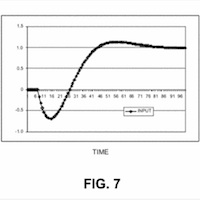
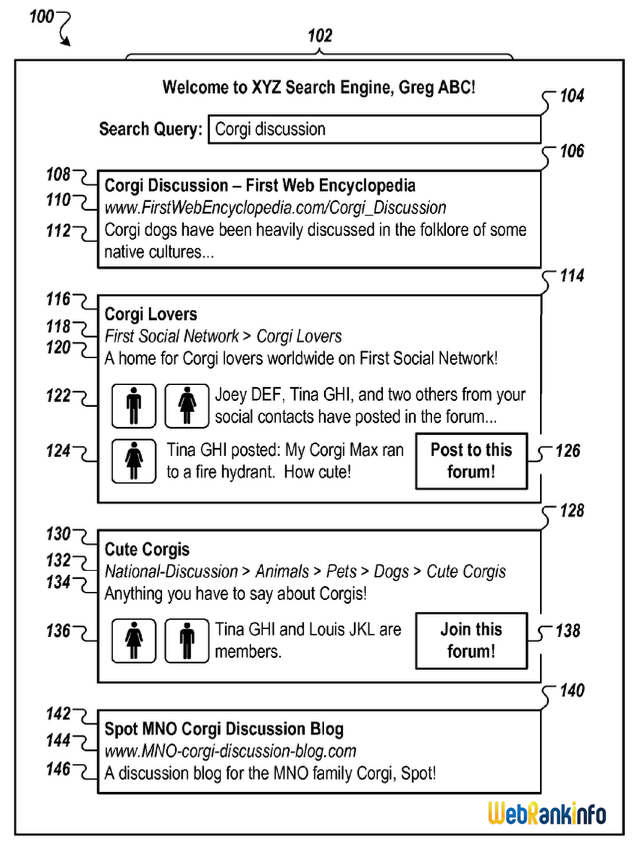
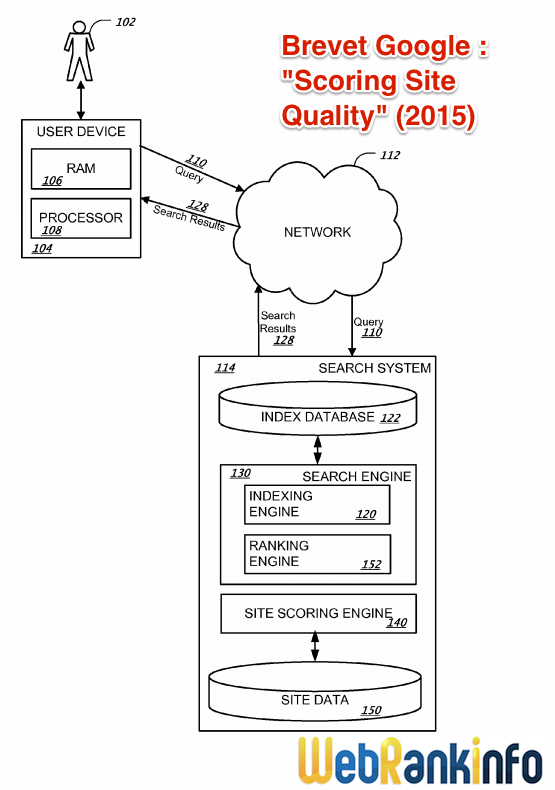
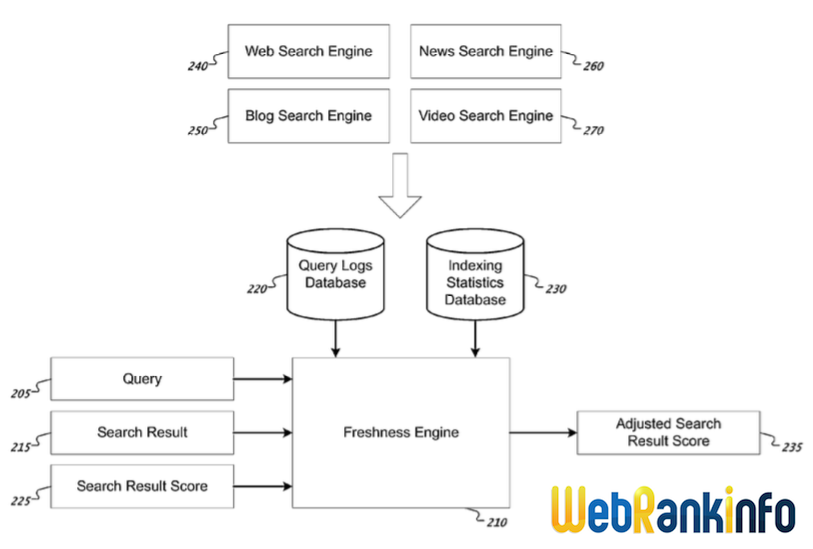
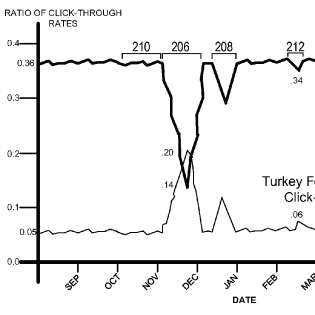
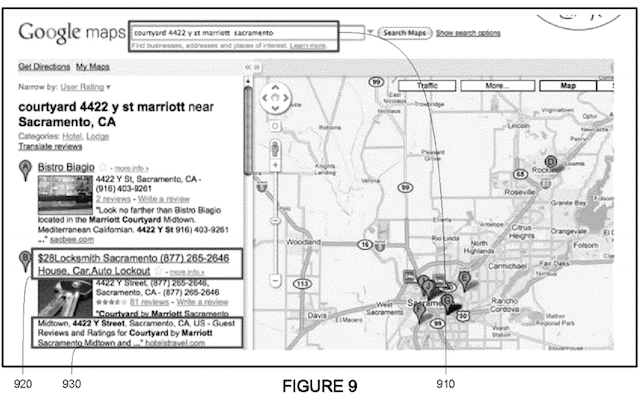
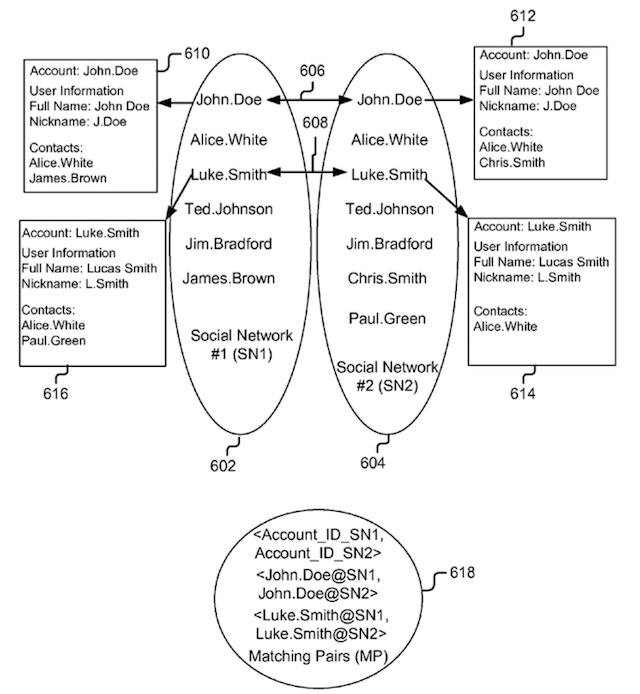
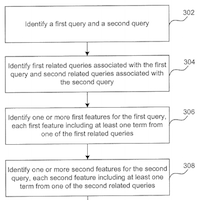
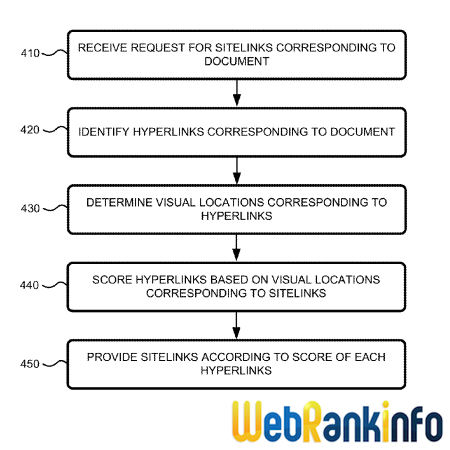
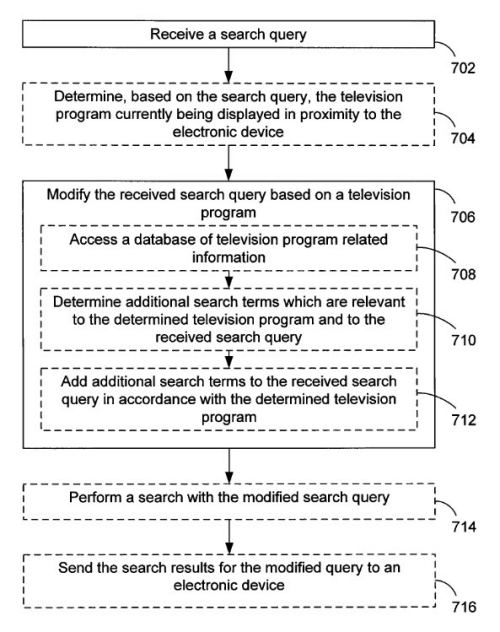
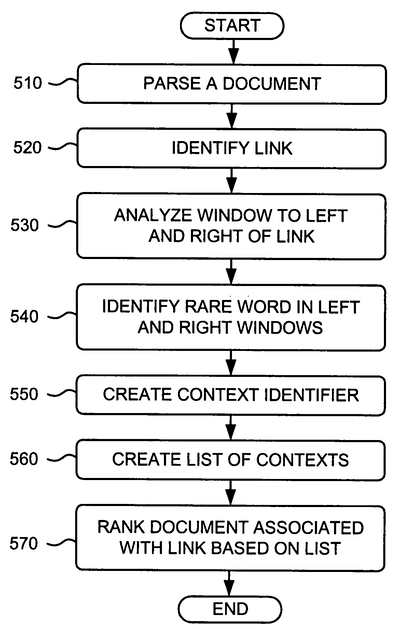
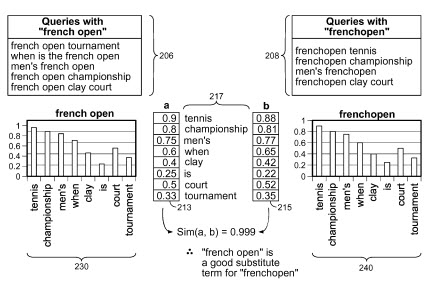
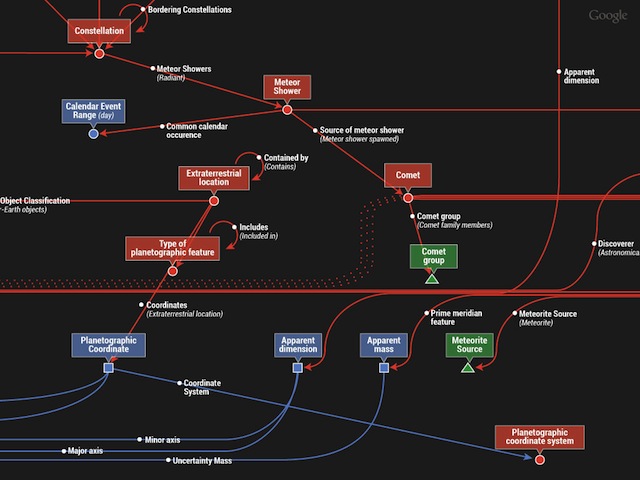
Google vient de se voir attribuer son brevet "Ranking Documents" dans lequel l'auteur (Ross Koningstein) décrit un système de période de transition pendant laquelle le positionnement d'une page est arbitrairement perturbé pour mieux détecter les spammeurs.