combinant marque et mot-clé.
Vous-même pouvez le mesurer en étudiant les termes de recherche dans Search Console.
Mais on ne peut pas faire le raccourci "trafic direct" = "trafic de notoriété"
4- Je suis également sceptique sur les critères liés à la session de l'internaute (notamment ce qui concerne le temps). J'ai longuement expliqué pourquoi dans ce dossier où je décortique les métriques de Google Analytics concernées.
Je pense que les critères qu'ils mettent en avant sont souvent (mais pas toujours) le reflet de sites de qualité, mais que cela ne signifie pas pour autant que ce soit la cause de leur bon positionnement. Par ailleurs, je crains qu'il y ait trop de "bruit" dans la mesure de ces valeurs, surtout dans leur étude. On ne sait pas d'où viennent les valeurs, ça semble venir des données Analytics récoltées sur leur plateforme. Je fais la même chose sur My Ranking Metrics et je vois bien toute la difficulté à avoir des statistiques fiables. En tout cas pour ma part, j'exclus plein de cas de figure pour éviter qu'ils faussent l'ensemble.
Je finis par une note plus positive : je suis assez d'accord avec l'idée qu'un site doit avoir de l' E.A.T. pour réussir. Il s'agit en anglais de Expertise, Authoritativeness, and Trustworthiness. Que l'on peut traduire par Expertise, Autorité et Confiance.
(autorité dans le sens "faire autorité", le susbstantif autorité n'est pas la traduction idéale de Authoritativeness)
Il s'agit de "concepts" largement évoqués dans les consignes officielles de Google à ses évaluateurs de la qualité des résultats (Search Quality Raters). Vous pouvez les consulter dans ce PDF en anglais.
Cela dit encore une fois, je vois mal comment on peut prouver que ces concepts sont utilisés par Google. Et si oui, quelles métriques sont évaluées ?
Par ailleurs, j'ai apprécié leur gros travail et le fait qu'il soit partagé pour que la communauté SEO en discute.
Selon eux, le critère n°1 est de loin le trafic direct, suivi par des métriques liées aux sessions de l'internaute sur le site (temps passé sur le site, nombre de pages vues, taux de rebond).
Ensuite seulement arrivent les critères de popularité traditionnels (liés aux backlinks) et au contenu éditorial (notamment sa taille).
Vous pouvez télécharger le rapport ici (il y a aussi un document qui présente la méthodologie).
Que pensez-vous de leur étude et des résultats présentés ?
Voici mon humble avis, pour démarrer la discussion...
J'ai choisi de pointer du doigt 4 points
1- Pour ma part, j'ai d'abord regardé le doc de méthodologie, car je faisais partie des "très sceptiques" quand la 1ère version de l'étude était sortie. Je déteste qu'on appelle ça une analyse des ranking factors, car je me demande s'il existe vraiment une entité au monde (externe à Google) qui puisse réellement identifier et mesurer l'importance des ranking factors.
La plupart de ceux qui font ce genre d'études utilisent ces termes (dans le titre) car ça marche bien pour la comm.
Dans le cas présent, je note une incohérence car dans les explications, les auteurs nient le fait qu'il s'agisse d'une étude de ranking factors. C'est très net avec le début de la conclusion (du doc méthodo) :
Il n’y a aucune garantie que si vous améliorez vos métriques de site pour n’importe quel facteur susmentionné, vos pages se mettront à mieux ranker.
2- J'ai apprécié leur virage à 180° : enfin, ils admettent qu'avoir basé les études précédentes sur de la corrélation était une erreur.
J'ai donc lu les explications sur l'algo Random Forest. Le pb est que malgré mon profil d'ingénieur, je suis dépassé par les explications. Si 1% des lecteurs de l'étude arrivent à comprendre la méthode, je serais déjà étonnéPourquoi nous pensons que l’analyse de corrélation est mauvaise pour les études de facteurs de ranking
Si des experts en algorithmie pouvaient nous donner leur avis, ça serait top.
En tout cas au final je n'arrive toujours pas à être convaincu qu'on puisse faire de l'ingénierie inverse dans le cas qui nous intéresse...
3- Selon cette étude, le critère le plus important est le "trafic direct". Je suis vraiment très sceptique... Je pense même que c'est une erreur d'affirmer ça. Vous trouverez dans cet article et surtout ses commentaires de solides arguments pour l'expliquer.
En gros, le trafic direct est le canal d'acquisition que j'appelle "poubelle"... En effet, on classe dedans toute source de trafic inconnue. C'est en fait assez rare qu'il s'agisse de trafic directement lié à la notoriété, il y a plein d'autres cas de figure qui alimentent ce trafic direct (et la montée en puissance de HTTPS n'aide pas). Ce qui réduit d'autant la précision de ce critère, et me fait douter de la place qui lui est accordée dans l'étude.
A mon avis, Google pourrait se baser sur des métriques liées à la renommée de la marque (ou plus généralement du nom) du site. Par exemple le nombre de recherches de la marque, ou de recherches combinant marque et mot-clé.
Vous-même pouvez le mesurer en étudiant les termes de recherche dans Search Console.
Mais on ne peut pas faire le raccourci "trafic direct" = "trafic de notoriété"
4- Je suis également sceptique sur les critères liés à la session de l'internaute (notamment ce qui concerne le temps). J'ai longuement expliqué pourquoi dans ce dossier où je décortique les métriques de Google Analytics concernées.
Je pense que les critères qu'ils mettent en avant sont souvent (mais pas toujours) le reflet de sites de qualité, mais que cela ne signifie pas pour autant que ce soit la cause de leur bon positionnement. Par ailleurs, je crains qu'il y ait trop de "bruit" dans la mesure de ces valeurs, surtout dans leur étude. On ne sait pas d'où viennent les valeurs, ça semble venir des données Analytics récoltées sur leur plateforme. Je fais la même chose sur My Ranking Metrics et je vois bien toute la difficulté à avoir des statistiques fiables. En tout cas pour ma part, j'exclus plein de cas de figure pour éviter qu'ils faussent l'ensemble.
Je finis par une note plus positive : je suis assez d'accord avec l'idée qu'un site doit avoir de l' E.A.T. pour réussir. Il s'agit en anglais de Expertise, Authoritativeness, and Trustworthiness. Que l'on peut traduire par Expertise, Autorité et Confiance.
(autorité dans le sens "faire autorité", le susbstantif autorité n'est pas la traduction idéale de Authoritativeness)
Il s'agit de "concepts" largement évoqués dans les consignes officielles de Google à ses évaluateurs de la qualité des résultats (Search Quality Raters). Vous pouvez les consulter dans ce PDF en anglais.
Cela dit encore une fois, je vois mal comment on peut prouver que ces concepts sont utilisés par Google. Et si oui, quelles métriques sont évaluées ?
Par ailleurs, j'ai apprécié leur gros travail et le fait qu'il soit partagé pour que la communauté SEO en discute.
 !!!
!!!