

Voici le sommaire de ce dossier à mettre dans vos favoris :
- l'algo Google (référencement naturel)
- les 20 principaux algorithmes
- 8 points-clés pour le SEO sur Google
- fonctionnement de l'algo
- infographie : fonctionnement du moteur de recherche Google
Pas envie de tout lire ? Voici l'essentiel :
- Les principales mises à jour de l'algo de Google concernent désormais la qualité globale du site. Il n'y a plus de nom unique, le nom générique est désormais Core Update.
- Google centre son discours autour de la notion de contenu utile. En 2022 et 2023 on parlait beaucoup de Helpful Content Update (HCU). Mais depuis mars 2024 c'est désormais géré par les Core Updates.
- Si vous chutez lors d'une mise à jour officielle :
- ne réagissez pas dans la précipitation
- faites un audit pour avoir une vue d'ensemble des problèmes du site (ce que fait mon outil RM Tech)
- quand vous aurez au moins 2 semaines de recul, comparez les données avant-après (lisez mon ebook sur l'analyse d'une chute SEO)
- Pour les détails, lisez comment réagir face à une mise à jour globale de Google
C'est quoi l'algo Google (référencement naturel) ?
Il n'y a pas 1 mais de multiples algorithmes Google
Pour simplifier, on peut dire qu'il n'y a pas un algorithme de classement de Google, mais une constellation d'algorithmes qui se cumulent. Au passage, c'est devenu tellement complexe que même chez Google ça doit être très dur de bien s'y retrouver ! Je pense même qu'à cause de cet enchevêtrement d'algos, de filtres et autres critères, il doit y avoir beaucoup d'effets de bord incontrôlés...
Partagez l'info :
Remarque : j'utilise le terme algorithme mais c'est parfois impropre, il faudrait aussi utiliser "filtre" ou d'autres mots, mais je simplifie ici.
La plupart des algorithmes (sinon tous) ont vocation à améliorer la pertinence des résultats de recherche. Mais certains sont prévus pour :
- pénaliser les sites ou pages qui ne respectent pas les consignes (par exemple des backlinks artificiels ou du bourrage de mots-clés)
- favoriser les sites ou pages qui ont une caractéristique précise (par exemple la vitesse, le protocole sécurisé HTTPS, la compatibilité mobile...)
Google ajoute, modifie et supprime des algorithmes en permanence (plusieurs milliers de modifications par an). C'est important pour vous de rester au courant de toutes ces évolutions !
L'algorithme de recherche Google en résumé
Comment fonctionne l'algo de Google en ce moment :
- En plus des milliers de modifications indétectables, certaines sont très grosses et annoncées officiellement. Leur déploiement prend généralement plusieurs jours, parfois 2 semaines.
- C'est le cas des Core Updates (2 à 4 par an) qui inclut désormais les Helpful Content Updates (HCU).
- Google vise essentiellement à identifier la qualité globale du site. Pour réussir ou remonter après une chute, il faut améliorer globalement le site et être patient...
Si vous avez du retard ou que vous découvrez le SEO, voici les précédents changements des 5 ou 10 dernières années :
- Votre site doit être compatible mobile (selon Google), sinon votre classement sur mobile est moins bon. C'est encore plus important maintenant que Google est passé à un index "mobile first". Vous ne devez pas afficher de pop-up ou de bannière interstitielle intrusive à l'internaute qui arrive de Google.
- Votre site doit également être très rapide, aussi bien sur desktop que sur mobile (impact faible). D'autres aspects liés à l'UX (expérience utilisateur) sont pris en compte par Google (les signaux web essentiels, Core Web Vitals)
- L'algorithme Panda est intégré à l'algo général, si bien qu'il n'y a plus de date officielle (la dernière remonte à 2015). C'est un algo majeur de Google qui cherche à favoriser les sites de qualité. Son successeur semble être HCU.
- Penguin est désormais lui aussi intégré à l'algo de Google, avec des mises à jour "en temps réel". C'est un autre algo majeur de Google.
- Google incite à migrer vers HTTPS mais l'impact SEO est faible
- Google a un algorithme spécial contre les pages satellite (attention, leur définition semble large, l'impact peut concerner beaucoup de monde), en place depuis 2015
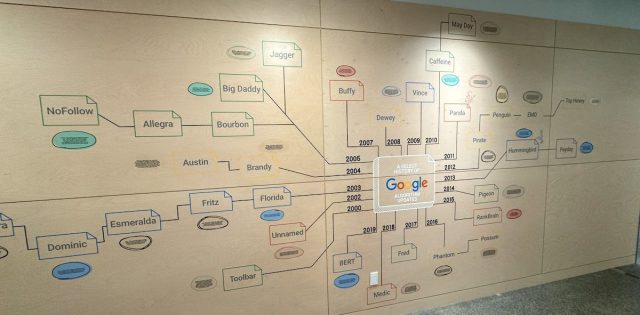
Liste des principaux algorithmes de Google (SEO)
Voici une liste, triée par ordre d'importance actuelle, avec pour chacun :
- son nom (officiel ou pas)
- la date de sa dernière mise à jour (ou la date prévue pour sa mise en ligne)
- une brève description
- des liens pour obtenir de l'aide et des conseils gratuits, ou un devis d'audit, ou une formation adaptée
Je compte sur vous pour me signaler les oublis ou manques de mises à jour !
Ne ratez pas non plus les questions-réponses ci-dessous
1 Cores Updates
- Il existe plusieurs changements majeurs d'algo qui n'ont pas toujours de nom officiel. Parfois un nom s'impose dans la communauté SEO, même s'il ne décrit pas toujours très bien la réalité. Depuis mars 2019, Google propose de les appeler Core Update suivi du mois de sortie.
- Les dates des dernières Core Updates (officielles) sont les suivantes : juin 2025, mars 2025, décembre 2024, novembre 2024, août 2024, mars 2024, novembre 2023, etc. Retrouvez leur annonce sur le forum Référencement Google de WebRankInfo.
- Medic est sorti le 1er août 2018, peu de jours après la mise à jour du guide officiel de Google à ses Quality Raters. Avec ce changement, il semblerait que les critères E-E-A-T (Expérience, Expertise, Autorité, Confiance) soient encore plus importants qu'avant, surtout pour les contenus YMYL.
- Si vous avez été pénalisé par une de ces mises à jour, je vous recommande de repérer vos "pages zombies"
2 Helpful Content
- Cet algo est sorti pour la 1ère fois le 25/08/2022, puis a été mis à jour plusieurs fois. Depuis mars 2024, on n'en parle plus car c'est inclus dans les Core Updates.
- Google vise à favoriser les sites qui publient des contenus utiles et à pénaliser ceux avec beaucoup de contenus créés spécialement pour les moteurs de recherche.
- L'algo est sitewide, ce qui signifie que si le site est mal vu par cet algo, tout le site peut être impacté, même les bonnes pages...
- En savoir plus : l'algo Helpful Content de Google - Comment remonter après HCU
3 Vitesse et Signaux Web Essentiels (Core Web Vitals)
- La prise en compte des signaux web essentiels est en place depuis l'été 2021
- Pour la vitesse, cet algo est en place officiellement depuis le 9 avril 2010 sur ordinateur et depuis le 9 juillet 2018 sur mobile
- Officiellement : sur ordinateur il vise à favoriser les sites rapides, et sur mobile à pénaliser les sites trop lents
- Pour la vitesse, l'algo est appliqué partout dans le monde (tous pays et langues)
- En savoir plus : comment rendre son site rapide, l'algo vitesse sur mobile, annonce officielle de Google
4 Avis produits (Products Review)
- Cet algo est en place officiellement depuis avril 2021, mis à jour régulièrement
- Officiellement : concernant les avis sur les produits, Google veut favoriser les meilleurs, c'est-à-dire "qui reposent sur des données pertinentes et sur un réel travail de recherche effectué par des experts ou des passionnés qui maîtrisent le sujet"
- Il est appliqué sur plusieurs langues dont le français
- En savoir plus : Products Review Update, annonce officielle de Google
5 Spam Update
- Dates : dernière version sortie le 19/12/2024
- Objectif : réduire le spam visible dans les résultats de recherche, en particulier ce qui concerne le cloaking, le hacking, l'auto-génération et le scraped spam
- En savoir plus : Spam Update décembre 2024, fonctionnement de la détection du spam chez Google
6 Panda
- Dates : sorti en 2011, la dernière mise à jour officielle date du 18/07/2015 mais depuis janvier 2016, Panda est officiellement "au coeur de l'algo" mais "pas en temps réel"
- Panda cherche à évaluer la qualité des sites ; son algo, exploitant les techniques de machine learning, évalue le contenu des pages elles-mêmes mais aussi le comportement des internautes.
- L'impact est sur l'ensemble du site, mais les rubriques de plus faible qualité sont celles qui souffrent le plus en visibilité Google.
- En savoir plus : page centrale sur Panda, pré-audit avec analyse Pages Zombies avec RMTech (et sa vidéo)
7 Pingouin (ou plutôt Penguin)
- Sorti en avril 2012, la dernière version officielle date du 23/09/2016 ; cela étant, depuis cette date Pingouin est intégré dans l'algo global de Google et mis à jour en continu
- Il vise à pénaliser les sites qui ont abusé de techniques qui enfreignent les consignes de Google (on parle aussi de sur-optimisation du référencement). En pratique, il s'agit essentiellement d'une trop grande présence de liens artificiels pointant vers le site.
- En savoir plus : comment éviter Google Pingouin, audit de liens artificiels par Olivier Duffez
8 Compatibilité mobile et index mobile-first
- Cet algo est sorti le 21 avril 2015 au niveau mondial. Renforcé en mai 2016, il est toujours en place.
- Les sites doivent être compatibles mobiles, selon les critères de Google. Il ne concerne que les recherches effectuées sur des appareils mobiles (smartphones).
- L'impact se situe page par page : si une page est compatible mobile, elle sera favorisée dans les recherches mobiles alors que les pages incompatibles auront un handicap en termes de positionnement.
- L'algo fonctionne en continu : à chaque fois que Googlebot crawle une page, il teste si elle est compatible mobile
- En savoir plus : rendre son site compatible mobile pour Google.
Ce n'est pas un algo, mais c'est assez important pour être indiqué ici : Google passe son index en mobile-first. Jusqu'à présent, Google évaluait les pages à partir de leur version desktop, même pour le classement sur mobile (à part le bonus mobile friendly). Avec ce changement, Google évalue les pages à partir de leur version mobile, même pour le classement sur desktop.
9 BERT
- Cet algo a été officialisé en octobre 2019, en place à cette époque seulement aux USA pour les requêtes en anglais. Il a été déployé le 10 décembre 2019 dans 70 langues dont le français. Il est donc en place sur Google France.
- Il s'agit d'un algorithme de traitement du langage naturel à base d'IA (machine learning) visant à mieux comprendre les contenus (pages indexées) ainsi que certains types de requêtes. BERT est particulièrement efficace pour les requêtes longues, conversationnelles, grâce à une analyse bidirectionnelle des liaisons entre les mots (le rôle des prépositions est mieux pris en compte).
- Même si techniquement les méthodes employées sont très différentes, il peut être considéré comme une suite de RankBrain (et de Hummingbird)
- En savoir plus : l'algo BERT de Google
10 RankBrain
- Cet algo a été officialisé en octobre 2015 mais est en place depuis début 2015
- Il s'agit d'un algorithme utilisant des techniques d'intelligence artificielle, notamment l'apprentissage automatique (machine learning) pour tenter de mieux répondre aux requêtes complexes des internautes. En particulier, il est adapté pour répondre aux requêtes qui n'avaient jamais été faites auparavant (il y en a environ 15% chaque jour tout de même).
- Il ne s'agit pas d'un algorithme qui pénalise ou favorise certains types de contenus ou pratiques SEO. Il est donc plus à rapprocher de Hummingbird que de Panda ou Pingouin. Selon Google, il n'est pas possible d'optimiser pour RankBrain...
- En savoir plus : l'algo RankBrain de Google
11 Hummingbird (Colibri)
- Cet algo a été officialisé en septembre 2013
- Il ne cherche pas à pénaliser ou favoriser certains cas de figure ; il s'agit de la plus importante refonte de l'algorithme de classement de Google. L'objectif est de mieux comprendre aussi bien les contenus indexés que la requête de l'internaute (notamment formulée par oral, pratique en hausse avec le mobile). C'est l'avènement de la recherche sémantique.
- En savoir plus : algo Google Hummingbird
12 Pigeon et Possum
- Cet algo est sorti en juillet 2014 (pour google.com en anglais) et fin mai début juin 2015 à l'international
- Il s'agit d'une mise à jour de l'algorithme de classement des résultats locaux
- Il concerne tous les pays et toutes les langues (depuis fin mai début juin 2015)
- Une évolution de cet algo semble avoir eu lieu vers septembre 2016 : dans le monde SEO, on l'a appelée Opossum (ou Possum en anglais)
- En savoir plus : Google Pigeon, l'algo local
13 Publicité interstitielle intrusive
- Google cherche à pénaliser les cas où trop de pop-up ou bannières interstitielles sont intrusives, c'est-à-dire qu'elle gêne la lecture du contenu
- Sorti le 10 janvier 2017
- L'impact se situe page par page, sachant que cela ne concerne que la première page vue, uniquement par un visiteur arrivant sur le site depuis une recherche Google
- Remarque : ce n'est pas forcément un "algo", ni une "pénalité" puisque c'est tout de même algorithmique
- En savoir plus : publicité interstitielle intrusive
14 Pages satellites
- Cet algo a été annoncé en mars 2015 et mis en ligne entre mars et début mai 2015
- Il cherche à pénaliser les pages satellite, c'est-à-dire créées uniquement pour le SEO, en général à très faible contenu ou à contenu quasi dupliqué. Il vise aussi les techniques de sites satellites.
- On ne sait pas si l'impact est au niveau site ou page, ni si l'algo est mis à jour en temps réel, régulièrement ou seulement à certaines dates
- En savoir plus : update Google contre les pages satellites
15 HTTPS
- Cet algo a été officialisé en août 2014
- Il favorise les pages qui utilisent le protocole HTTPS
- Il est appliqué partout dans le monde (tous pays et langues)
- L'impact se situe page par page mais il est très faible
- En savoir plus : impact du HTTPS en SEO et passer à HTTPS
16 Indexation d'applications mobiles (App Indexing)
- Cet algo a été officialisé en février 2015 (source)
- Il favorise les pages web associées à un lien profond vers un "écran" d'une appli mobile (mécanisme de l'App Indexing)
- Si vous utilisez aussi l'API App Indexing, vous avez un avantage supplémentaire en positionnement
- En plus du "ranking", l'avantage se situe dans l'affichage prépondérant dans les SERP (il y a plusieurs possibilités, mais votre "snippet" est bien plus visible)
- Il est a priori appliqué partout dans le monde (tous pays et langues), pour l'instant uniquement sur mobiles Android
17 Excès de publicité
- Cet algo a été officialisé en janvier 2012. La dernière version est la version 3 qui date du 6 février 2014.
- Il cherche à pénaliser la surdose de publicité, notamment au-dessus de la ligne de flottaison (on parle de "ads above the fold" ou "top heavy")
- Je pense que Google se base sur des analyses de l'ensemble du site : il faut donc éviter d'avoir trop de pages sur le site avec trop de pub
- En savoir plus : algo Google contre l'excès de pub
18 Articles de fond (in-depth articles)
- Cet algo date d'août 2013
- Il fait parfois apparaître dans les résultats une sorte d'encadré avec des articles de fond mis en évidence
19 Exact Match Domain (EMD)
- Cet algo date de septembre 2012
- Il cherche à pénaliser les sites dont le nom de domaine est constitué exclusivement de mots-clés et dont la valeur ajoutée est très faible
- En savoir plus : algo Google contre les EMD
20 Fraîcheur
- Cet algo date de novembre 2011
- Il vise à afficher des résultats plus frais et plus récents sur les requêtes qui le nécessitent
- En savoir plus : algo Google Freshness
21 Pirate / DMCA Update
- Cet algo est d'abord sorti en août 2012, la version 2 en novembre 2014
- Il vise à faire disparaitre des résultats les sites qui proposent le téléchargement illégal
- En savoir plus : algo Google DMCA 2
22 Payday loan
- Cet algo est d'abord sorti en 2012. La dernière version (v3) date de juin 2014
- Il cherche à améliorer la qualité des résultats spécialement sur certaines requêtes où le spam est important (crédits, casino, sexe, contrefaçon, etc.).
- Pour ceux que ça intéresse, j’ai trouvé la traduction de « payday loan » qui signifie « une avance de fonds à court terme accordée par une société de crédit ».
Encore une fois, je compte sur vous pour me signaler les oublis ou manques de mises à jour !
Les 8 points-clés d'un bon référencement naturel sur Google
Rand Fishkin (fondateur de Moz) a publié une très bonne synthèse du SEO sur Google, dont voici un extrait...
Optimiser son site pour les "SERP Features"
D'abord, il rappelle que le référencement naturel ne consiste plus (seulement) à se battre pour être dans les 10 premiers résultats traditionnels. En effet, les SERP ont totalement changé en quelques années, on est désormais loin des classiques "10 liens bleus" : il existe de multiples blocs affichés dans les pages de résultats.
Voici selon lui les 16 principales pour les référenceurs :
- vidéos
- Autres questions posées (People Also Ask)
- Featured Snippet
- carte locale
- Knowledge Panel
- bloc "A la une" (actu)
- images
- applications mobiles
- Livres
- Recherches associées
- Tweets
- Suggestions de recherches (autocomplétion)
- Sitelinks
- Sitelinks pour une page
- Articles de fond (In-Depth Articles)
- Carrousels et listes de résultats
Ensuite, concernant ces traditionnels résultats (pages web), voici selon lui les 8 points-clés d'un bon référencement :
1 Contenu
Votre contenu doit bien correspondre à ce qui est attendu par les systèmes de Google (basés sur le machine learning).
Il doit être pertinent, de haute qualité et répondre précisément à l'intention de l'internaute.
2 Liens
Vous devez obtenir des liens éditoriaux (placés au coeur du contenu), avec des textes de liens contenant des mots-clés (anchor text). Attention à ne pas en faire trop à ce niveau.
Ces liens doivent être "follow" (c'est-à-dire qu'ils ne doivent pas être nofollow... sinon ils ne vous aident pas, à part vous générer du trafic).
Ils doivent provenir de sites de grande qualité.
3 Satisfaction utilisateur
Si Google observe un fort taux de retour dans les SERP (après une visite rapide de votre site), ou d'autres signaux qui traduisent le fait que votre page/site ne fournit pas la réponse cherchée par l'internaute, alors vous risquez de voir votre positionnement baisser.
4 Mots-clés
Même si Google cherche les pages qui répondent globalement à la demande de l'internaute, parfois avec d'autres mots, il reste utile d'utiliser les bons mots-clés. C'est bon pour le positionnement ainsi que pour favoriser un bon taux de clic dans les SERP. On peut chercher les mots-clés avec une regex dans Google Search Console.
5 Qualité du nom de domaine
Tous les critères de qualité sur votre site sont amplifiés par l'évaluation globale du nom de domaine.
Un domaine "puissant" donne un boost à ses pages qui peuvent être mieux positionnées.
Comme vous l'avez compris, le boost dépend de la (bonne) notoriété du nom de domaine, et n'est présent que si les pages remplissent elles-mêmes les critères pour un bon positionnement.
6 Expérience utilisateur
Google souhaite promouvoir des sites avec une expérience utilisateur (UX) facile à utiliser et intuitive, sans aucun obstacle.
Evidemment, ceci doit être vrai quel que soit l'appareil (fixe et mobile) et la vitesse de connexion.
7 Technique et crawl
Vos pages doivent être crawlables (accessibles à Google) et rapides ! Vérifiez vos stats d'exploration dans Search Console.
Elles doivent contenir du texte et être accessibles par des liens HTML.
8 Personnalisation
Les résultats Google sont personnalisés ! Il peut y avoir de grosses différences possibles dépendant du lieu géographique de l'internaute, de son appareil, de son historique de recherches et de l'heure.
Comment fonctionne l'algo de Google
Udi Manber, membre de l'équipe Search Quality dirigée par Amit Singhal chez Google, a expliqué sur le blog officiel de Google comment les équipes sont organisées chez Google pour gérer le coeur du moteur, à savoir la recherche : algorithme de positionnement, évaluation de la qualité des résultats, interface utilisateur, gestion internationale, lutte contre le spam...

Estimant que le travail de l'équipe Qualité chez Google n'est pas assez connu des utilisateurs du célèbre moteur de recherche, Udi Manber a décidé de donner quelques explications sur leur fonctionnement. Voici un petit résumé des différentes équipes décrites par Udi, avec quelques commentaires...
Equipes en charge de l'algorithme de classement de Google
Créer un algorithme d'analyse de la pertinence des pages en fonction des requêtes des internautes est bien plus difficile qu'il n'y parait. D'une part il y a énormément de façon de présenter les choses sur une page (cela diffère notamment selon les langues) ; d'autre part il est souvent difficile de deviner ce que cherche réellement l'internaute au travers de sa requête (parfois formulée de façon imprécise ou ambigüe). L'élaboration de cet algorithme est donc une tâche complexe qui doit tenir compte d'une contrainte forte : l'utilisateur doit obtenir une réponse en quelques millisecondes, même s'il y a plusieurs centaines de millions de requêtes effectuées par jour sur Google !
La partie la plus populaire de l'algorithme est le PageRank (NDLR : car il fut un élément clé du lancement de Google, également car il fut décrit à l'origine par une formule précise dans un article public et enfin car les webmasters ont cru pouvoir le mesurer par l'estimation fournie dans la barre d'outils de Google). Le PageRank est toujours utilisé par Google, mais d'une part sa formule a changé (le dernier changement remonte à Janvier 2008) et d'autre part le PageRank est noyé
au milieu d'un grand nombre d'autres critères utilisés par Google. Udi cite aussi la modélisation de chaque langue et les aspects temporels (il confirme ce qu'on pensait : pour certaines requêtes traitant par exemple de l'actualité, Google met en avant des pages mises en ligne depuis très peu de temps).
Equipes en charge de l'évaluation de la qualité des résultats de Google
Il y a plusieurs types d'évaluation :
- évaluation automatique faite chaque minute, pour être sûr que tout fonctionne normalement
- évaluations manuelles faites régulièrement par l'équipe qualité
- évaluations de chaque nouvel algorithme introduit sur Google : en 2007, environ 450 modifications ou ajouts ont été apportés à l'algorithme de Google (NDLR : ceci concerne peut-être tous les services de Google, pas seulement la recherche classique)
- évaluations faites par des volontaires chez Google pour ce qui concerne les très nombreuses langues gérées par le moteur de recherche
Equipes en charge de l'interface utilisateur
Google essaie d'améliorer l'expérience utilisateur en introduisant des nouveautés dans l'interface. De nombreuses personnes analysent tous les détails pour s'assurer que ces changements sont appréciés des internautes. On imagine qu'il y a eu ainsi de très nombreux tests depuis le lancement de la recherche universelle, qui a radicalement changé l'apparence des pages de résultats.
Equipes en charge de la lutte contre le spamdexing
Sans doute plus connue des webmasters et de tous ceux qui s'intéressent au référencement, l'équipe menée par Matt Cutts est chargée de lutter contre le spam chez Google. Les ingénieurs essaient de détecter les nouvelles tendances afin de trouver des parades (algorithmiques dans la majorité des cas). Ils sont en dialogue avec l'équipe de Webmaster Central qui a pour objectif de communiquer avec les webmasters du monde entier.
Matt Cutts rappelle qu'il n'est pas à la tête du Search Quality chez Google mais de l'entité qui lutte contre le spamdexing :
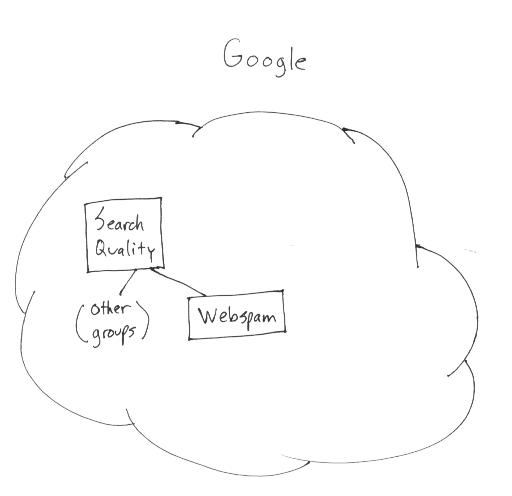
On n'apprend pas tant de choses que ça mais il ne fallait pas rêver, l'algorithme de Google c'est leurs bijoux de famille
, une formule magique dont la valeur marchande se chiffre sans doute en milliards de dollars... Espérons que les prochains articles promis par Udi Manber nous en apprendront plus sur les entrailles de Google !
Infographie : comment fonctionne Google (le moteur de recherche) ?
Je termine par une infographie que je trouve bien faite, publiée par seobook.com :
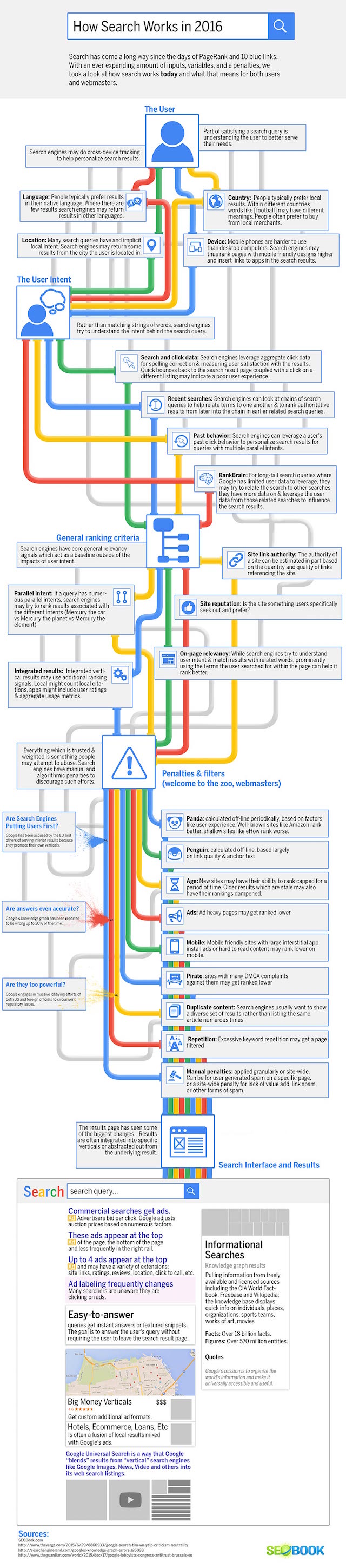
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Merci pour cet article très intéressant !
Bonjour Olivier,
Est-ce que les algorithmes de Google s'appliquent aux sites des services de Google ?
Parce que quand on est en compétition avec ces sites, on voit régulièrement des fluctuations du genre notre site monte de façon régulière via les algorithmes jusqu'à dépasser certaines des URL de Google et arriver en 2e position, puis boum d'un seul coup toutes les URL de Google repassent à nouveau devant et rebelote...
En même temps, je ne pense pas que Google communique sur la façon dont il favorise ses propres URL... Mais ton avis serait intéressant sur cette possible tricherie.
Désolé François, je n'en ai aucune idée. On voit bien que Google abuse en mettant en avant ses services dans les SERP, mais est-ce aussi le cas dans la partie des liens naturels, je ne sais pas.
Je trouve que le référencement de google devient de plus en plus n'importe quoi. Il est opaque sur plein de choses. Il y a plein de sites qui ne respectent pas les dits principes de Google et qui sont quand même bien référencés. Je trouve cela totalement déloyal. Pour moi, Google mets un temps de dingue pour réanalyser les pages... Il dit être rapide mais ce n'est pas vrai. Il n'explique pas clairement les problèmatiques de chaque site.... Ces consignes ne servent à rien parce qu'ils ne les appliquent pas...
C'est vrai que certains updates sont étranges, la dose d'IA génère parfois des trucs incontrôlés sans doute.
Sinon, quels principes de Google ne sont pas respectés sans que cela pose pb ?
Merci Olivier pour la qualité de cet article. Il y a un gros boulot de recherche de votre part. Bravo
ce que vous avez dit, ca n'ajoute rien de plus à ce qu'on dit depuis au moins 2016 :(
Bonjour,
Il y a 72 heures, nous sommes le 27 septembre 2019, Google a mis à jour l’un de ces algorithmes.
Jusqu’à il y a trois jours mon site était très bien classé. Depuis 48 heures il était excellemment bien placé.
Depuis ce matin, mon site semble ne plus apparaître sur la toile!
Dois-je m’inquiéter, ou seulement être patient et attendre que le déploiement soit terminé d’ici à quelques jours?
Merci de votre aide. Bonne journée.
C'est impossible à dire, mais ça peut encore bouger dans les jours à venir.
Le mieux serait d'ouvrir une discussion dans le forum en indiquant l'URL du site, pour demander de l'aide à tous les membres.
L algorithme de google est connu et pas caché c est comme la recette de coca cola elle est public, c est pas la recette qu il faut connaitre justement ils s en foutent totalement que les gens la connaissent ou pas c est la méthode qui n est pas connue, maniere de faire, étape à respecter, tant de cuisson, etc etc google c est exactement pareil, l algorithme est connu, mais c est pas l algorithme qui est important c est la manière dont c est mis en place... d ailleurs le 99% des referenceurs ne savent même pas comment fonctionne l algo de base alors comment veux tu faire avancer une voiture si tu connais pas l essence dont elle a besoin... ca me fait rire tous ceux qui se prennent pour des pros et toutes ces agences de comm qui te racontent que de la merde et qui ne connaissent mm pas les fondations de google mdrr
Je viens de comprendre d'une manière plus que claire les raisons pour lesquelles le trafic sur mon blog à presque quadrupler du jour au lendemain en mois de avril 2019.
Assurer un bon référencement à son site devient compliquer encore et encore.
Ces genres d'articles sont les bienvenus car ils nous permettrons de suivre ce que google cache. Merci bien
article intéressant même si je partage absolument pas certaines choses ;-)
Faut pas hésiter à détailler lesquelles !
Désolé oliv pas vu que tu avais répondu, google panda et pingouin ne font pas parti de l algo principal, ce sont des bécanes totalement à part... par contre oui c est du temps réel maintenant... mais dans quasiment tous tes articles tu expliques que c est du tout en un... je partage pas cette info ;-) et il y un algo principal avec ces 400 fameux critères (environs) dont la moitié public et l autre qui ne diront jamais mais qui est pas du tout compliquée à savoir si tu étudies le ref avec des ingénieurs, c est ce que j ai fais pendant 3 ans... donc si vous avec des questions hésitez pas, il y a bien sur des choses dont je pourrais pas parler... mais bcp ou je pourrais aider aussi...
"il doit y avoir beaucoup d’effets de bord incontrôlés…"
Oui.
Artiste (Le délesteur) je suis censuré depuis le 16 mars par Google qui a retiré tout mon contenu artistique de son Réseau de Recherche Google.
Du jour au lendemain, je me trouve sans ressources, et dans l'impossibilité de continuer mon activité.
Pour quel motif ? Publication de contenu vide de sens.
A cela je réponds coupable, car c'est mon métier.
Google considère que je pollue son moteur de recherche et va à l'encontre de l'idéologie de Google qui est de procurer la Meilleure Expérience Utilisateur Possible (MEUP) décrite dans la bible du webmaster.
Pour beaucoup, la censure n'est qu'un problème technique qu'une bonne agence de SEO peut résoudre. Mais que faire lorsque les algorithmes de Google deviennent de plus en plus froid et implacables, sans intelligence, sans capacité à connaitre l'art ou reconnaitre l'humour.
Google nous dresse un univers effroyable, dont seuls les sites capables de payer un référencement, acheter des logiciels d'optimisation, etc sont présents et l'écriture "technique" et non plus artistique et libre domine.
Ma censure, et mon bannissement, personne ne le comprend, même chez Google, quand bien même la décision est humaine au finale.
Mon seule recours, un lettre que j'ai écrite à l'algorithme de Google :
▪️Lettre à Google.
- .Je suis peut-être le premier Artiste que vous censurez et certainement pas le dernier.
Je suis coupable d’utiliser des techniques artistiques, qui sont contraires à votre philosophie basée sur la ́ . (MEUP)
Artiste, vous m’avez censuré le 16 mars 2019.
Je me trouve banni de votre Réseau de Recherche.
Du jour au lendemain et avec une violence inouïe, ma famille et moi sommes sans ressources et je suis dans l’impossibilité de travailler.
Cette censure, vous l’avez provoquée.
Vous avez demandé à un humain de la valider.
Cette censure nous montre-t-telle votre limite dans votre capacité à interpréter notre univers ?
Il me semble que vous avez un choix à faire.
Vous ne connaissez ni l’humour ni ne reconnaissez l’Art.
Vous êtes froid et implacable.
Le plus effrayant c’est que vous considérez la censure comme le résultat d’un simple problème « technique de non conformité» qu’une bonne agence de référencement SEO peut facilement résoudre.
Les agences de référencement sont devenues vos chiens de garde au nom de « ́ » ?
Vous m’avez qualifié de SPAM AGRESSIF, et me reprochez de publier «techniquement » du contenu vide de sens.A cela je réponds COUPABLE.
Publier du contenu vide de sens, c’est même mon métier.J’utilise Cell-ion un robot qui quotidiennement va publier « MERDE ! », C’est vide de sens et contraire à votre idéologie.
Pardon.
Je fais cela pour être le numéro UN de la Merde.
C’est vide de sens et contraire à votre idéologie.
Pardon.Vous n’hésitez d’ailleurs pas à me le rappeler dans les « consignes au webmaster » que j’ai lu comme une bible.
J’ai lu que vous interdisez le recours à des robots qui publient du contenu vide de sens.Sous couvert des règles algorithmiques qui véhiculent « ́ » vous avez résolu mon problème de choisir, car vous calculez systématiquement le meilleur choix pour moi, à partir de nous.
Vous maximisez notre ́ et je vous en remercie.
Vous m’avez censuré d’un monde virtuel, et peut être ne voyez-vous pas l’impact dans le monde réel, même si vous en faites disparaître progressivement la frontière.Je réponds donc coupable à votre acte d’accusation. Coupable d’avoir empêché et pollué La ́
Vous m’avez mis en prison, vous m’avez délivré…
Laissez moi revenir en prison.
Le Délesteur.
Il n’y a pas 1 mais de multiples algorithmes Google?
Un algorithme ne se fait pas forcement en une et une seule étapes, il peut y en avoir plusieurs.
Celui-ci peut agir à des endroits, à des moments différents.
Tel que l'ordinateur de l’internaute.
Le but d'un algorithme est de traiter les données afin d'obtenir un résultat final. C'est la définition même d'un algorithme.
Données initiales: Pages des site web => données finales: les résultats présentés à l’internaute.
Tout ce qu'il y a entre les deux, ne sont que des étapes.
C'est plutôt de dire qu'il y en a plusieurs qui est une faute, par abus de langage, nous disons l’algorithme Panda, l'algorithme Penguin. Ce ne sont que des étapes de l’algorithme
Merci pour ces précisions de vocabulaire !
Merci pour cet article très clair et à jour :) Un bon récapitulatif !
C'est Fred qui m'intrigue le plus, et la réintroduction de la valeur globale du site sous un autre nom.
Les suites de Fred, bien que sans nom attribué, ce sont les mises à jour "globales" de l'algo comme celle du 1er août 2018.
Je n'ai pas compris la partie "la réintroduction de la valeur globale du site sous un autre nom", ça signifie quoi ?
Waaouw un trés bon article et bien détaillé. Merci
Superbe article Olivier, Bravooo, tout les jours il me faut ma dose sur WebRankInfo :)
Excellent article, je pense qu'Olivier Duffez est un des meilleurs si ce n'est le meilleur spécialiste SEO en France.
Merci Jean-Pierre pour le compliment :-)
@Jean-Pierre Mercier tu as raison de le signaler. Pour moi qui le suis depuis la création de WRI c'est le patron des patrons de toute la communauté francophone mondial !
Merci Monsieur Olivier Duffez ! Surtout pour vos mise à jour des articles, c'est pro.
Il y a beaucoup d'erreurs à cause de la complexité des algos google, exemple de problème récurent : avec blog de poids lourd et blog de camion sur une recherche google ; ça grouille de blog skyrock sans intérêt... Je suis un petit pro, mais je suis aussi un utilisateur, et franchement, les résultats google laissent à désirer en ce moment...
Avec toute la sympathie que j ai pour olivier, c est certainement le plus populaire oui et tres bon et pro dans son métier, mais pas le meilleur :-)... j ai bosse avec des ingénieurs capables de calculer l impact d un lien social dans d une page web dans les serps grâce à des boîtiers électroniques branches sur ta ligne internet, tu imagines pas 2sec le niveau qui faut avoir pour mettre en place ca... referenceur c est un métier, pas un passe temps, le problème de ce métier, c est qu il y a trop d incompétents, de nos jours tu mets un BL et tu te dis referenceur lol... dans quelques années seuls les personnes qui ont piges certaines choses resteront en tete de liste et je te garanti que c est pas bcp de monde et si tu veux un ptit scoop si google devait vraiment mettre en place et en ligne toutes ces directives, il y aurait plus personne sur son répertoire (façon de parler) donc soyez content que google tourne pas plus le robinet... car absolument tous les postes que je lis sont à côté de la plaque tout simplement parce que les gens n ont pas compris la base de google... bref, olivier = bon referenceur, maintenant ceux qui faut côtoyée ce sont les (vrais experts) ce sont des ingénieurs en math et non des referenceurs d ailleurs... et vous les trouverez pas sur le web, ne perdez pas votre temps à les chercher :-)
Merci pour ton point de vue Visaboy :-)
Tu me reproches de dire que Panda fait partie de l'algo principal alors que c'est + proche d'un pb de vocabulaire que d'autre chose... Et de l'autre côté tu me parles d'une liste de 400 critères (ce nombre sort d'un chapeau), dont "la moitié sont connus" (là aussi c'est mystérieux et tout sauf scientifique).
Ce dossier sert à faire comprendre les principaux axes suivis par les ingénieurs de Google pour leur algo.
Tiens, au passage, je suis ingénieur ;-)
Coucou olivier, attention aucun reproche, je suis personne pour reprocher à qui que ce soit qqch... je t expliquais juste que ce sont trois choses totalement différentes et séparées mais qui ont un seul et meme but, satisfaire l internaute, ca c est pour le résultat, car sur le process c est pas pareil, algo de base, il classe, panda gere la qualité et pingouin, liens internes (maillage) et les BL externe... c est vraiment 3 choses séparées qui comme je le dit plus haut on en effet le but ultime de proposer aux clients de google la meilleure page. Donc, étant ingénieur tu dois le savoir ca, mais sur plusieurs post, tu expliques que maintenant panda et pingouin sont inclus dans l algo principal... alors que pas du tout... pourquoi 400 ? Ce chiffre tombe pas du ciel en effet, si tu veux en savoir plus contact moi par email, je pourrais parler de choses plus techniques et plus précises car en effet c est pas le but ici.
merci mais une question demeure pour moi: à quelle fréquence moyenne passent ces algo ? Faut il compter en jours, semaines ou mois pour etre sur que son site ait ete scanné par tous ces algos ?
merci
certains algos se mettent à jour à chaque fois que le crawler passe sur une page, d'autres ont besoin d'infos sur un site entier, d'autres ne sont mis à jour par Google que de temps en temps...
et les fréquences de crawl sont variables selon les sites
bref, impossible de répondre à la question
de même qu'on ne peut pas savoir combien d'algos de Google concernent un site en particulier
Excellent article, on viens de se manger une maj apparemment dixit gwt 19.12.2016, des infos ?
Merci,
f.
Peux-tu créer une discussion dans le forum STP ? ça sera + efficace, merci !
Bonjour
Je lis ce jour une News concernant un algorithme nommé Oppossum basé sur lgoogle Maps !?!
en effet, c'est le nom d'une mise à jour non officielle de l'algo local de Google
Bonjour,
Merci pour cet article, très simple, ultra didactique
"Le SEO pour les nuls" en gros!
Bonjour, je viens de lire votre article sur les algorithmes de Google et j'ai appris beaucoup de choses. Cela va me servir pour mon boulot et évidemment améliorer mon site tant sur la vitesse que sur la qualité du contenu et un bon traitement de mots-clés. Merci à vous pour cet article que j'ai partagé bien entendu. Crithèrement Vôtre.
Merci beaucoup pour votre réponse Olivier.
Je suis d'accord avec vous, l'expérience utilisateur c'est très important ! Et la vitesse d'un site est un critère qui est important pour les internautes.
Personnellement, je continuerai pendant longtemps d'optimiser le poids des pages de mon site ;)
Encore merci pour votre réponse.
Bonjour Olivier,
Je vous remercie pour toutes les informations que vous nous faites parvenir sur votre site. C'est vraiment très utile :)
J'aurais toutefois une petite question concernant l’algorithme "Vitesse". J'ai parlé récemment avec une personne qui travail pour un site qui parle de SEO et cette personne m'affirme que le temps de chargement d'un site n'a aucun impact sur le SEO :O
Personnellement je suis très sceptique par rapport à cette remarque. Qu'en pensez-vous de votre côté ?
Merci par avance :)
aucun impact, je ne suis pas d'accord. Comment le quantifier et le prouver, c'est + dur, comme pour tous les critères SEO aujourd'hui
améliorer l'expérience utilisateur est un must, y compris pour l'impact SEO
Il existe une différence entre pingouin et manchot :
http://manchots.com/differences-entre-manchots-et-pingouins/
Voilà, c'était la minute vocabulaire du jour...
Super cet article récapitulatif ! Merci ;-)
En effet, beaucoup disent "pingouin" haha !
La distinction pingouin/manchot n'existe qu'en français.
Voilà voilà, c'était la minute vocabulaire du jour...
Merci pour cette précision !!
Il en manque 1 :
Random ()...
Je plaisante, mais peut-être pas tant que cela ;-)
merci pour l'article - clair et intéressant ! C'est une des bases pour être à jour pour le SEO !
PS
Penguin, Pingouin ou Manchot c'est ne pas vraiment important - c'est l'effet de l'algo !!!
C'est exactement ce qu'il me fallait.
Merci :)
Et comme ca on comprend bien ;)
tout le monde ne parle pas anglais
merci pour ces articles fort intéressant !!!
Penguin = Manchot, pas Pingouin!
Pingouin c'est Auk en anglais.
oui je sais bien effisk, mais 1- tout le monde dit ça et 2- on passe déjà assez pour des c..s alors avec manchot ce serait pire :-)
Il y a donc des évaluations manuelles, et des évaluations faites par des volontaires, heureusement je pense en même temps l'humain a aussi ses travers, mais je ne vois pas comment on pourrait faire sans le mixe des deux.
Google comprend bien qu'il lui faut protéger son algorythme.C'est un peu surprenant de voir qu'il y'a des gens qui s'attendent à ce que le moteur dévoile les infos sur ce qui fait son succés.Je suis d'accord avec Gif du bon contenu et de la patience finira tjrs par payer.
Salut, tu dis que : "l'algorithme de Google c'est leurs bijoux de famille, une formule magique dont la valeur marchande se chiffre sans doute en milliards de dollars". Pour ma part, je ne suis pas loin de penser que l'algorithme de google vaut beaucoup moins que son parc informatique, son système de fichiers et tous les éléments qui font le lien entre l'algorithme en lui-même et les système de requettage qui permettent d'aller chercher les résultats dans les data-centers ;)
C'est intéressant comme information (même si c'est assez généraliste) pour mieux comprendre comment fonctionne Google et l'esprit d'équipe qui est dans l'entreprise.