Ce dossier SEO vous explique à quoi sert et comment utiliser l'entête HTTP X-Robots-Tag (noindex, nofollow, etc.).

WebRankInfo : la plus grande communauté francophone du référencement

Cette rubrique regroupe des articles d’actualité, des conseils et des tutoriels pour aider à faire indexer un site et donc optimiser son référencement naturel (SEO). On y parle donc de crawl (exploration), d’indexation de site, de fichiers sitemaps, de comment supprimer une page de Google…

Mes services pro : ![]()
Ce dossier SEO vous explique à quoi sert et comment utiliser l'entête HTTP X-Robots-Tag (noindex, nofollow, etc.).

Le crawl prédictif de Google : il ne veut plus tout indexer...
C'est plus dur qu'avant de faire indexer (et même crawler) des pages dans Google. Découvrez ce qui a changé chez Google et comment savoir si votre site est concerné.

Checklist : 9 étapes pour faire indexer vos pages dans Google
Marre des pages que Google n'indexe pas ? Suivez mes étapes concrètes pour faire indexer vos pages et obtenir un bon SEO par la même occasion 😎

Comment désindexer des pages de Google ? Le tuto ultra complet !
Il est bien plus courant qu'on ne l'imagine d'avoir besoin de désindexer des pages de Google, c'est-à-dire de les supprimer de l'index. Ceci permet de nettoyer le site et parfois de sortir d'une pénalité. Voici comment faire...

Faire indexer les pages dont Google ne veut pas grâce à un bon maillage interne
Quand Google ne veut pas indexer des pages, c'est parfois car elles n'ont pas assez d'importance selon son algo. Un bon maillage interne peut régler le problème.
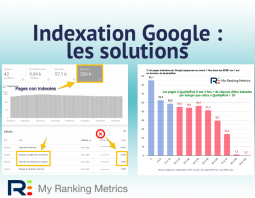
Découvrez pourquoi Google a décidé de ne plus indexer toutes les pages que vous lui donnez. Et surtout les solutions qui fonctionnent tout en améliorant le SEO du site...

Depuis le 1er mars 2020, Google peut décider de suivre des liens nofollow. En interne, ça peut mettre le bazar (masse noire) si vous ne faites pas attention. Découvrez comment vérifier si cela impacte le SEO de votre site et les solutions à adopter.

Google : crawl et indexation malgré interdiction via fichier robots.txt ?
Depuis 2012 environ, il est parfois difficile de comprendre si Google respecte vraiment bien les directives du fichier robots.txt (qui interdit l'accès aux URL, c'est-à-dire leur crawl, et donc leur indexation). Certaines pages peuvent désormais être trouvables dans Google sans que Google les ait crawlées : elles sont ni indexées ni inconnues... Ce dossier fait le point sur ce sujet.

Le fichier robots.txt permet de bloquer le crawl des moteurs de recherche pour certaines URL ou parties d'un site. Ce dossier détaille tout, avec plein de conseils SEO que vous ne connaissiez peut-être pas...

Vérifiez les balises meta robots noindex partout dans toutes vos pages !
Vous pensiez qu'on ne trouve une balise meta robots noindex que dans l'entête HTML ? Sachez qu'elles trainent parfois (par erreur) dans le reste de la page et que Google en tient compte. Vérifiez si votre site n'a pas ce problème, comme celui pris en exemple dans cet article.

Pour que votre site soit bien indexé dans Google, il doit être bien crawlé (exploré). On parle parfois de budget de crawl, ou de quota de crawl, qui limite le crawl de Google. Ce dossier vous dit tout à ce sujet !

SEO : 27 erreurs qui peuvent désindexer vos pages sans que vous vous en rendiez compte
Il existe pas mal de cas où vous pouvez faire une erreur avec des instructions noindex ou des URL canoniques. Consultez cet article pour vérifier que ce n'est pas votre cas...
On connaissait la balise d'URL canonique, voici désormais sa version paramétrable directement dans l'entête HTTP. Explications...
Google sait crawler des pages dont le contenu s'adapte selon la langue ou le lieu du visiteur
Google sait désormais crawler et indexer des pages dont le contenu s'adapte selon la langue ou le lieu du visiteur (la "locale"). Attention, ce n'est pas pour autant la meilleure conception du site pour le référencement international. Explications...
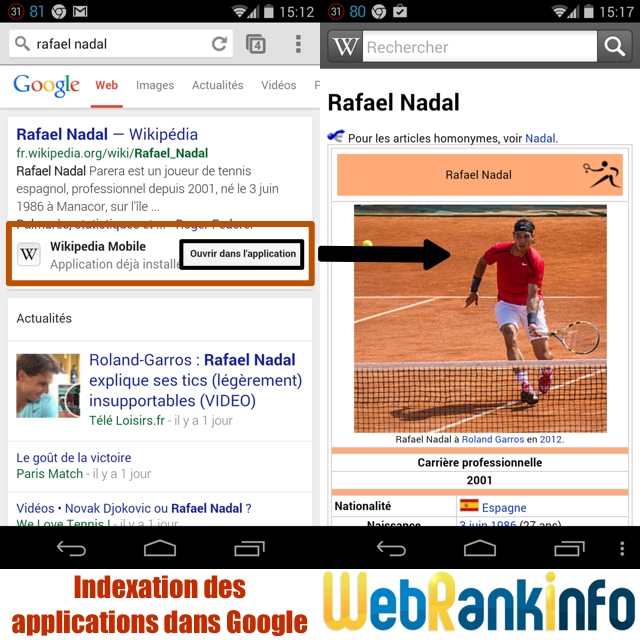
Il est désormais possible de faire indexer votre application mobile dans Google, afin qu'elle apparaisse directement dans les résultats de recherche sous forme d'un bouton, quand une des pages de votre site sort dans les SERP (recherche "In App").
Référencement : différence entre Expires et unavailable_after
Ne confondez pas l'entête HTTP Expires et la balise meta unavailable_after, sinon vous risquez d'avoir des problèmes d'indexation Google...
Pour mieux comprendre la sémantique des données présentes dans les pages web, les moteurs ont besoin que les données structurées soient formatées avec un standard connu. Jusqu'à présent, plusieurs standards cohabitaient (microformats, RDFa, microdata, etc.). Les 3 moteurs de recherche Google, Bing et Yahoo ont décidé de se regrouper pour créer un nouveau standard commun intitulé schema.org, à la manière du standard sitemaps.org. Explications...
Cet article présente la notion de blacklistage (blacklisting) de Google et indique ce qu'il faut faire si votre site est ainsi banni de l'index Google.
Pour indexer des millions de pages tous les jours, Google utilise une "armée" de robots d'indexation, appelés GoogleBot (lire l'étude sur GoogleBot pour en savoir plus). A chaque fois qu'un de ces robots visite une page, il la récupère et la stocke sur un des serveurs de Google. Cette version du document est appelée la version cache. On comprend vite qu'avec des milliards de documents Google ait besoin de plus de 10 000 serveurs (et beaucoup de disques durs...).
Les milliers de serveurs de Google sont répartis sur des centres de données, appelés Data Centers. Voici la liste des premiers data centers de Google...