
Ce qu'il faut retenir, détaillé dans ce guide :
- l'indice QualityRisk d'une page (entre 0 et 100) mesure à quel point une page cumule des problèmes ou sous-optimisations SEO
- un bilan de QualityRisk sur tout un site fournit son état de santé SEO
- il est très efficace pour prioriser vos actions d'optimisation du référencement naturel
- les pages sans problème (QualityRisk 0) génèrent 13 fois + de visites SEO que celles qui en ont (QualityRisk > 20), source
- inventé par Olivier Duffez et Fabien Facériès en 2016, il est mis à jour en continu pour suivre l'évolution de l'algo de Google
- il est disponible uniquement dans RM Tech, l'outil d'audit SEO de MyRankingMetrics
- vous pouvez obtenir un bilan QualityRisk gratuit pour votre site
Voici des accès rapides à ce long dossier : définition, qualité et algo Google, utilisation de QualityRisk, exemples de pages
C'est quoi le score QualityRisk ?
Quelques définitions et explications rapides avant de commencer...
Définition de QualityRisk
L'indice QualityRisk d'une page est une valeur entre 0 et 100 qui indique à quel point la page cumule des problèmes ou sous-optimisations SEO. On l'écrit QR en abrégé. Plus QR est élevé, plus la page est de mauvaise qualité d'après l'algorithme de RM Tech, et sans doute aussi de Google.
D'où vient QualityRisk ?
Je suis SEO professionnel depuis 2003, si bien que je connais très bien l'évolution de l'algorithme de Google. Comme je le détaille plus loin, Google tient compte de la qualité globale d'un site. J'ai donc travaillé avec mes collègues de Ranking Metrics pour améliorer RM Tech (notre outil d'audit technique SEO créé en 2014) afin qu'il sache repérer les pages de mauvaise qualité.
Après plusieurs mois de recherche, de tests et de développement, nous avons abouti en 2016 à la première version de notre algorithme QualityRisk. Cet algo "maison" calcule le score "Quality Risk" de chaque page indexable. On peut le voir comme la probabilité qu'un internaute (ou Google) l'estime de mauvaise qualité.
Depuis, QualityRisk a été amélioré et mis à jour pour refléter au mieux l'évolution de l'algorithme de Google.
QualityRisk, qualité des pages et algo Google
La notion de qualité est subjective, mais un algorithme et des bonnes données suffisent à faire une évaluation. Google est devenu très bon à ça, voilà pourquoi il faut vous aussi la mesurer sur votre site. Explications...
L'estimation de la qualité des sites, au coeur de l'algo de Google
Depuis que Panda est sorti en 2011, Google n'a cessé d'améliorer son algorithme pour tenter de repérer les sites de mauvaise qualité. Panda et son successeur Phantom sont désormais inclus dans le process global du moteur de recherche pour évaluer la qualité des sites (ou des pages, j'y reviens plus loin).
On a vu ensuite que Google cherche à détecter les pages satellite, à vérifier que l'utilisateur est satisfait de sa visite sur le site. Plus récemment avec Helpful Content Update, Google a étendu tout ça à la notion de "contenu utile" qui doit être "fait avec les humains en tête et non les moteurs de recherche". Si vous êtes perdu, lisez mon récapitulatif des algos SEO de Google...
Bref, il est indéniable que Google met le paquet pour évaluer la qualité des sites (afin de pénaliser les mauvais, ou de favoriser les bons, à vous de choisir entre le verre à moitié vide ou à moitié plein). Cette analyse de la qualité se décompose au moins en 2 familles :
- d'abord l'évaluation de la qualité du site lui-même, de ses pages et de leur contenu
- ensuite l'évaluation de la satisfaction de l'internaute qui visite le site (particulièrement l'internaute que Google envoie depuis les SERP, résultats naturels)
Si vous pensez qu'un algo ne peut pas vraiment évaluer la qualité, notion fort subjective, détrompez-vous ! Particulièrement depuis que Google a investi massivement dans la recherche en intelligence artificielle (deep learning, machine learning).
Google évalue la qualité pour l'ensemble de votre site
A moins d'être développeur de l'algo de Google, il est impossible de l'affirmer... Mais je suis convaincu que Google calcule un score global de qualité pour chaque site. Plus vous accumulez de pages de mauvaise ou faible qualité sur votre site, plus vous plombez votre score, plus vous pénalisez votre référencement.
D'ailleurs, dès la sortie de Panda, le responsable de la lutte contre le spam de l'algo Google, à savoir Matt Cutts, avait affirmé que si une partie d'un site est perçue comme de mauvaise qualité par Panda, c'est l'ensemble du site qui peut être pénalisé. On retrouve cette affirmation dans le blog officiel de Google :
Notez également que si certaines pages d'un site Web sont de mauvaise qualité, cela peut affecter le classement de l'ensemble du site. Par conséquent, vous pouvez supprimer ces pages afin d'optimiser le classement de celles qui sont de meilleure qualité ou encore améliorer leur contenu, les intégrer à des pages plus utiles ou les transférer vers un autre domaine.
Amit Singhal (Google Fellow) source
J'ai justement une solution à vous proposer pour ça ! Lisez bien la suite...
De la même manière, concernant l'algo Page Layout qui pénalise l'excès de publicité (surtout au-dessus de la ligne de flottaison), Matt Cutts avait expliqué que l'algorithme se base sur une évaluation moyenne sur l'ensemble du site.
Le risque est donc de ne pas se rendre compte qu'à force d'accumuler des pages de mauvaise qualité, c'est le site entier qui se trouve handicapé. D'après mon expérience, le plus fréquent est que le propriétaire du site ne se rend même pas compte qu'il propose des pages de mauvaise qualité !
Maintenant que vous comprenez pourquoi il faut vérifier la qualité sur l'ensemble de votre site, voyons comment faire...
Comment utiliser QualityRisk ?
Je vous explique ici comment obtenir l'indice QualityRisk de toutes vos pages et surtout comment l'exploiter pour prioriser vos actions, tout en améliorant la qualité des pages concernées.
À quoi sert QualityRisk ?
Voici les principales utilités :
- à l'échelle du site, connaître la répartition des pages selon leur indice QualityRisk permet de savoir en un coup d'oeil si le site est bien travaillé et a priori de qualité. Très utile en avant-vente ou pour découvrir un site à travailler.
- au niveau d'une page, l'indice QR indique à quel point la page est sous-optimisée SEO. Voyez le verre à moitié rempli : l'indice vous montre le potentiel d'amélioration de la page.
- c'est très pratique pour suivre l'évolution SEO : si vous travaillez correctement, QualityRisk doit diminuer, tendre vers 0. Vérifiez-le pendant une refonte (même en préprod !) et même en permanence via un monitoring SEO.
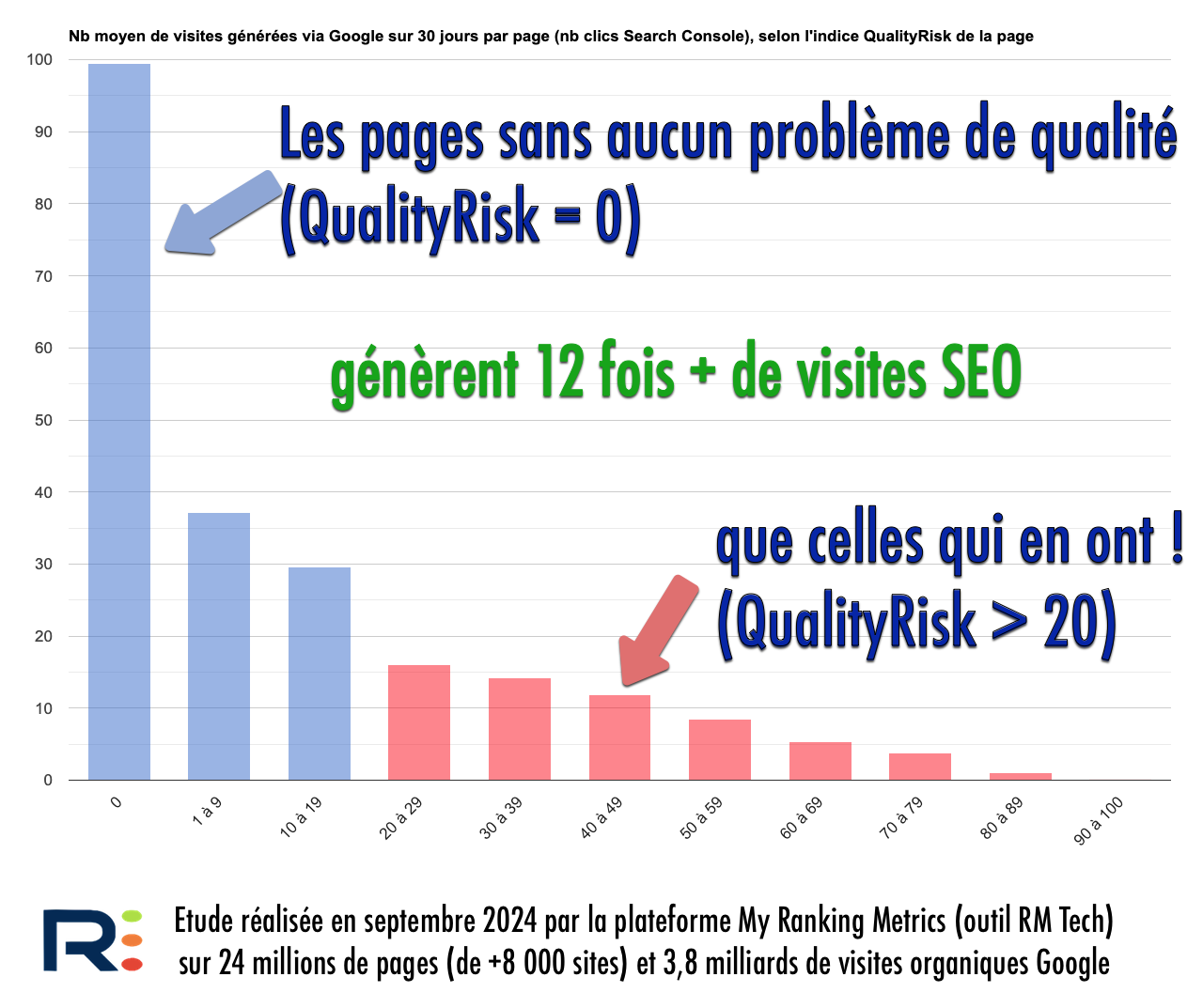
Peu de problèmes QualityRisk = gros trafic SEO
QualityRisk est calculé sans connaître les performances des pages (visibilité dans Google, génération de trafic). Pourtant, on observe une corrélation forte, ce qui veut dire que l'indice QualityRisk est un bon prédicteur de succès SEO.
Pour guider votre SEO, vous pouvez vous fier à cet indicateur, tout en le complétant par vos propres analyses (qualité des contenus éditoriaux et des médias, alignement avec l'intention de recherche, etc.).
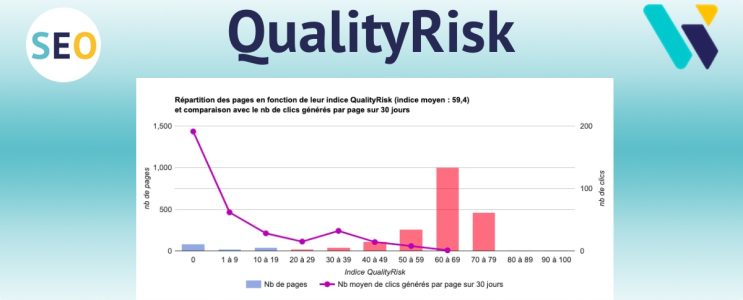
Voici les résultats de ma dernière étude d'ampleur :
À retenir :
Les pages sans aucun problème de qualité (QualityRisk 0) génèrent 12 fois + de visites SEO que celles qui en ont (QualityRisk > 20).
Étude RM Tech 2024 (source)
- il vous faut le maximum de pages à QualityRisk 0 : regardez dans votre audit RM Tech si c'est OK pour votre site
- si vous n'avez pas d'audit, demandez un pré-audit gratuit
- ensuite, corrigez les problèmes pour atteindre QualityRisk 0. Suivez la méthode décrite ici (l'audit fournit toutes les données nécessaires)
- cet article pourrait aussi vous aider en complément : guide de QualityRisk et Pages Zombies
- besoin d'aide pour prioriser et savoir par où commencer ? Demandez l'avis d'un expert (c'est gratuit)
Comment calculer QualityRisk ?
Le seul outil qui peut calculer l'indice QualityRisk est RM Tech, mon outil d'audit technique SEO.
Si vous voyez d'autres agences ou freelances vous parler de QualityRisk, soit ces personnes utilisent RM Tech (très bonne idée), soit elles exploitent mon concept en bricolant quelque chose pour y ressembler...
Quelle est la formule de QualityRisk ?
La formule de QualityRisk n'est pas publique, c'est un secret de MyRankingMetrics !
Elle est basée sur un grand nombre de données récoltées et calculées pendant chaque audit RM Tech. On retrouve évidemment les critères classiques de l'optimisation on-page et on-site du SEO.
Consultez un rapport d'audit RM Tech pour obtenir des informations à jour, car QualityRisk évolue régulièrement.
À quoi ressemble un bilan QualityRisk pour tout un site ?
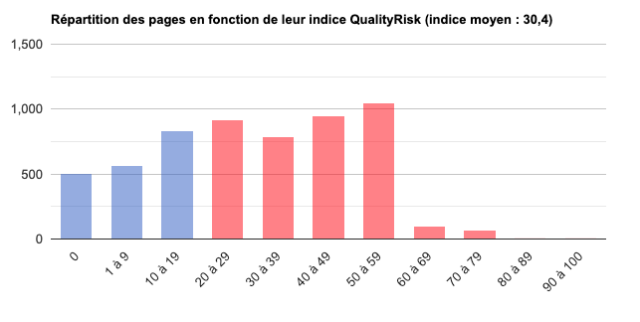
Dans l'outil RM Tech, les URL sont crawlées en suivant les liens à partir de la page de départ. Pour chaque URL indexable, son indice QualityRisk (QR) est calculé (nombre entier entre 0 et 100).
Une fois le calcul terminé pour tout le site, un histogramme est affiché dans le rapport d'audit. Il montre, pour chaque tranche de QR, combien de pages ont été trouvées.
Même si je vous conseille d'avoir QR zéro pour le maximum de pages, le graphique affiche en rouge les tranches à partir de QR 20.
Si vous n'avez pas accès à Search Console pour faire l'audit, le graphique indique uniquement QualityRisk, comme ici (audit du site service-public.fr) :
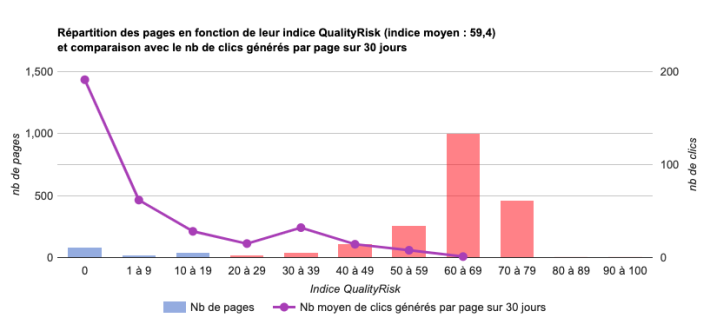
Si vous avez accès à Search Console, le graphique affiche aussi une courbe du trafic moyen généré par les pages dans chaque tranche de QR :
Que faut-il faire des pages de mauvaise qualité ?
J'attire votre attention sur ces points majeurs :
- Avec QualityRisk, RM Tech vous aide à identifier des pages qui semblent de mauvaise qualité. Mais c'est à vous qui connaissez bien le site de confirmer que la page est effectivement de mauvaise qualité.
- La priorité, c'est d'améliorer la page ! Suivez les indications de RM Tech (liste des problèmes de la page) afin de réduire son indice QualityRisk.
- Même si une page est objectivement de mauvaise qualité, elle peut générer un trafic SEO non négligeable. Donc avant toute suppression de page, allez toujours vérifier combien elle génère de trafic SEO. S'il est important, améliorez la page mais ne la supprimez pas ! Pour ça, basez-vous sur les clics d'après Search Console.
- Si une page de mauvaise qualité a reçu des bons backlinks, faites en sorte de toujours en profiter. Le mieux est de conserver la page en améliorant son contenu, et si ce n'est pas possible il faut la rediriger en 301 vers une page similaire. Ne la supprimez pas "brutalement" (code 410 par exemple)...
Consultez les exemples ci-dessous.
Si vous avez déjà bien compris le principe de QualityRisk, vous pouvez déjà passer à la méthode supérieure ! Je parle de ma méthode Pages Zombies SEO, qui aide justement à identifier encore mieux les pages non performantes et à corriger les problèmes associés.
Exemples de pages de mauvaise qualité identifiées par RM Tech
Après la théorie, place à la pratique ! Grâce à l'analyse de milliers d'audits (vive le big data), nous avons rencontré un grand nombre de cas de figure et mis au point notre algorithme QualityRisk afin qu'il réussisse à dénicher toutes sortes de pages bien souvent difficiles à extraire de la masse des pages d'un site. En voici quelques exemples (avec l'autorisation des sites concernés).
Je précise que notre algo QualityRisk se base sur une combinaison de multiples critères, pas seulement sur la taille du contenu. Plus vous accumulez d'éléments déceptifs pour l'internaute, plus vous prenez de risques également pour votre SEO, et plus vous avez un score QR élevé dans votre rapport d'audit RM Tech.
Lisez donc bien tous les exemples ci-dessous ;-)
Pages avec un contenu central totalement vide
On ne s'attend pas à ce que ce genre de page ait un contenu vide, et pourtant ça arrive. Pouvez-vous être certain que vous n'avez aucune page de ce genre sur votre site ? Combien en avez-vous ? RM Tech vous le dirait ;-)

"C'est pas compliqué, il suffit de compter le nombre de mots dans la page. Par exemple celle-ci en a 118 d'après ce que m'indique un crawler SEO." Voilà le genre de remarque que vous pourriez vous faire, mais justement, nous avons vite remarqué que se baser sur le nombre de mots est nettement insuffisant.
Notre algo QualityRisk exploite plusieurs caractéristiques de chaque page pour repérer une éventuelle qualité trop faible. Regardez par exemple la capture d'écran ci-dessous :
Evidemment, avec une page vide comme ça (et une sorte de titre H1 bourré de mots-clés), l'internaute risque de quitter votre site avec une impression de mauvaise qualité. Avec d'autres crawlers SEO, cette page ne sort pas en erreur car on dénombre 679 mots en tout. Mais ceux-si sont surtout présents dans le méga-menu (d'ailleurs largement sur-optimisé) :
Avec QualityRisk, notre outil RM Tech cherche à s'adapter aux différents cas de figure. Par exemple, nous ne traitons pas les sites ecommerce comme les sites de contenus ou de petites annonces.
Pages qui ne devraient pas être indexables
On trouve souvent des pages qui ne devraient pas être indexables (ou même vues par Google). Parfois c'est une toute petite erreur, mais répétée sur un grand nombre d'URL. C'est le cas avec ce site qui laisse Google crawler plein de pages n'ayant ni titre, ni menu, ni aucune navigation, rien qu'un formulaire :
Un autre exemple du même genre, avec cette fois une page (actuellement indexée) qui ne contient qu'une publicité (promotion), sans doute prévue pour s'afficher en pop-up :

Pages au contenu trop faible
Ne croyez pas que seuls les cas extrêmes posent problème (pages vides ou quasi vides), les pages au contenu trop faible sont également identifiées par Google ("thin content"). Par expérience, je peux vous dire qu'on a généralement bien plus de mal à les identifier, surtout quand on a "la tête dans le guidon". Parfois, un regard extérieur suffit à repérer certaines faiblesses, mais la machine est "impitoyable", ne se fatigue pas même s'il faut chercher quelques dizaines de pages parmi des milliers.
Besoin d'idées d'amélioration ? Lisez mon dossier Comment faire un site qui plait aux internautes.
Page de type article éditorial
Voici un exemple de page de contenu qui à première vue semble assez bien :
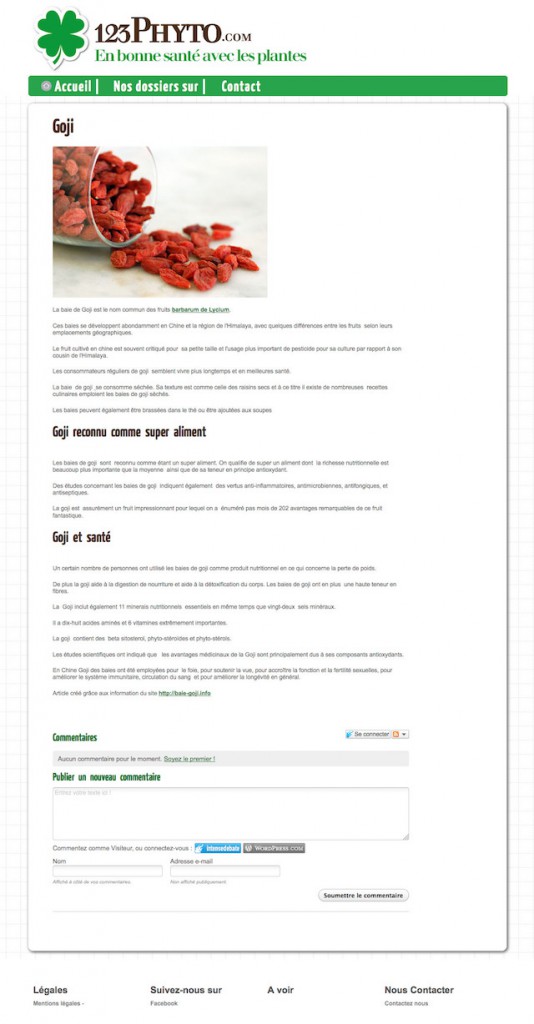
En réalité, la question à vous poser est la suivante : "Est-ce que cette page présente une valeur ajoutée bien supérieure à ce qu'on trouve sur Internet sur ce sujet ?". Si votre site a une forte notoriété, vous pouvez vous permettre de publier un contenu de qualité moyenne. Mais dans le cas contraire, pour sortir du lot et avoir la moindre chance d'être en page 1 de Google, vous devriez publier un contenu "10 fois meilleur" que ce qui existe actuellement.
Je ne suis pas le seul à le conseiller, le très respecté Rand Fishkin recommande de ne publier du contenu que si on pense pouvoir produire quelque chose 10 fois meilleur que ce qui existe. Eric Enge, un autre expert SEO très réputé, conseille la même chose.
La page ci-dessus a été identifiée par QualityRisk comme de trop faible qualité. C'est assez logique au final car :
- le titre n'est pas très explicite ("Goji" uniquement, aussi bien dans la balise title que la balise H1)
- l'article fait 346 mots, ce qui est correct, mais en réalité insuffisant pour ce sujet : on ne fait que survoler ce qu'il y aurait à dire. On ne peut pas toujours faire des articles de 1000 mots me direz-vous, mais si vous restez "basique", pourquoi seriez-vous en première page de Google ?
- si vous lisez bien vous verrez qu'il y a des fautes d'orthographe, des fautes de grammaire, des manques de ponctuation
- on apprend à la fin que cet article est un résumé de ce qu'on trouve sur un autre site : l'internaute aurait sans doute préféré la version originale
Page de type catégorie de produits (ecommerce)
Je poursuis avec un autre exemple, cette fois sur une page catégorie de site ecommerce :
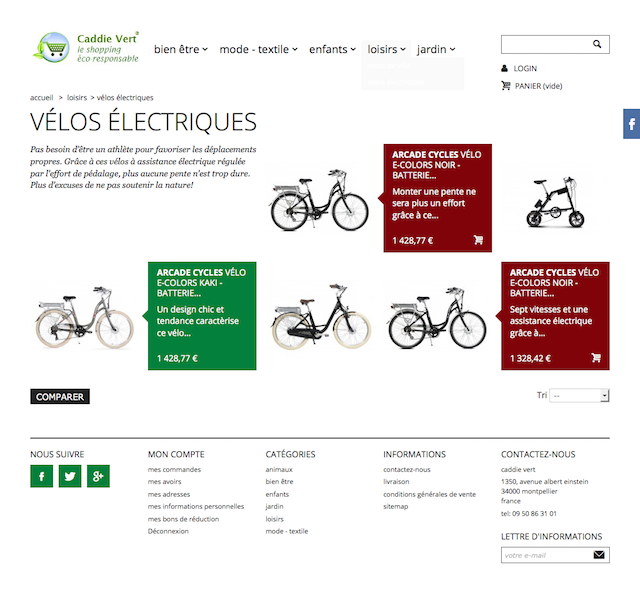
Là aussi, à première vue c'est correct, mais si vous n'avez que des catégories de ce type, vous aurez du mal à sortir du lot. Seulement 5 produits, très peu d'explications, titres tronqués : c'est trop peu ! S'il s'agissait de produits très simples à 3€, ça irait, mais ici il s'agit de produits "avancés" à ~1500€.
Evidemment, c'est plus flagrant sur la catégorie ci-dessous qui n'a aucun produit. Certes, dans cet exemple il s'agit des nouveaux produits, mais RM Tech tente de détecter cela partout sur votre site !
Page de type fiche produit (ecommerce)
Je continue avec un exemple de fiche produit : il s'agit d'une pièce pour un moteur de bateau, vendue ~76€. Voici la page :
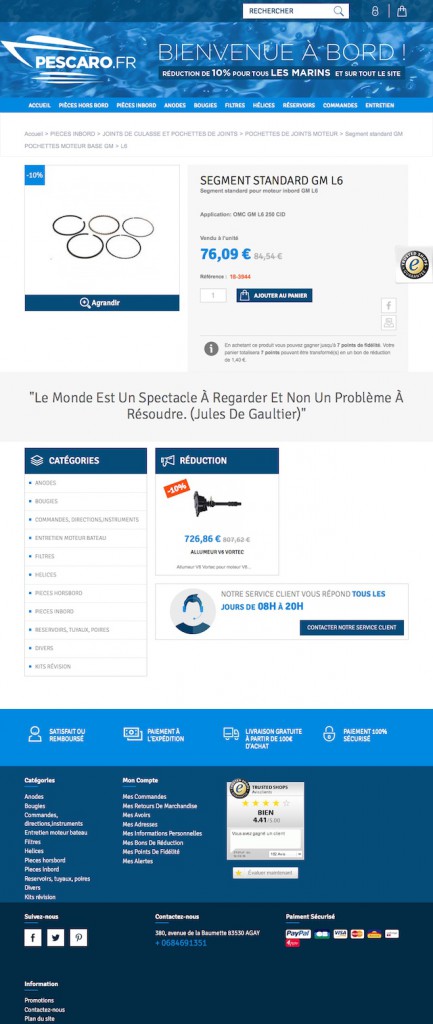
Avec un outil SEO classique de crawl, on apprend que la page contient 765 mots. Autant dire qu'on aura du mal à se rendre compte qu'elle a un contenu bien trop faible ! Surtout quand on a 10.000 pages à étudier comme sur le site pris en exemple...
Pourtant, à part la citation de Jules de Gaultier, il n'y a rien...
Pour ma part, je conseillerais de fournir des explications sur le fonctionnement de ce produit, sa compatibilité avec les différents moteurs, son installation, sa durée de vie, les outils nécessaires pour le montage, etc. Il pourrait y avoir des photos supplémentaires, une vidéo, des avis clients...
Page membre d'un forum
Comme je vous l'ai déjà indiqué, RM Tech sait s'adapter à tous les types de sites. Après les sites de contenus ou les boutiques en ligne, voici un exemple avec un site communautaire :
Grâce à cet audit, celui qui gère le SEO sur ce site réalise tout de suite qu'il n'aurait pas dû faire indexer autant de pages, surtout que le système en place génère plusieurs URL (sans contenu) pour chaque membre...
Pages de qualité insuffisante
Comme je vous le disais plus haut, RM Tech ne cherche pas à identifier uniquement les cas extrêmes. Quand une page accumule trop d'éléments potentiellement décevants pour l'internaute, nous attribuons un score QR élevé.
Page avis clients
Regardez par exemple cette page (j'ai tronqué une partie du contenu qui était répétitif, à savoir des avis clients) :
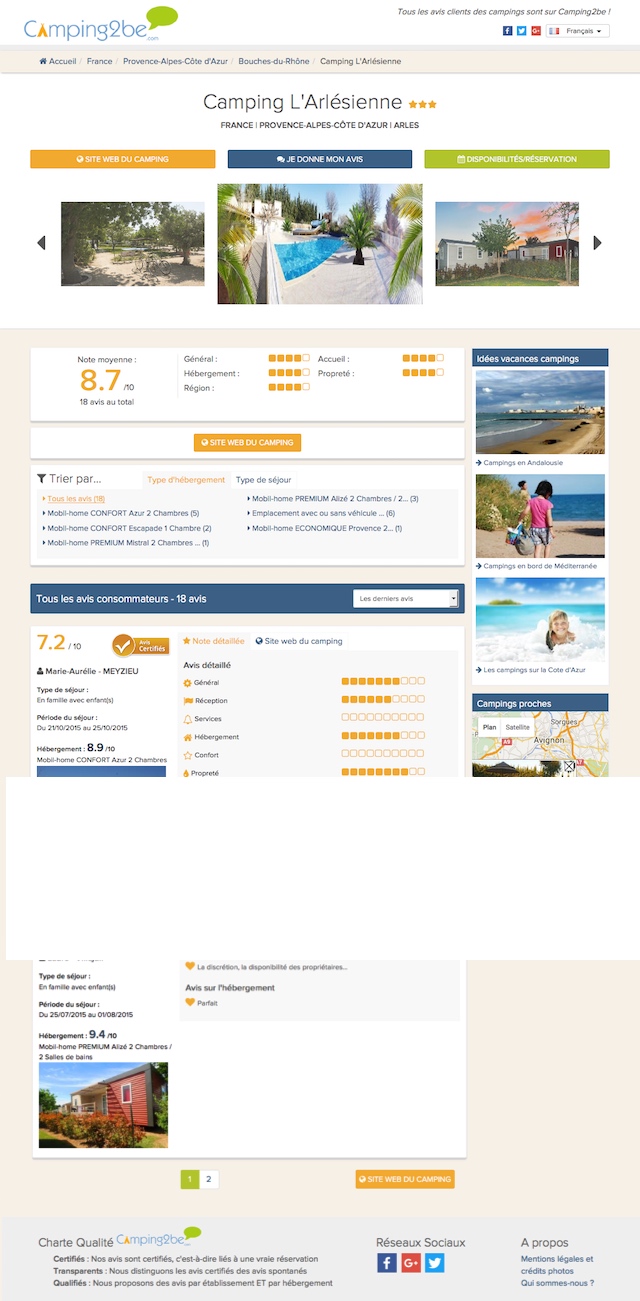
Pourquoi RM Tech indique que cette page n'a pas une qualité suffisante ? Voici quelques pistes de réponse (fournies dans l'annexe du rapport, bien entendu) :
- cette page est trop lente à télécharger (4521 ms) donc sans doute encore plus à charger en entier pour l'internaute
- il y a une balise title mais elle est vide
- idem pour la balise meta description (vide)
- le titre éditorial est bien un H1 mais il indique uniquement "Camping L'Arlésienne" alors qu'il s'agit d'une page qui liste les avis clients de ce camping
Cette page n'est pas dans les plus mauvaises de ce site, mais grâce à QR on peut identifier des pages de qualité moyenne, faciles à améliorer, ce qui fera progresser le référencement.
Page d'accueil
Une page d'accueil ne se travaille pas de la même manière que les autres pages. Généralement elle bénéficie d'une bonne popularité (grâce à des backlinks), donc pour bien en profiter il faut qu'elle fasse des bons liens vers les pages internes, et qu'elle ait beaucoup de contenu (texte).
Voilà un exemple avec une page en espagnol (RM Tech fonctionne sur les sites multilingues) :
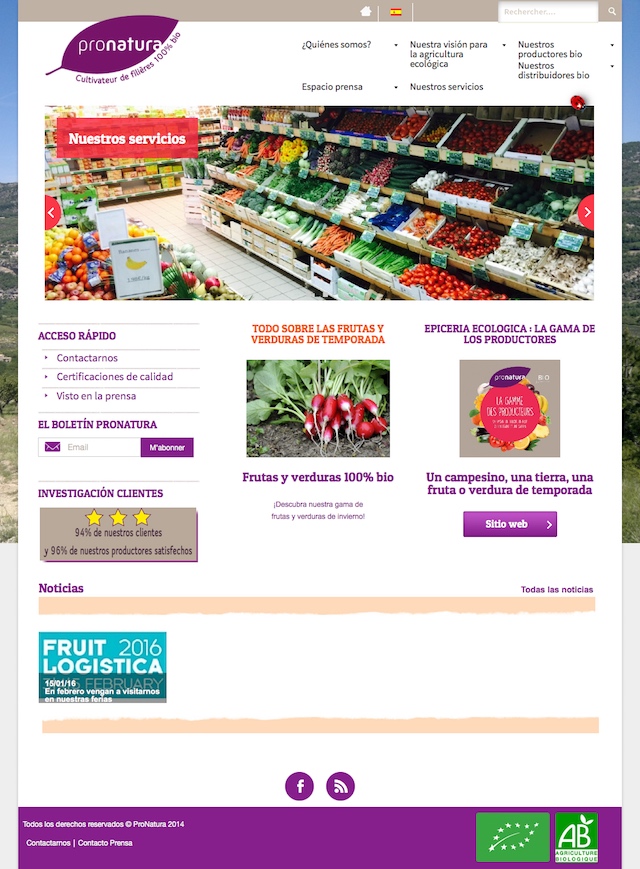
L'algo QualityRisk a identifié que cette page d'accueil n'est pas assez bien faite et qu'en ajoutant du contenu et quelques liens, le référencement du site pourrait progresser.
Conclusion
J'ai essayé de vous convaincre qu'avec l'algorithme actuel de Google, vous ne pouvez plus vous permettre de faire indexer trop de pages de mauvaise qualité. Il faut identifier les pages qui relèvent d'une erreur (contenu vide) mais aussi les pages de trop faible qualité. Plus vous en avez, plus votre score global de qualité se réduit, ce qui pénalise votre SEO Google.
Avec RM Tech, vous pouvez identifier facilement les pages ayant un fort risque d'être évaluées de trop faible qualité. En vous concentrant sur la correction de ces pages, vous pouvez améliorer sensiblement votre référencement.
Bonus : replay du webinar QualityRisk
J'ai présenté un webinar très complet sur ce sujet, et je vous propose de le (re)voir en replay gratuit :-)
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Bonjour Olivier,
est-ce qu'un simple no-index permet d'éviter de les intégrer dans le calcul de scoring de Google ? Ou faut-il les dégager purement et simplement ?
Merci !
Oui, ça permet de les exclure de cette analyse je pense. Mais d'une part elles continueront de consommer du crawl pour rien ou pas grand chose, et d'autre part si elles sont de mauvaise qualité, pourquoi les proposer à l'internaute ? Bref, le noindex ne doit être qu'une solution temporaire avant une amélioration de la page (c'est mieux) ou une suppression totale.
Un peu tard, c'est vrai, ma nouvelle drogue c'est le Quality Risk ! Je veux du 100% pour le visiteur, pour moi, et enfin, et enfin seulement, pour le robot !
RM Tech c'est la base !
Merci pour vos conseils précieux et votre réactivité ! Dans ce tutoriel Comment désindexer, vous indiquez ceci :
"il est possible de supprimer une page via Search Console, et pour éviter qu'elle revienne à l'avenir dans l'index de Google, on la bloque dans le fichier robots.txt. Ce n'est donc pas le fait de la mettre dans le robots.txt qui la désindexe, mais la combinaison "demande de désindexation dans GSC + blocage dans robots.txt".
Est-ce une option insuffisante dans le cas présent ?
En définitive, je ne comprends pas si Google tient compte pour son analyse de qualité, de l'ensemble du site ou seulement des pages indexables?
En effet, s'il y a peu de pages, la solution "demande manuelle individuelle dans GSC" + "blocage dans robots.txt" est suffisante.
Google se base (à mon avis) sur les pages indexables.
Bonjour,
je travaille à la correction d'un site sur la base d'un Audit RM Tech. Le score Quality Risk a entre autres mis en avant les pages dont le contenu était insuffisant. Typiquement, des pages de taxonomie avec peu ou pas de contenu pour un terme donné.
Est-il suffisant de désindexer les pages incriminées dans robots.txt ? Faire en sorte qu'elles ne soient pas générées serait bcp plus long à développer. Et pour certaines pages, il est impossible de les supprimer (contact par ex).
Merci
Le fichier robots.txt ne permet pas de désindexer (sauf si on utilise la directive Noindex: qui n'est ni officielle ni conseillée par Google), il permet d'interdire le crawl, ce qui est différent et insuffisant dans le cas présent.
Si le problème concerne des pages de catégorie, ça serait bien d'automatiser la balise meta robots noindex en l'incluant quand il y a trop peu d'éléments listés dans la page.
Pour apprendre les détails de la désindexation de page, je conseille mon tuto https://www.webrankinfo.com/dossiers/indexation/comment-desindexer
Enfin, ne désindexez pas vos pages de contact ou mentions légales même si elles ont un mauvais score QualityRisk, c'est normal !
Bonjour,
Penses tu qu'une page qui affiche une seule infographie (au milieu d'un blog) a de fortes chances d'être considérée comme une page de mauvaise qualité ?
Merci :)
Si la page n'a que l'infographie sans aucune explication, ça risque d'être insuffisant en effet. S'il y a aussi des explications, c'est sans doute bien mieux.
Sauf si l'infographie est ultra qualitative...
Hello à tous et plus particulièrement à @nicolas et @olivier
Premièrement, merci pour cette article contenant de nombreux points de vue sur ce qu'est une page de qualité.
Je voulais rebondir sur l'exemple de la page de Nicolas qui répond à une question précise : fiche-auto.fr/questions/Duster-3.html
Certes, la page a première vue est de bonne qualité car elle est agréable à lire, et surtout, elle répond simplement et efficacement à une question pouvant être posée par un internaute...
Cependant, dans ce cas, ne faudra-t-il pas chercher à comprendre pourquoi d'autres sites sont mieux positionnés ?
Est-ce suffisant par rapport à ce que proposent d'autres sites sur cette question/thématique ?
J'ai rapidement regardé le premier positionné sur la requête "quelle huile pour duster"
http://pieces-auto.mister-auto.com/huile-moteur-dacia-duster_lg3224_ls8547/
Bien que cette page réponde aussi à la question de l'internaute, elle a surtout le mérite de permettre à celui-ci de continuer sa navigation, et donc de rester sur le site :
Recherche par marque, recherche par immatriculation, liens vers d'autres rubriques...
Je pense qu'une page doit contenir des éléments qui favorisent les interactions avec l'utilisateur (formulaires, outils de recherche, liens connexes), ou tout simplement l'internaute à rester plus longtemps sur la page : contenu long, riche, rassurant ...
C'est surement ce qu'on appelle "l'expérience utilisateur". La capacité à une page web ou à un site :
- de retenir l'utilisateur le plus longtemps possible.
- de multiplier les interactions (clics, navigation, recherche).
- d'inciter l'internaute à revenir.
Bonjour,
Quand vous dites "supprimez-les", peut-on ajouter une meta noindex ou bien doit-on la supprimer réellement ?
ça dépend des cas David ! si possible il faut sauver la page pour l'améliorer plus tard... Je détaille tout ça gratuitement dans mon webinar, inscrivez-vous pour le replay !
Bonjour,
un grand Merci pour l'étude complète et approfondie RM Tech pour mon site.
C'est une mine d'or!
Il ne me reste plus qu'à l'exploiter.
Grace à la mise en application de vos conseils lors d'une de vos formations SEO le site Pescaro.fr a énormément progressé et je suis aujourd'hui un peu débordée par sa gestion au quotidien! (CA x3)
Mais c'est le but.
Merci Fabien et Merci Olivier pour tous vos conseils et vos outils pertinents et performants.
Une chose me surprend quand même dans cet article très riche et fort intéressant. IL faut des pages avec un fort contenu. Mais n'est-ce pas trop que d'en mettre des tartines sur une seule page ? N'oublions pas que les sites doivent surtout pouvoir être lu sur un smartphone. Or pour que le lecteur ne soit pas dégoûté par une information trop dense et garder une certaine homogénéité, il convient au contraire je trouve de ne pas trop en mettre et d'aérer le contenu.
Je ne dis pas qu'il faut des pages avec un fort contenu mais avec un contenu de qualité. C'est assez subjectif et difficile à évaluer !
Attention : dans QualityRisk, la taille du contenu n'est qu'un des critères.
@eskimo, la solution préconisée est un cas particulier qui n'arrive pas forcément. Pour de l'actualité, je tombe sur un article, est ce que je vais rester 10 minutes à le lire puis repartir, éventuellement cliquer sur un autre résultat de Google, ou est ce que j'ai une popup infermable et au bout de 2 secondes je suis allé chez le concurrent ?
Le taux de rebond ajusté permet de mesurer les cas d'aller/retour rapide.
Olivier à plusieurs reprises tu indiques qu'il est impossible de mesurer le taux de retour en arrière dans les SERP
"Si je savais mesurer le taux de retour en arrière dans les SERP, ça serait pratique. Mais il faudrait hacker Google pour ça ;-)"
en fait on peut se faire une idée assez grossière à partir du moment où l'on dispose du chemin par utilisateur.
ex :
page 1 > page 10 > page 5 > page 8 > page 5 > page 10 > page 1
A partir de la page 5 le temps de consultation est de 1 seconde.
C'est clairement un cas de pogosticking avec retour sur Google.
Piwik enregistre ces données... on peut également coder facilement l'enregistrement des chemins utilisateurs soit même.
A partir de ce moment là on peut faire un calcul à partir des logs genre :
SI URL dernière page = url première page ALORS vérifier la symétrie
et si le temps de consultation des 3 dernières pages( pour le cas cité plus haut) est > 2 secondes alors grande probabilité de pogosticking avec retour sur google.
Après on ne peut pas calculer le cas "recherche google > page du site > retour page recherche google" mais le cas "page 1 > page 10 > page 5 > page 8 > page 5 > page 10 > page 1" arrive très souvent et permet de commencer à ce faire une idée.
@eskimo : en effet, on peut trouver des moyens pour affiner l'analyse et identifier des problèmes, même si ça ne correspond pas réellement au retour dans les SERP.
Tu indiques " > 2 secondes" mais tu voulais dire "< 2 secondes" je suppose ? PS : tu parles de Piwik, mais GA le permet également non ?
bonjour
je me suis précipité pour obtenir un audit gratuit, et je suis très heureux d'avoir pu en bénéficier. Contenu trop faible, méta description trop courte : j'ai déjà fait du ménage : un grand merci à Olivier.
Je suis perplexe en revanche face à l'erreur "301". Je fais, dans le .htaccess, une redirection des pages www. vers les adresses "sans www." et c'est jugé comme étant une mauvaise pratique. Ma question est probablement naïve, mais je la pose quand même : je dois faire quoi ?
merci de votre retour
cordialement
Hubert
@Hubert : quand on modifie l'URL d'une page (j'appelle ça "casser"), il faut en effet mettre en place une redirection 301 de l'ancienne URL vers la nouvelle. Mais il faut aussi modifier tous les liens qui pointent encore vers l'ancienne URL afin qu'ils pointent directement vers la nouvelle.
Justement, RM Tech détecte les liens internes qui ne pointent pas directement au bon endroit. Le rapport aide dans les détails en fournissant l'ensemble des pages faisant des liens vers des pages qui se font rediriger.
Bonjour,
Cet exposé est plus qu'explicite, il montre bien que l'Internet de qualité n'est pas pour demain. C'est malheureux à dire, mais je suis soulagé de constater qu'il y a du pain sur la planche, moi qui démarre mon activité de SEO cela m'encourage.
Merci à toute l'équipe Ranking Metrics
Vouloir cibler trop de requêtes différentes (donc pas similaires!) avec la même page va forcément avoir un impact sur l'expérience utilisateur. Sur mobile il va devoir scroller pour chercher la réponse à sa question. Suivant le type de pages, le public ... Chaque stratégie peut être intéressante. Autres pointsqu'un algorithmes ne peut pas mesurer :
- l'efficacité d'un moteur de recherche interne. Sur mobile la encore c'est crucial.
- les interstitiels (pub ou abonnement newsletter) qui peuvent faire fuir l'internaute sans même regarder le contenu, le pire scénario.
@Fabien : j'aurai du m'abstenir de donner cet exemple mais soit allons jusqu'au bout.
D'abord les 2 exemples donnés :
Page oscaro : il faut combien de clics et de navigation pour arriver finalement à la réponse ? 2 pages et 3 champs de formulaire.
Sur mobile avec une connexion 3G standard, on oublie.
Page carbon cleaning (qui cible les logan...) : on m'explique à quoi sert l'huile, les différentes normes, la viscosité, ca y est je suis expert en huile !
Mais désolé la réponse est "perdue" au milieu de blah blah inutile pour cette requête. Bien sur si je cherche à savoir ce qu'est une vidange, la différence entre une révision et une vidange, la viscosité, c'est autre chose (j'ai d'ailleurs d'autres sites qui répondent à ces questions).
De mon coté j'ai créé un visuel avec les différents bidons d'huile correspondant, pour rassurer l'internaute et le guider si il est déjà dans le magasin, et je lui apporte l'information directement : quelle huile utilise Dacia pour le Duster ? Le tout avec un affichage rapide, l'information au dessus de la ligne de flottaison même sur smartphone.
Aujourd'hui si je cible une requête large, je vais essayer de répondre à toutes les questions possibles (avec des liens, visuels...) Mais si je cible une requête hyper spécifique, je vais répondre directement. Plus de blah blah, plus de taille de texte minimale. Si je cherche l'age de Brad Pitt, je veux juste une page qui contienne en gros 52 ans et sa date de naissance (tiens tiens c'est ce qu'affiche Google dans son answerbox).
Certes Nicolas, mais tu conseilles de faire une page de ce genre par requête ? Une autre stratégie est de viser davantage de requêtes avec davantage de contenu par page.
Ou bien faire un peu des 2 ;-)
Bonjour à tous,
Pour répondre à @nicolas je ne trouve pas la page http://www.fiche-auto.fr/questions/Duster-3.html assez bonne qualité perso.
A la limite je préfère globalement cette page http://www.carbon-cleaning.com/huile-moteur/diesel/dacia/logan-dci-75-75ch
il manque aussi des liens internes comme sur cette page https://constructeurs-auto.oscaro.com/huile-accessoires-vidange-dacia-duster-702548-155-scf
il faut toujours regarder la requete et la première page pour améliorer ta page et ajouter des infos sur celle-ci.
Sans hacker Google, certains plugins Chrome pourraient très bien être développés/utilisés pour remonter ce genre d'infos, comme la barre Alexa à l'époque ou les MozBar, ...
Reste le problème de faire installer cette barre par le plus grand nombre, donc apporter une réelle plus value.
En effet Nicolas, il est possible de recueillir certaines infos, mais pour être exploitables il faut atteindre une taille énorme
Bonjour Olivier,
Même si je suis d'accord avec les bons conseils donnés et je pense que l'outil développé peut être utile dans beaucoup de cas, certains points peuvent induire en erreur.
Après la sortie de Panda, les référenceurs ont fait une analyse (trop) rapide des critères pouvant pénaliser un site, et on a beaucoup entendu parler de low quality content, thin content, ... Tout le monde s'est précipité en pensant que le Saint Graal serait le contenu de plus de xxx mots. (moi le premier! j'ai perdu 2 ans d'optimisation).
Au contraire et l'idée que Glenn Gabe et d'autres essaient de populariser est la notion d'expérience utilisateur, et elle ne se compte pas en mots, ni n'est calculable ! Olivier, tu en as déjà d'ailleurs longuement parlé dans tes articles. Panda était/est basé principalement sur la notion d'expérience, de satisfaction : est ce que pour une requête donnée, ce site répond le mieux à la demande ? Je reste persuadé qu'il n'y avait aucune analyse de page, juste une énorme base de données collectant les informations suivantes : pour une requête donnée, pour une position donnée, quels sont le CTRs, le poggosticking, et est ce que l'internaute a cliqué sur un autre résultat. Ils ont ensuite fait varier les résultats dans le temps, sur une heure, une journée, une semaine... Et ces données permettaient de sanctionner les sites qui étaient "trop bien positionnés" par rapport à la satisfaction des internautes.
Les searchbox de Google prouve bien d'ailleurs le raisonnement : si la réponse est "trop" simple, Google l'affiche directement.
Un exemple de contenu court qui répond parfaitement à une requête : fiche-auto.fr/questions/Duster-3.html
Cette page va se positionner car très peu de pages répondent aussi simplement et directement à la question. On trouve la même information dans un PDF de plusieurs Mo et dizaines de pages, sur des posts de forums avec des dizaines de réponse ... Et à mon avis cette page sortira avec un mauvais QualityRisk, au contraire des pages concurrentes.
A mon avis il faut surtout réfléchir à imaginer le contenu idéal ET l'interface idéale (moteur de recherche avancé, rapide...), qui est surement plus complet pour des requêtes larges que des requêtes très spécifiques.
@Nicolas : je suis tout à fait d'accord avec toi sur le fait qu'il ne faut pas résumer qualité de page à nombre de mots. D'ailleurs, le nombre de mots n'est qu'un des critères de notre algo ;-) Par ailleurs, je précise très clairement (surtout dans le rapport d'audit RM Tech) que cette analyse n'est que le début d'un audit qualité : QualityRisk est là pour faire gagner un temps fou pour repérer plein de choses qui ne devraient pas être indexables, ou en tout cas pas avec ce niveau de qualité. Je dis très clairement qu'il faut compléter ça par d'autres analyses.
Si je savais mesurer le taux de retour en arrière dans les SERP, ça serait pratique. Mais il faudrait hacker Google pour ça ;-)
Tu penses à quels autres critères mesurables ?
PS : dans ton exemple, la page ne sort qu'en page 2 pour la requête exacte (le libellé de son H1), ce n'est pas si flagrant. Et peut-être qu'elle pourrait être améliorée, y compris pour l'internaute, et qu'elle remonterait dans les SERP.
Bravo, sincèrement, quel outil fantastique !
Merci de votre réponse Olivier ;) De ce fait je suppose qu'il vaut mieux les passer en No Index... Cela ne représente aucun intérêt de les laisser indexées.
Merci pour cet article Olivier ! Toujours un plaisir de vous lire :)
Pour ma part j'aurais aussi ajouté les sous-pages d'archives du genre /page/2/ que l'on peut trouver dans la navigation de WordPress (par exemple).
Font-elles aussi partie de ce que l'on appelle des pages de basses qualités ?
Merci @Alexandre : je pense que les pages de la pagination (pages 2 et suivantes) sont plutôt à ranger dans le "inefficace en SEO" mais moins dans le "de mauvaise qualité (pour l'internaute)". Cela dit, on en tient compte aussi d'une certaine façon dans notre algo.