
Article mis à jour le 23/08/2014, publié initialement le 22/03/2010
Sommaire :
- Définition du DC
- Les bases du DC
- Le brevet de Google
- Algorithmes
- Outils
- FAQ sur le filtre DC
- Eviter le filtre DC
Définition du contenu dupliqué

On parle de contenu dupliqué dès lors qu'un même contenu (indexable par les moteurs) est trouvable à plusieurs endroits sur le web. L'adresse de ces contenus étant l'URL, on parle de contenu dupliqué dès lors qu'un même contenu est accessible à plusieurs URL.
Précision : tout compte dans l'URL, même ce qui suit le point d'interrogation ? et même l'ordre des paramètres. La seule exception concerne le signe # : tout ce qui suit le signe # est exclu. En effet ce qui est derrière le # est considéré comme un fragment, c'est-à-dire le nom d'une ancre interne de la page. On l'utilise normalement pour pointer à un endroit précis d'une page. Si besoin, consultez mon guide du vocabulaire des URL pour le référencement.
La définition officielle de Google est la suivante (source) :
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar
En gros, Google considère qu'il s'agit de blocs "substantiels" de contenus qui sont soit strictement identiques soit sensiblement similaires à des contenus situés sur le même (nom de) domaine ou sur d'autres domaines.
En savoir plus sur les bases du contenu dupliqué
Si vous souhaitez mieux comprendre dans les détails pourquoi le duplicate content pose problème (à la fois aux moteurs et aux webmasters), je vous encourage à lire mon premier dossier sur le duplicate content. Vous y apprendrez notamment quelles sont les causes les plus répandues et quelles sont les solutions.
Pour ceux qui souhaitent des explications plus détaillées et des réponses personnalisées en fonction de leur cas, je vous propose d'assister à mes formations Ranking Metrics, on parle en détails de l'importance des contenus dupliqués dans le référencement.
Pour ceux qui ont déjà lu mon précédent dossier, je vous propose d'aller plus loin. Dans la suite de ce dossier, je considère donc que vous avez corrigé toutes les erreurs classiques de contenus dupliqués (en général internes mais pas seulement).
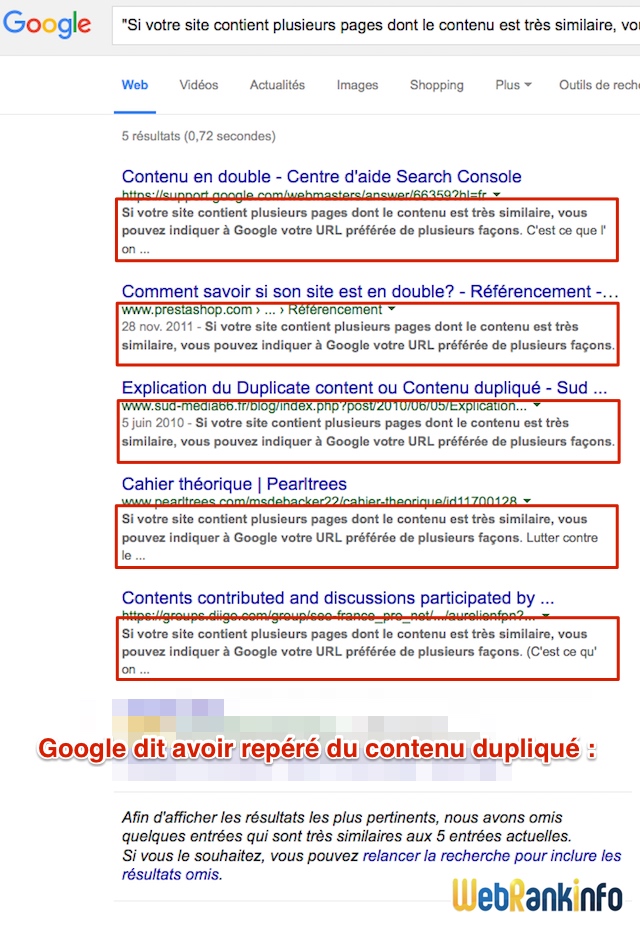
Un petit exemple de SERP avec plein de contenus dupliqués, juste pour la route :
Le brevet de Google sur la détection de contenus dupliqués
Google a obtenu un brevet intitulé "Duplicate document detection in a web crawler system". En voici un très court résumé (source) :
- Inventeurs : Daniel Dulitz, Alexandre A. Verstak, Sanjay Ghemawat, Jeffrey A. Dean
- Brevet numéro 7,627,613 déposé le 3 juillet 2003 et attribué le 1er décembre 2009.
Ce brevet introduit le concept du DupServer, un serveur dédié à l'analyse du contenu dupliqué.
Quand le crawler récupère une page web, il demande au DupServer de vérifier si son contenu n'est pas déjà connu. Dans ce cas, le système décide quelle page doit être considérée comme la version canonique (celle qui sera conservée).
Pour détecter les contenus dupliqués, le système calcule des empreintes pour chaque document (fingerprints). Pour des raisons de performance, il les enregistre de manière compressée dans une base de données. Un algorithme permet de comparer deux documents en comparant simplement les empreintes.
D'après le brevet, cette analyse comparative est effectuée de façon indépendante des requêtes. Autrement dit, si le système estime qu'une page B est un doublon d'une page A, la page B risque d'être filtrée dans les résultats quelle que soit la requête.
Algorithmes de détection de contenu dupliqué
La détection des contenus dupliqués dans la littérature
Pour en savoir un peu plus sur les traitements imaginés par les ingénieurs de Google, il faut lire les articles publiés par ces chercheurs. J'ai par exemple lu la description de SimHash ("SimHash: Hash-based Similarity Detection" à lire ici au format PDF).
J'ai également étudié l'article de la célèbre Monika Henzinger (de Google) publié en 2006 en collaboration avec l'Ecole Fédérale de Lausanne : "Finding Near-Duplicate Web Pages: A Large-Scale Evaluation of Algorithms" disponible ici au format PDF. Elle détaille sa comparaison des performances de plusieurs algorithmes dans le cas d'une grosse base de documents (1,6 milliard).
Pour ceux qui veulent aller plus loin, je vous ai déniché le meilleur article : il fournit une comparaison quasi exhaustive des algorithmes de détection de contenus dupliqués (assez récent puisqu'il date de 2009). Il s'agit de l'article "Duplicate and Near Duplicate Documents Detection: A Review" de J. Prasanna Kumar et P. Govindarajulu.
Un algorithme de Google de détection des contenus presque dupliqués
J'ai sélectionné un de ces articles pour vous le détailler ici. Il s'agit d'un article publié par 2 chercheurs de Google et un chercheur de l'université de Stanford (ce dernier ayant également travaillé pour Google). Il est intitulé "Detecting Near-Duplicates for Web Crawling" (à lire ici au format PDF) et fut publié en Mai 2007 par Gurmeet Singh Manku (Google), Arvind Jain (Google) et Anish Das Sarma (Université de Stanford et Google).
Présentation
L'article consiste en une présentation d'algorithmes compatibles avec la recherche de contenus dupliqués sur une base de centaines de millions de documents (ou plus). L'objectif est précisément de détecter les contenus trop similaires (near duplicate content) afin d'exclure les pages concernées et de ne pas tenir compte des liens sortants situés sur ces pages (!). En pratique les pages considérées comme des contenus dupliqués ne sont pas forcément exclues (cela dépend d'autres critères) mais elles sont en quelque sorte pénalisées puisque leur positionnement dans Google risque de se dégrader. En outre, Google diminuera sa fréquence de crawl sur ces pages.
La signature des documents (empreinte)
L'algorithme SimHash de Moses Charikar (publié dès 2002 sous l'intitulé "Similarity estimation techniques from rounding algorithms") semble approprié aux chercheurs de Google pour le cas qui les intéresse. Ils ont par exemple vérifié pour une base de 8 milliards de documents, les empreintes SimHash stockées sur 64 bits diffèrent seulement de 3 bits.
Pour que l'algorithme de détection de contenus dupliqués soit efficace, il faut en effet que les signatures de documents (empreintes) diffèrent de seulement quelques positions (bits). Les chercheurs présentent différents algorithmes pour résoudre le problème de la distance de Hamming.
Le calcul d'empreintes de SimHash :
- pour chaque page web on liste des caractéristiques, chacun se voyant attribuer un poids (pondération)
- ces caractéristiques sont déterminées avec des algorithmes classiques de recherche d'information : découpage en formes individuelles (mots) (tokenization), uniformisation de la casse (case folding), suppression de mots vides, regroupement de mots sémantiquement proches en fonction de leur ressemblance graphique (stemming auquel il faudrait sans doute rajouter la lemmatisation) et détection de phrases.
- le regroupement de toutes ces caractéristiques forme un vecteur de grande dimension
- malgré cette grande dimension, SimHash permet de construire une signature sur un nombre réduit de bits (par exemple 64)
Entre 2004 et 2005, Monika Henzinger (ingénieur chez Google) a comparé SimHash avec l'algorithme de Broder ("Syntactic clustering of the web"). SimHash a été retenu en raison de sa capacité à stocker les empreintes sur un faible nombre de bits. A la différence des algorithmes classiques de hashage (SHA-1 ou MD5), les empreintes SimHash de 2 documents similaires seront elles-mêmes similaires. Les algorithmes exploitant SimHash doivent donc en tenir compte.
Le problème de la distance de Hamming
L'objectif est de déterminer si un nouveau document est similaire à d'autres documents déjà analysés. Pour cela on cherche ceux dont l'empreinte diffère de celle du nouveau document de k bits au maximum (k=3 par exemple). En résumé, la solution retenue par les chercheurs est de précalculer des tables qui facilitent les comparaisons d'empreintes.
Concrètement chez Google, le système utilise le framework MapReduce sur une infrastructure GFS (c'est le système de fichiers maison de Google).
Conclusion sur ces articles
Aussi intéressants soient-ils, ces articles ne nous fournissent malheureusement pas vraiment d'explications précises sur la façon de détecter les contenus dupliqués. On se rend bien compte des éléments que les ingénieurs sont susceptibles d'analyser ainsi que les conséquences que cela peut avoir en termes de visibilité dans Google.
C'est pourquoi pour aller plus loin, seuls des retours d'expérience peuvent nous aider... Juste avant cela, passons en revue quelques outils.
Outils de détection du contenu dupliqué
Voici quelques uns des outils disponibles en ligne pour détecter les contenus dupliqués (et les plagiats).
Copyscape
Version gratuite limitée à 10 résultats par recherche (et nb de recherches limité). La version premium offre plus de fonctionnalités de recherche. Elle inclut également une API.
Plagiarism Checker de QuillBot
Outil très simple qui affiche les résultats d'une recherche Google d'un texte
quillbot.com/plagiarism-checker
Calcul de similarité
Calcule la similarité entre deux pages (comme mon outil basique disponible depuis des années sur WRI).
Questions-réponses sur le Duplicate Content
Pour aller un cran plus loin dans l'analyse du filtre DC de Google, j'ai pris l'initiative de contacter quelques membres de WebRankInfo qui s'étaient déjà exprimés plusieurs fois sur la question en fournissant des conseils issus de leur expérience. Je leur ai posé les mêmes questions et vous fournis ici leurs réponses, accompagnées de mon humble avis. Je les remercie donc d'avoir pris un peu de leur temps et surtout d'avoir partagé leurs connaissances avec la communauté WRI. Voici ces contributeurs, classés par ordre d'ancienneté sur le site :
- Sylvain alias sr
- Blman qui aborde le duplicate content sous l'angle des boutiques en ligne
- Patrick alias ybet, très apprécié sur WRI pour le partage de ses nombreux tests de l'algorithme de Google
- Denis alias HawkEye
- L.Jee
J'ai ajouté mon point de vue sous le nom "Olivier" (les 5 intervenants n'avaient pas eu accès à mon point de vue pour répondre). Voici donc la FAQ sur le filtre Contenus Dupliqués de Google :
Définition du Duplicate Content
Comment faut-il définir le contenu dupliqué ?
- Sylvain : Reprise partielle ou totale d'un texte sur une autre page.
- Blman : A mon avis, il s'agit d'un filtre pour améliorer la qualité des résultats de Google. Autant proposer des infos différentes ou complémentaires à une même recherche. En effet, d'un point de vue "internaute lambda" qui recherche une info, ça ne sert à rien de toujours tomber sur la même info; si je clique sur plusieurs liens, ça veut dire que la 1ère info ne m'a pas suffit, alors, autant m'en proposer une différente.
- Patrick : En règle générale, toute suite de mots que l'on retrouve sur d'autres sites. Le nombre n'a pas réellement d'importance, ça peut être un chapitre, un paragraphe, une phrase ou même quelques mots couplés ensemble. Ce qui est le plus problématique est ... les quelques mots puisque c'est souvent involontaire. Dans ce cas, des suites sont prises comme dupliquées, d'autres non sans qu'on sache réellement pourquoi.
En règle plus spécifique, Google détecte également les inversions d'objets, une partie des synonymes (restaurant est par exemple assimilé à restaurateur). "Copier" du contenu nécessite une refonte complète du texte. En plus, lorsque sur des contenus longs, un paragraphe est dupliqué, Google oublie la suite dans le référencement. Ca pose parfois des surprises puisque des pages passent mieux sur certaines requêtes avec du contenu dupliqué dedans (un genre de concentration de mots) mais pas de visiteurs sur le reste. - Denis : reproduction d'une portion significative de contenu sur plusieurs pages.
- L. Jee : Le contenu dupliqué, pour ce qui nous intéresse ici, n'est autre qu'un contenu allant de quelques mots (5 ou 6) à tout un texte qui se trouve sur différentes pages web aussi bien en interne qu'en externe.
- Olivier : un contenu est dit dupliqué dès lors qu'une partie substantielle est déjà indexée sur une ou plusieurs autres pages web.
Pénalité ou filtre ?
Inutile de polémiquer sur les termes ! Voici une bonne explication de Denis issue du forum :
Le filtre est un effet algorithmique découlant de différents facteurs qui sont annoncés ou non (à présent, le Duplicate Content est clairement annoncé comme étant un facteur risque). Exemple : la SandBox...
La pénalité est la conséquence d'une décision, qui peut découler d'une analyse (humaine) déclenchée par un certain nombre de critères (ie: voisinage, risque link spam (cf. actualité récente), etc.). Exemple : la Black List. Depuis 2013, Google révèle au webmaster la liste des pénalités manuelles qui lui sont éventuellement infligées, via Google Search Console.
NB: Comme le précise L.Jee, "pénalité" ou "filtre" : le résultat est le même dans le cas du duplicate content...
Les dégâts occasionnés par le Duplicate Content
Quand le référencement d'un site est dégradé par Google à cause du contenu dupliqué, comment cela se traduit-il (baisse de positionnement, crawl ralenti, désindexation partielle ou totale, autres) ?
Note : pour éviter de polémiquer sur le vocabulaire, j'ai utilisé autre chose que "filtré" et "pénalisé" (cf. remarque précédente).
- Sylvain : Mes constats : Baisse de positionnement ou désindexation totale des pages dupliquées si le site "copieur" a une meilleure autorité.
- Blman : Pour ma part, lorsque j'ai refondu le site e-commerce dont je m'occupe, j'avais fait très attention à ne pas dupliquer les URL pour un même contenu en définissant un format d'URL pour chaque type de page (page catégorie, page marque, page article, ...) dès le cahier des charges. Pour moi, les erreurs classiques de contenu dupliqué interne sont dûes à une mauvaise définition des formats d'URL. Mon architecture interne de pages a donc été pensée dès le cahier des charges pour limiter et éviter toute erreur qui pourrait engendrer un tel filtre.
- Patrick : Toutes les solutions sont possibles. La page peut descendre d'un coup sec de la première place à la cinq centième, descendre de quelques places. Difficile à dire si le site entier est déclassé ou uniquement les pages. Google semble tout simplement ne plus tenir compte de la page ce qui réduit les pages qui reçoivent les liens . En gros ca dépend probablement de la structure du site mais quelques pages dupliquées (et clairement pénalisées) ne semblent pas casser les autres pages pour leur positionnement.
Par contre ces pages font souvent du yoyo dans le positionnement montent dans les premières places, redescendent de quelques places, plongent puis remontent en quelques jours. - Denis : chute de trafic organique en provenance de Google, de l'ordre de 90%
- L. Jee : Cela se traduit par une baisse de positionnement et une chute du trafic moteur d'environ 95%, un peu comme l'effet d'une sandbox (pour ceux qui connaissent). En gros, inutile d'espérer tirer quelque chose de Google dans cette position. J'ai aussi constaté que le crawl était ralenti. Niveau positionnement, le site disparait même sur son nom.
- Olivier : tant que le filtre ne détecte pas les contenus dupliqués, il ne se passe rien. Dans le cas contraire, la chute de positionnement est violente et se traduit par une baisse d'environ 90% du trafic organique assortie d'une forte diminution de la fréquence de crawl des pages concernées.
Quand un site en est victime, ou une partie d'un site, toutes les pages sont-elles concernées ou bien seulement celles qui ont été précisément identifiées par Google comme étant en DC ? Comment savoir à coup sûr si une page est victime de DC ? Cela dépend-il de la requête ?
- Sylvain : J'ai la sensation (quelques constats qui n'ont pas valeur de tests) que plus la requête est longue (nombre de mots), plus le filtre agit. A titre d'exemple, pour le site axe-net.fr, le premier paragraphe de la page d'index est dupliqué sur plus de 300 sites. Sur une requête comprenant le paragraphe entier (sans guillemet), seuls 3 sites sont toujours présents dans la SERP (1ère page), les autres ont disparu sur Google. En contrepartie, un des disparus de Google est par exemple devant moi sur Yahoo.fr. J'ai pris l'exemple de ce paragraphe, car c'est le plus flagrant, mais je note surtout que je ne trouve aucun des sites qui m'ont dupliqué sur les requêtes concurrentielles que je vise.
- Blman : Malgré tous les soins décrits dans ma réponse précédente, je fais beaucoup de contenu dupliqué au niveau du contenu réel du site :Le contenu dupliqué externe : nos fournisseurs nous fournissent des fichiers d'intégration (ou masques d'intégration). Un fichier d'intégration, c'est un fichier (format CSV ou XML) qui reprend tout le catalogue d'un fournisseur. Il contient généralement plusieurs champs : marque, désignation, descriptif, caractéristiques techniques, poids, prix public, photos, ... Moi et une dizaine de concurrents utilisons tous ces fichiers pour remplir nos catalogues, ce qui fait que nous avons tous des milliers de pages en contenu dupliqué. De plus, on envoie tous nos contenus (déjà identiques) aux comparateur de prix, aux plate-formes d'affiliation, ... Donc, nos contenus déjà dupliqués, se retrouvent à nouveau dupliqués par toutes les plate-formes qui reprennent nos catalogues. Pour ma part, sans avoir poussé les tests à l'extrème, il me semble que je ne sois pas filtré. Depuis que j'utilise ce système (des masques ou fichiers d'intégration), je n'ai pas constaté de perte de traffic provenant de Google, bien au contraire. De plus, quand je teste mes requêtes sur ces catalogue là, il me semble que je ressors plutôt bien (pas de perte de positionnement). Et la partie indexation se passe plutôt bien aussi.Le contenu dupliqué interne : puisque je vend des guitares, il y a des déclinaisons du même modèle en option de main (droitier, gaucher) et de couleurs. Sur le site dont je m'occupe, l'architecture est déclinée ainsi : 1 option = 1 page. Ce qui fait que pour 1 modèle de guitare, je peux avoir une dizaine de pages identiques. Là encore, au niveau du positionnement, je n'ai pas constaté de filtre (j'ai toujours au moins 1 page qui ressort correctement). Au niveau de l'indexation, elles sont correctement indexées.Donc, en conclusion, même si j'ai pensé mon architecture pour éviter le contenu dupliqué, j'ai tout de même des milliers de pages produit qui sont en contenu dupliqué et visiblement, je ne suis pas filtré.
- Patrick : A mon avis, seulement la page dupliquée tant que le nombre de pages n'est pas trop important.
- Denis : tout le sous-domaine semble affecté
- L. Jee : Alors là, il n'y a pas l'air d'y avoir de règles clairement définies. D'après ce que j'ai pu voir durant les deux années qui viennent de s'écouler, le filtre réagira différemment suivant les sites. Il apparait qu'un site dit de confiance passera au travers, prenant la paternité du contenu, même si le texte a été publié et indexé ailleurs avant qu'il arrive sur celui-ci, un des plus gros défauts de ce filtre à mon goût. Cependant, Google ne va pas toujours donner la paternité aux plus gros sites et dans ce cas, ce gros site verra sa page ignorée dans les résultats. Il arrive parfois de constater qu'une page ne s'indexe pas à cause du duplicate content ou qu'elle est désindexée. Je n'ai pas poussé la question sur ce point et ne peut en dire plus.Pour ce qui est de la détection, j'ai plusieurs méthodes. Tout d'abord répertorier les pages qui utilisent ce texte dupliqué. Imaginons demain que vous vous fassiez copier le texte d'une de vos pages. Le plus simple est que vous sélectionniez une phrase d'une centaine de caractères et que vous effectuiez une recherche sur Google en ajoutant des guillemets aux extrémités. Vous verrez ainsi qui ressort sur cette phrase et qui est ignoré et placé dans le filtre. Réitérez la manipulation pour plusieurs phrases. Si vous ne ressortez jamais, il y a de grandes chances pour que votre page soit dans le filtre et donc ignorée. Ensuite, afin de s'assurer que celle-ci est bien ignorée, recherchez sur Google avec la requête qui était visée. Votre site sort-il dans les 30 premiers ? Si non, un site "copieur" sort-il à votre place ? Si oui, vous avez votre réponse, vous êtes ignoré, le copieur est à votre place !
- Olivier : dans le cas des gros sites, le filtre est capable de distinguer le groupe de pages qui sont globalement en DC, si bien que c'est tout le groupe qui est touché. Cela peut être un sous-domaine, un répertoire ou même un groupe de pages similaires. Pour savoir si une page est victime du filtre c'est très simple, son trafic Google organique a chuté brutalement de plusieurs dizaines de pourcent ! L'autre solution est de faire des requêtes sur des bouts de phrases en ajoutant les guillemets, comme indiqué précédemment.
Comment savoir si le DC est interne ou externe ?
- Sylvain : En fait, je t'avoue ne pas trop me préoccuper du DC interne. Je sais que beaucoup ne sont pas de mon avis, mais globalement, je trouve que Google le gère très bien de manière automatisée. Bien sûr, je suis très regardant pour ne pas le provoquer, mais lorsqu'il arrive, je trouve que le choix de Google est généralement le bon dans le choix de la page à déclasser.
- Patrick : C'est quasiment impossible à savoir actuellement, sauf manuellement avec des morceaux de phrases entre guillemets dans les recherches Google.
- Denis: soit il est interne de manière évidente (ie : problématique des tags, URL à variables dont la position n'est pas respectée (&a=1&b=2 par endroits, et &b=2&a=1 à d'autres), reproduction de contenu syndiqué..., soit il faut l'identifier par une recherche Google.
- L. Jee : Interne = le texte est sur plusieurs de vos pages, externe = le texte est sur votre ou vos pages mais aussi sur des pages d'autres sites.
- Olivier : pour savoir si la cause du filtrage est interne ou externe, c'est très difficile. Il faut faire de nombreux tests (requêtes Google). Il faut aussi savoir analyser toute la structure du site pour étudier si la cause peut être interne (ce qui à mon avis est bien plus rare).
A propos des solutions pour sortir d'un filtrage DC
Quand une rubrique d'un site est filtrée pour cause de DC, une solution qui semble fonctionner est de réécrire un par un chaque contenu afin qu'il soit unique (ex: descriptions de produits sur un site marchand, descriptions de sites dans un annuaire).
Quel outil faut-il utiliser pour mesurer le taux de similarité du contenu réécrit avec ce qui existe ailleurs sur le web ? Autrement dit, comment faire concrètement pour vérifier qu'on ne risque plus d'être considéré comme un contenu dupliqué ? Cela suffit-il de chercher dans Google des extraits du texte à analyser (en mettant des guillemets) ? Si oui, faut-il tester plusieurs extraits ou un seul suffit ? Quelle taille (nb de mots) utiliser pour ces extraits ?
- Sylvain : J'utilise Google ou CopyScape. Pour Google, je fais des sélections de phrases. Encore une fois, il faut relativiser mes réponses. Je suis plus souvent dans le cas du "copié" que dans le cas du "copieur", que ce soit pour mes sites ou ceux de mes clients. Une fois que le site original a acquis une certaine autorité, le DC n'est plus gênant en termes de positionnement. J'avoue donc ne pas trop m'en préoccuper.
- Blman: Là encore, je ne peux pas répondre puisque je n'ai jamais eu à sortir d'une telle situation. En revanche, sur ce site e-commerce, je compte beaucoup sur les avis utilisateurs pour éviter un filtrage, puisque je suis sûr qu'il s'agit d'un contenu rédigé par nos clients, donc original et unique. Mais aujourd'hui, à peine 10% de mes fiches produits ont au moins un avis. En revanche, peut-être que ce site ne subit pas de filtrage grâce à certains paramètres :
- j'ai toujours fait attention à faire du référencement propre
- j'ai de nombreux liens naturels (oui, ça existe encore) et je pourrais même dire qu'ils constituent une bonne partie de mes backlinks.
- les intitulés de mes backlinks sont toujours variés, une bonne partie pointe vers de très nombreuses pages internes, et se renouvelle dans le temps (progressivement, de manière naturelle)
Donc, même si on ne peut pas le mesurer, je pense avoir un bon indice de confiance au regard de Google. De plus, le domaine est exploité depuis 1999 ce qui représente 11 ans d'ancienneté. Peut-être que tous ces élements externes me permette de ne pas être filtré.
De manière un peu plus "philosophique", admettons que pour une recherche, Google ait à choisir parmi une dizaine de pages strictement identiques mais qu'il ne veuille en ressortir qu'une seule à l'internaute. Essayons de nous mettre à sa place pour faire ce choix :
- Priorité au contenu le plus ancien ?
- Priorité au site qui a le meilleur indice de confiance ?
- Priorité au contenu qui a la meilleure popularité (PageRank) ?
- Patrick : Pour avoir essayé en long et en large CopyScape, ça ne sert à rien.Pour le nombre de mots, c'est quasiment impossible à répondre. Un petit truc quand même : mieux vaut faire clairement ressortir le duplicate en cas de citations comme ici avec WebRankInfo où une de tes phrases est clairement mise en évidence avec un lien devant.
- Denis: personnellement, je fais plusieurs vérifications : par paragraphe, puis phrase par phrase. La réécriture de contenu est une solution, mais il est également intéressant d'envisager la dilution du contenu dupliqué. La plupart du temps, le contenu dupliqué est un contenu syndiqué (RSS, affiliation, marques blanches, etc.). Il peut être utile de greffer sur ce contenu des informations (en adéquation avec le contenu) qui permettent de diluer l'impact du contenu dupliqué sur le poids total de la page.
- L. Jee : Alors, effectivement, chercher sur Google est suffisant, toutefois, il ne faut pas analyser qu'une seule phrase, bien que celle-ci peut vous assurer que vous êtes filtré, mais pour autant si le copieur n'as pris que la moitié du texte, cette phrase pourrait ressortir comme unique aux yeux de Google alors que votre page est ignorée du fait du reste du texte qui lui est copié. Le mieux est d'analyser chaque phrase et de réécrire chacune de celles qui sont dupliquées.Pour ce qui est de la taille de l'extrait, j'ai pu constater des pages qui se faisaient ignorer alors que le "copieur" n'avait pris que 10 mots d'un texte de 400 : ce sont les aléas de ce filtre bancal...Bref, autant ne pas prendre de risques et tout réécrire.
- Olivier : Je teste sur plusieurs suites de N mots prises dans le texte (N autour de 10) avec des guillemets.
Combien de temps faut-il attendre pour que Google supprime éventuellement son filtre ? Quand une page anciennement filtrée est recrawlée par Google, sort-elle du filtre immédiatement si son contenu est considéré unique ? Ou bien faut-il attendre que 100% des pages filtrées aient été corrigées (contenu réécrit) et recrawlées par Google ? Est-ce conseillé de remplir une demande de réexamen (dans Google Search Console) ou bien vaut-il mieux éviter ?
- Sylvain : Mon seul cas personnel est un oubli idiot de contenu sur un domaine alors que ce même contenu avait été transferé sur un autre. La solution a donc bien entendu été la suppression totale.
- Patrick : Si la page est complètement corrigée, le résultat est presque immédiat. Un examen ne sert à rien, il faut juste attendre le passage des robots.
- Denis : la problématique du DC est reconnue par Google. Si un cas de DC est avéré, et qu'il est évident qu'il n'y a pas d'autre problème (cloaking, sur-optimisation, sous-optimisation, bugs,...), on peut gagner beaucoup de temps à remplir une demande de réexamen (NB : toujours clean, explicite, etc. of course!)
- L. Jee : Pas besoin de demande de réexamen pour ceci car comme le diront certains, il ne s'agit que d'un filtre automatique, ce qui veut dire qu'une fois l'erreur corrigée, le site reviendra dans les SERP. Pour ma part, j'ai sorti du filtre duplicate content de Google plusieurs sites et tous n'ont pas été nettoyés à fond. J'aurais tendance à dire qu'il y a un certain pourcentage de tolérance et qu'au-delà un site est filtré ou non. Il se pourrait que cette tolérance soit en corrélation avec le niveau de confiance du site aux yeux de Google. Pour ce qui est de la durée, je l'ai définie entre 3 et 4 semaines pour que le site revienne dans les SERP après nettoyage du duplicate content. Lisez la discussion Comment sortir d'une pénalité Google de Duplicate Content.
- Olivier : Il n'y a pas vraiment de règles, cela dépend du volume de pages filtrées et d'autres paramètres plus complexes. En général il faut avoir "nettoyé" un gros pourcentage des pages concernées pour sortir du filtre, plusieurs semaines après. La demande de réexamen ne me semble pas appropriée, sauf si vous aviez enfreint d'autres règles de Google...
Edit : depuis la publication de cet article (mars 2010), il n'est plus possible de demander un réexamen si aucune pénalité manuelle n'est appliquée au site. Etant donné que les problèmes de contenus dupliqués sont exclusivement algorithmiques, cette question n'a aujourd'hui plus de raison d'être.
On a beaucoup parlé ces derniers mois du duplicate content dans le cas des annuaires : il est désormais très courant d'avoir à la fois des pages de catégories et des pages décrivant chaque site inscrit. Quand l'annuaire est victime du filtre Google de DC, est-ce l'ensemble de l'annuaire qui est généralement touché ou bien seulement un type de pages (catégories, sites) ? Et quand on réécrit les contenus (nom et description de chaque site), est-ce que les 2 types de pages sortent du filtre ou bien seulement l'un des deux ?
- Sylvain : Je n'ai pas de retour personnel sur le sujet. J'ajouterai seulement que pour les annuaires, depuis très longtemps, je ne fais QUE des descriptions uniques. J'essaie de ne conserver QUE les annuaires proposant une page complète pour mes descriptions (à quelques rares exceptions comme l'annuaire WRI). En gros, je ne veux pas scier la branche sur laquelle j'assois mes BL.
- Patrick : Pas de cas, pas de réels annuaires sur mes sites.
- Denis : Avec des extraits suffisamment courts et des descriptions suffisamment longues, on évite ce problème. Je ne pense pas qu'il y ait de discernement par "type" de page.
- L. Jee : Question troublante, car l'annuaire comme tous les sites peut-être victime du duplicate content de deux façons. Soit la page dupliquée est filtrée et est, seulement elle, filtré dans les SERP, soit on en revient au pourcentage et au dela d'un certain pourcentage c'est tout le site qui plonge. Après réécriture, idem, soit la page revient, soit c'est tout le site. Le contenu dupliqué pénalise les pages (catégories, tags, fiches ou ce que vous voulez) qui affiche le texte dupliqué et si trop de duplicate, c'est tout le domaine qui en souffre.
- Olivier : Là aussi cela dépend des cas mais en règle générale je pense que toutes les pages sont concernées de la même façon.
Contenus presque dupliqués internes
On sait bien qu'il peut y avoir des cas de contenus dupliqués internes : il s'agit en général d'erreurs techniques sur le site qui font que certains contenus sont accessibles à plusieurs URL. Mais il peut aussi y avoir des contenus presque dupliqués (near-duplicate content) : il s'agit de pages ayant un contenu réellement différent mais se ressemblant malgré tout.
Est-ce possible que le filtre de Google sur le contenu dupliqué s'applique aussi à des contenus presque dupliqués internes ?
- Sylvain : Je l'ai vu (boutique en ligne)
- Blman : J'ai de très nombreuses pages (voire des milliers) en near-duplicate content et pas de filtre.
- Patrick : Google fait très bien la distinction entre la navigation et le contenu. Pour avoir essayé de briser la navigation, seules les pages où cette navigation était peu utilisée se sont fait casser.
- Denis : c'est un risque
- L. Jee : Presque ? C'est à dire ? Même header, même footer et même menu ? Non je ne crois pas, tout comme je ne crois pas qu'un texte de 4 lignes sur toutes les pages pénalisent qui que ce soit, j'ai plusieurs exemples flagrants. En dehors du fait qu'un site peut-être inquiété car il a plusieurs URL pour la même page, je ne pense pas que le duplicate interne engendre de filtrage ou de pénalité. Cependant, on peut tout à fait admettre, prenons exemple du site avec et sans les www, que Google va prendre en compte la home sans www puis les pages de premier niveau avec les www, second niveau sans www etc. L'écoulement du poids (appelez-le PR, juice ou ce que vous voulez) s'en trouve entravé et de se fait se propage mal, ce qui aurait pour conséquence que les pages perdraient en positionnement ou disparaitraient. Un coup celle avec les www, un coup celle sans...
- Olivier : En fait ma question était sans doute mal posée car en réalité, tous les cas difficiles concernant le duplicate content sont en fait des cas de near-duplicate content.
Dans ce cas comment l'identifier et que faut-il faire pour s'en sortir ?
- Sylvain : Le report du texte dupliqué en bas de page et un texte différenciant en haut de page ont suffi pour lever le filtre.
- Blman : comme expliqué plus haut, je compte réellement sur les avis utilisateur
- Denis : dilution du contenu (par adjonction), et travail sur le <title> de la page et les éléments lourds (balises h1, h2...) pour renforcer la différenciation.
- L. Jee : Une URL par page et plus de problème.
- Olivier : Il faut être très rigoureux en interne pour ne pas publier substantiellement le même contenu à différentes URL. Par exemple dans un blog il faut éviter d'avoir à la fois des catégories et des tags qui portent les mêmes libellés.
Les sites qui peuvent échapper au filtre
En pratique, les choses ne sont jamais toujours les mêmes : il peut y avoir des sites avec peu de contenus dupliqués qui semblent filtrés, tandis que d'autres en ont beaucoup mais ne semblent pas filtrés. Comment est-ce possible ?
Premièrement, je pense que ce filtre se déclenche à partir d'un certain seuil : tant qu'on n'a pas atteint une certaine "dose" de contenus dupliqués, on échappe au filtre. Cette dose est-elle mesurée en nombre de pages, en proportion de pages ou autre chose ?
Deuxièmement, tous les sites ne sont pas égaux devant ce filtre. Il apparait que dans les cas suivants on réussit mieux à y échapper :
- le site jouit d'une forte notoriété aux yeux de Google (certains appellent ça (à tort) le TrustRank)
- le site (et surtout les pages concernées) sont anciennes
- les pages concernées citent la source reprise (via un lien)
- les sujets traités ont été identifiés par Google comme étant très largement repris sur le web (synopsis de films de cinéma, documentation officielle dans l'informatique, etc.)
N'hésitez pas à donner vos commentaires notamment pour cette partie de l'article...
Conclusion et débats
Félicitations, vous avez réussi à lire tout ce dossier ! J'espère qu'il vous aura plu et surtout qu'il vous aidera à trouver des solutions (ou à mettre en place des actions de prévention des risques). Nous discutons de ce dossier sur le filtre Duplicate Content de Google dans le forum.
Sachez aussi qu'il y a une discussion spécifique dans le forum pour obtenir de l'aide pour résoudre vos problèmes de contenus dupliqués.
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

C'est effectivement très difficile de définir un seuil comme de définir à quel point un article est dupliqué en particulier lorsque les marketeurs utilisent les mêmes recettes pour les titres comme par exemple "les 13 tendances à suivre en seo pour 2019'. Je suis convaincu que l'on va trouver un grand nombre d'articles sur les tendances.
Bonjour Olivier,
merci pour ce bon dossier!
ma question c'est comment échapper pour les sites streaming qui sont souvent a des descriptions du films identiques
A bientot!
@Salah : c'est pas évident mais peut-être pris en compte par Google. Il faut apporter d'autre contenu que le synopsis du film.
Copyscape est la meilleure façon de detecter les contenus en doublon sur le web ça vous évite d'avoir des phrases et des textes non indexés surtout dans Google.
Bonjour,
Petite question à laquelle je n'arrive pas à trouver de réponse...
Peut-on considérer une page dupliquée si elle est accessible via : http://www.domaine.com/texte1 et http://www.domaine.com/texte1?
(souci rencontré après une réécriture). Pour moi, j'ai bêtement deux pages différentes mais est-ce que le ?" est vraiment différenciateur ?
Merci pour votre aide !
Oui Lucile, théoriquement l'URL avec le signe ? à la fin est différente de l'autre, il faudrait éviter de générer cette autre URL.
Le mieux pour nettoyer, c'est une redirection 301 et si c'est trop compliqué, il faut définir une URL canonique
MERCI D AVOIR REPONDRE A MA QUESTION POUR LES OUTILS J AI DEJA TROUVE LA PAGE COPYSCAPE
MERCI POUR VOTRE SOUTIEN MR OLIVIER DUFFEZ
@espaceampouleled Une des solutions serait de réecrire ton textes de présentation de produits, afin de proposer un contenu unique sur la toile, je pense que Google va apprécier...
Sinon, je cherchais des informations sur le duplicate content, j'ai relu cet article et je me posait une question ...
Est ce qu'on peu parler de duplicate content si on utilise des images déjà présentes sur le web ?
Cet article date un peu, mais je pense avoir fait la boulette de m'inscrire sur les comparateurs, ceux ci ont récupéré mon flux et quelques jours plus tard j'ai perdu de précieuses places sur google, savez vous comment faire pour limiter le contenu dupliqué ?
bonjour
je suis actuellement en train d apprendre que pour etre indexe par les moteurs de recherche dont principalement google bing et yahoo mon contenu doit etre unique mais je voulez savoir s il ya un un logiciel gratuit pour verifier si le contenu d un site est duplique ou non
merci
@ CreationOptimisation : si tu l'as rédigé toi-même, il devrait être unique n'est-ce pas ? sinon, il y a forcément un risque en effet. Mon dossier liste quelques outils.
Bonjour,
La dé-classification d'un site faite par Google, qui considère qu'il y a DC, est-elle selon vous définitive ou y a t-il ré-examen à fréquence régulière du site ?
régulière je pense, après faut voir si c'est couplé avec Panda
Ok, merci pour votre aide.
Oui, il est revenu sur mes pages, et les pages du copieur également. Les pages du site copieur n'ont pas été désindexé, à dire vrai, les textes volés ont été modifié et c'est tout. Il reste encore quelques similitudes avec mes textes mais ne sont plus identique. Faut-il que je demande la suppression total des textes ? J'ai perdu 80 % de mes visites. Mon site est remonté de la page 4 à la page 2, puis plus rien, ça ne bouge plus. Merci
@Nat : il peut y avoir d'autres raisons. Le plus efficace serait de créer une discussion dans le forum (en + il y aurait + d'aide qu'ici)
Bonjour,
Un site a copié la quasi totalité de mes textes (intro, cgv, livraison…) il y a 2 mois maintenant et j'ai subi une perte de position de page 1 à 4. Les textes copiés ont été retiré mais je n'ai pas retrouvé mes positions d'avant. Dois-je modifier également mes textes pour sortir de la pénalité. Merci pour vos conseils.
@Nat : Est-ce que Google est revenu crawler tes pages ? Et les pages du copieur ont-elles été désindexées de Google ?
Salut ,
une page de mon site a été pénalisé par Panda et cela suite au Duplicate Content .
En effet Ma page X est positionné première sur les résultats de recherche pour un certain mot clé Y , mais à partir du jeudi dernier , elle ne s'affiche plus dans les résultats de Google pour le mot clé Y
En utilisant un outil de Détection du Duplicate Content (positeo) , je découvre que la page qui a pris la première position est un contenu double de mon article et pire c'est un copier coller à 100% (même le nom de domaine de mon site est affiché dans son contenu !!!)
comment je dois procéder , est-ce qu'il y a un outil pour alerter google de cette erreur .
Merci d'avance
@Sebastien : ce n'est pas Google qu'il faut prévenir... Il faut demander au copieur de supprimer la page en faisant valoir vos droits d'auteur.
merci pour cet article
mais bon il est rassurant et en même temps inquietant.
Chacun donne son avis et sa propre expérience mais on ne sait toujours pas quelle est la vraie réalité de google sur le DC.
Hello
Super article, Bravo.
Une question bete: comment google traite il le contenu des agences de presses, reuters ou AP, qui distribue leur news à toute une série de site web.. LEs URLS sont surement différent (car géré par chaque site) amis le contenu - en intégralité - est le même... Est- ce que tous les clients de reuters sont pénalisés ?
Merci de vos lumières
Clément
@Clément : les sites qui exploitent un contenu acheté à une agence de presse sont eux aussi confrontés aux problèmes de contenus dupliqués. Parfois ils s'en sortent grâce à leur notoriété, ou par un mélange avec leurs propres contenus.
Bonjour,
je viens de faire un test est j'ai trouvé une duplication d'une de mes pages sur un site.
environ un paragraphe complet qui me gêne fortement.
Comment dénoncer cette abus et à qui pour le faire retirer?
Merci
Il faut contacter le site qui a reproduit ce texte et lui demander de le retirer.
Est-il exact qu'en modifiant le premier et le dernier paragraphe d'une article copié, la nouvelle page ne sera pas considérée comme étant un contenu dupliqué ? Merci
Non c'est faux, Google pourra le détecter facilement. En tout cas c'est n'est pas ce que je conseillerais.
Merci pour cet excellent article :)
C'est vrai .. Google a notamment un filtre de détection de contenu dupliqué qui dans certains cas peut faire chuter de 95% le trafic généré vers un site.
Salut, juste un mot pour signaler cet autre outil sympa de détection du DC
Excellent article, félicitations pour cette mine d'information sur le contenu dupliqué et tous ces témoignages !
J'ai connu cette situation et il est très intéressant pour moi d'avoir ces informations sous la main.
La détection du DC est en effet quasi instantanée !
Très bon article effectivement. Je rajouterai qu'il est très difficile de lutter cependant contre du contenu dupliqué externe d'un site tout frais dont Google à peu de trace. Le duplicate se détecte à posteriori.
Super article, merci.
Bonjour,
Cet article me paraît excellent. Une question: y a-t-il duplicate content si un même texte (un livre) se trouve en format pdf et html sur un même site? Je suppose que non, mais question plus délicate, dans le même sens, le Duplicate content concerne-t-il les fichiers pdf de Google Books ou bien est-ce que Google Books, c'est à part? Par exemple si on a un ouvrage à 30 % voire 100% de visibilité sur Google Books et sur son site un fichier pdf similaire?
Le format PDF est très bien lu et indexé par Google donc oui, cela peut causer des problèmes de contenus dupliqués. Si le PDF existe déjà de façon tout à fait équivalente (en qualité) en HTML, il vaut mieux éviter de le faire indexer.
Je pense que les contenus indexés par Google Books sont en effet à part, non concernés.
Merci pour cette article. Sauf erreur de ma part (j'avoue avoir lu certains paragraphe en diagonal) on parle tres peu ds cet article du tag rel canonical.
Ca ne vous semble pas pertinent ?
Avez-vous mesuré son effet ds le cas de contenus syndiqués ou marque blanche ?
Est-ce que ca a un impact réel sur le site originel (progression ds les serp) et sur les autres sites ? (déclassement ? Exclusion ?)
@Douda : J'aborde la balise d'URL canonique dans mon article sur les solutions pour corriger le duplicate content (qui sont pour la plupart des erreurs internes). Ici mon dossier est axé essentiellement sur le filtre de contenus dupliqués de Google.
Très bon article, en effet.
Petit regret concernant ces logiciels, ils n'ont pas l'air de donner la fameuse "page canonique" que Google retient comme source officielle du texte. Ca m'aurait intéressé, non seulement de savoir qu'un texte était copié mais aussi qui en était l'auteur originel :-).
Très intéressant et c'est la première fois que je lis le terme de "duplicate interne"..
Pour le DC interne et en particulier en cas d'erreur d'URL, le plus simple reste encore d'aller sur "Webmaster tools" et de regarder les "suggestions HTML". Logiquement, le title (etc.) sera en double, on verra rapidement qu'il existe plusieurs URL pour le même titre et donc théoriquement la même page/contenu.
Super article !! félicitations. Par contre, je me posais une question, j'ai fait le test sur le contenu dupliqué du premier paragraphe de axe-net, et moi, google me trouve 333 résultats, et il ne m'informe de contenu dupliqué qu'au bout de la sixième page. Alors axe-net est en premier, mais les autres n'ont pas du tout disparus. Est-ce que c'est parce que ça a changé depuis cet article, ou est-ce que parce que google ne donne pas à tout le monde la même chose ?
J'ai fait la recherche sur le premier paragraphe, qui est en fait une seule phrase, avec les guillemets.
Alors là, je suis vraiment soufflé par la qualité de cet article. Félicitations!
En général, je place sur chaque page un lien vers elle-même. Dans certains cas, la personne qui copie le contenu copie aussi le lien et permet à Google de canoniser ma page. Pas vraiment réalisé de vrais tests mais j'ai l'impression que ça aide.
Encore une fois, bravo pour l'article ! ;)